深度学习模型评估指标(区分二元分类和多分类 含YOLO源码分析):accuracy、precision、recall
深度学习模型评估指标:accuracy、precision、recall
- 1. 准确率(accuracy)、精确率(precision)、召回率(recall)
- 1.1基本概念
- 1.2二元分类模型的定义
- 1.3多分类模型的定义
- 1.4举例说明
- 1.5 YOLOv3中recall的计算
- 2. 关于精确率和召回率的关系
1. 准确率(accuracy)、精确率(precision)、召回率(recall)
1.1基本概念
准确率(accuracy)、精确率(precision)、召回率(recall)三个指标的定义是有一定条件的,严格意义上讲应该说某类型目标在某种分类模型下的accuracy、precision及recall。关于这三个指标概念如下:
accuracy:所有类型检测结果中,检测正确的目标比例。
precision:所有检测出来的目标A中,真实为目标A的比率,换个词来说可以叫查准率。
recall:真实为目标A中,检测出是A的比率,换个词来说可以叫查全率。
前面说了三个指标的条件,关于针对某类型目标很容易理解,在某种分类模型下什么意思呢?
1.2二元分类模型的定义
先说二元分类,即使用sigmoid函数,那么我们可以按照常见博文里面的描述和计算方法,将二目标任务的检测对象划分为正样本(positive)和负样本(negative),对于多目标任务,当前检测的目标为正样本,其他目标都是负样本,检测结果可以表示为 T P TP TP 、 F P FP FP 、 T N TN TN 、 F N FN FN 类,T表示Truth,F表示False,具体定义如下:
T P TP TP:检测为正样本,且真实为正样本的目标数量;即正确检测到的目标A数量。
F P FP FP:检测为正样本,但真实为负样本的目标数量;即目标A错误检测成其他目标的数量。
T N TN TN:检测为负样本,且真实为负样本的目标数量;即其他目标错误检测成目标A的数量。
F N FN FN:检测为负样本,但真实为正样本的目标数量;即其他目标没有错误检测成目标A的数量。
然后,准确率:
a c c u r a c y = T P + T N T P + F P + T N + F N accuracy=\frac{TP+TN}{TP+FP+TN+FN} accuracy=TP+FP+TN+FNTP+TN
精确率: p r e c i s i o n = T P T P + F N precision=\frac{TP}{TP+FN} precision=TP+FNTP
召回率: r e c a l l = T P T P + F P recall=\frac{TP}{TP+FP} recall=TP+FPTP
在YOLOv3中,虽然可以检测到很多类,但是本质上使用的还是二元分类的方式,只要不是目标A,检测出来也不是目标A,统统可以归为TN;同时只要不是目标A,检测出来为目标A,才可以归为FN。当然,二元分类中也不可能让你把目标B、C精确检测成目标B、C。
1.3多分类模型的定义
对于多分类,即使用softmax函数,对于目标i,参考上面的描述和计算方法:将N个目标任务将所有检测结果标记为 T i ( j ) T_i(j) Ti(j), F i ( j ) F_i(j) Fi(j),T表示Truth,F表示False, i , j = 1 , 2 , . . . N i,j=1,2,...N i,j=1,2,...N具体定义如下:
T i ( j ) T_i(j) Ti(j), i = j i=j i=j:实际为目标i,正确检测为目标i数量。
F i ( j ) F_i(j) Fi(j), i ≠ j i≠j i=j:实际为目标j,错误检测为目标i数量。
然后,准确率:
a c c u r a c y = ∑ i , i = j T i ( j ) ∑ i , i = j T i ( j ) + ∑ i ∑ j , i ≠ j F i ( j ) accuracy=\frac{\sum_{i,i=j}{T_i(j)}}{\sum_{i,i=j}{T_i(j)}+\sum_{i}{\sum_{j,i≠j}{F_i(j)}}} accuracy=∑i,i=jTi(j)+∑i∑j,i=jFi(j)∑i,i=jTi(j)
精确率:
p r e c i s i o n ( j ) = T i , i = j ( j ) T i , i = j ( j ) + ∑ j , j ≠ i F i ( j ) precision(j)=\frac{T_{i,i=j}(j)}{T_{i,i=j}(j)+\sum_{j,j≠i}{F_i(j)}} precision(j)=Ti,i=j(j)+∑j,j=iFi(j)Ti,i=j(j)
召回率:
r e c a l l ( j ) = T i , i = j ( j ) T i , i = j ( j ) + F i , i ≠ j ( j ) recall(j)=\frac{T_{i,i=j}(j)}{T_{i,i=j}(j)+F_{i,i≠j(j)}} recall(j)=Ti,i=j(j)+Fi,i=j(j)Ti,i=j(j)
1.4举例说明
为了进一步说明这三个指标,我们举个例子。
假设有个鱼塘,共有鱼500只,虾300只,鳖200只。检测出来鱼500只(真实为鱼400,剩下50为虾,50为鳖),检测出虾250只(其中真实为鱼50,虾150只,剩下的50都是鳖),检测出鳖100只(其中真实为鱼30,虾60只,剩下的10都是鳖)。总共检测出来500+250+100=850个目标,检测出来的目标中,其中真实为鱼的480只,虾210只,鳖110只。
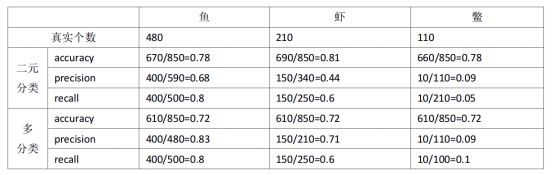
通过这个例子也可以证明,对于多分类模型只有一个accuracy,不再区分类别,因为一个分类模型(如softmax)把所有类型都分出来了,而无论是二分类还是多分类,recall都已一样的。当然,如果把类别降为两种,二分类不过是多分类的一个特例而已。
1.5 YOLOv3中recall的计算
