【语义分割】Paper-Reading PointRend
文章:PointRend: Image Segmentation as Rendering(CVPR2020
先看了 https://zhuanlan.zhihu.com/p/98351269
official code: https:// github.com/facebookresearch/detectron2/ tree/master/projects/PointRend
这篇文章的中心思想是将图像分割问题转化为一个渲染问题;那么解决什么样的问题呢,看下面这张图应该能明白:

MaskRCNN中的下采样使得最后只能得到一张28*28的mask,可以看到小红箭头指向的部位都是细节丢失的部分。再经过PointRend的层层渲染之后,不断细化,目标边缘逐渐流畅;
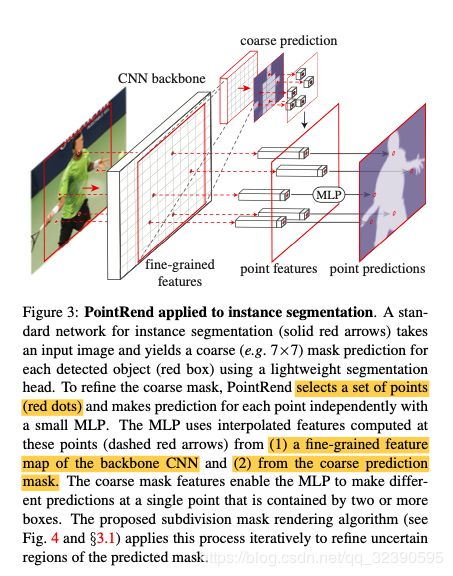
PointRend接收CNN提取的feature map,输出一个高分辨率的预测图。PointRend只是对一些特定选取的点来进行预测,首先通过插值来得到一个point-wise的特征展示,再使用一个小的point head subnetwork来从刚刚的point-wise特征中预测输出标签。接下来将会仔细介绍。
一个PointRend Module有三个主要部分:
1.A point selection strategy;为了避免过量的计算量,pointRend只是对一小部分的点选取进行计算;
2.对于每个选择的点提取a point-wise feature representation;
3.A point head:一个小的神经网络用于从point-wise feature representation来预测标签;(对于每个点来说都是独立的)
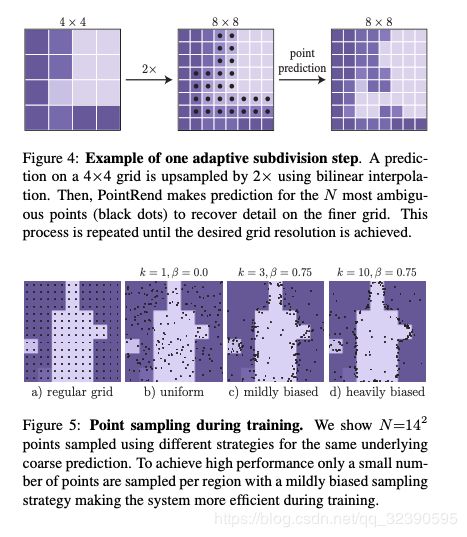
对于Point Selection,train与inference是由一些区别的,具体可以看文章中的描述;(train中还会选一些随机点啊作为generation等)在inference中则是选取N个最不确定的点(可能性接近0.5的点)对于每个点计算 point-wise feature representation以及预测标签;上面的步骤会在分割达到想要的分辨率之前重复。
接下来就是刚刚没有具体解释的a point-wise feature representation;它由两部分组成:
1.Fine-grained feature(细颗粒的特征来解决细节问题 (类似于ROI align利用双线性插值
2.Coarse Prediction features
为什么需要coarse prediction features?首先对于实例分割,一个点可能属于多个bounding box,所以这个点对于不同的bounding box的feature不能是相同的,咱需要region-specific 的feature;对于语义分割与实例分割共同而言,fine-grained的low-level feature是远远不够的;
Point Head:
使用一个简单的multi-layer perceptron (MLP)来对a point-wise feature representation得到point-wise的预测结果;
因为是语义分割学习,所以主要来看看语义分割的结果:

使用deeplabv3作为decoder,PointRend有miou的提升,使用空洞卷积得到更好的miou,但是计算量和空间都有较多的开销,作者认为还是使用pointrend更好;