第一件要说的前提是YOLOv3的分类是二元分类。
这些指标的计算,一种是训练的时候一般是计算一个batch的指标,另一种是验证集一般计算整个验证集的。通常一个验证集中的数据量可能就是一个或几个batch的数量,目标种类多需要验证集大一些,种类少就可以小一些。这些指标是一个用于分类评估的指标概念,实际评估的结果是对分类confidence使用分类阈值筛选后的结果。三个指标中通常我们更加关心precision和recall,这两个指标可以构建一个AP曲线,mAP就是不同类型AP曲线均值的均值,这个曲线可参见上一篇文章《深度学习模型评估指标:mAP计方法与voc_eval.py源码解读》中的说明。
一般mAP都是使用验证集检验模型效果,然后调整超参数或决定进行多少次训练。但是在YOLOv3的训练中呢?通过阅读源码,我们发现,训练时候在forward_yolo_layer对recall进行了计算。
估计主要是考虑到这个计算是用于给训练者提供一个粗略的评估参考,函数中并没有计算precision,只计算了recall,而且还没有分类,recall计算时是将所有的正确检测出来的值和一个子批次(batch/subdivisions)的检测结果和目标匹配的GT数量的比值。计算的recall分为recall.5和recall.75,分别表示IOU高于0.5和0.75时认为是正确检测时候的真值。下面我们对相关源码进行解析。
recall.5和recall.75在forward_yolo_layer的第二个循环中计算,通过找到每个尺度条件的GT在一个batch内进行累加,计算一个batch的GT位置上检测到的目标和GT的IOU分别在0.5和0.75时候的个数,通过相除来得到两个结果,相关源码及注释如下:
void forward_yolo_layer(const layer l, network net)
{
......略
float recall = 0;
float recall75 = 0;
int count = 0;
......略
for (b = 0; b < l.batch; ++b) {//一个子批次中有 l.batch = batch/subdivisions张图片,对图片一张一张进行处理
//循环1:主要完成box的delta计算。对于一张图片,获得最佳匹配的真目标,通过遍历feature map每个点,在对应点上遍历GT计算IOU,确定是否存在目标,然后计算l.delta[obj_index]
......略
//循环2:对于一张图片,在GT的位置,计算有检测到目标的confidence和class的delta,这是一个进行分类逻辑回归的循环
for(t = 0; t < l.max_boxes; ++t){
//*****第一步*****找最佳anchor,如果能找到,则可以累加计算出当前尺度中GT的个数*****//
//获取GT的box信息,变量truth是提取的一个GT的box信息,1为步长(x,y,w,h之间指针移动步长为1)
//GT的box信息的指针=所有GT的指针位置+图片序号×图片label文件最大读取的GT个数+一幅图内GT指针的位置
//net.truth是所有truth位置的起点,和voc_eval类似,都是先将所有的GT信息提取出来进行缓存
box truth = float_to_box(net.truth + t*(4 + 1) + b*l.truths, 1);
//当遍历完一幅图的GT,自动跳出,当真值个数高于l.max_boxes,则取90个
if(!truth.x) break;
float best_iou = 0;
int best_n = 0;
//GT对应的feature map中的位置,注意,label中的坐标点为归一化的点,便于在程序中比较
i = (truth.x * l.w);
j = (truth.y * l.h);
box truth_shift = truth;
truth_shift.x = truth_shift.y = 0;//anchor的坐标点归零
//在每个GT的位置,检验所有anchor,total为anchor的个数,l.total = 3,目标选出best_n
//l.biases的值为cfg文件中当前yolo层对应尺度anchors的宽高
for(n = 0; n < l.total; ++n){
box pred = {0};
pred.w = l.biases[2*n]/net.w;
pred.h = l.biases[2*n+1]/net.h;
float iou = box_iou(pred, truth_shift);
//找到最优的anchor序号n和相应的iou
if (iou > best_iou){
best_iou = iou;
best_n = n;
}
}
//*****第二步*****计算当前尺度GT在feature map对应位置上的检测结果和delta*****//
//挑一个真值和预选框近似的,三个尺度中每个尺度都有不同长宽的anchor,总有一款适合你
//在l.mask中,如果有和anchor序号相等的,返回mask的序号,没有的话返回-1
//在当前尺度的yolo层中,如果最佳anchor不在当前的l.mask中,跑到别的尺度anchor中返回-1
//同一个GT不可能落入相同的musk中,所有尺度的层能够对应所有的GT
int mask_n = int_index(l.mask, best_n, l.n);
//下面的操作都是针对每个真值位置上的
if(mask_n >= 0){
//box index落在了第几个目标块中,通过真值锁定,不可能出现一个真值在相同的位置的不同的目标快中都有标记
int box_index = entry_index(l, b, mask_n*l.w*l.h + j*l.w + i, 0);
//注意,这里是关键,delta_yolo_box,计算iou和delta,这里只计算box_index位置有没有目标,和真值差多少,及IOU
float iou = delta_yolo_box(truth, l.output, l.biases, best_n, box_index, i, j, l.w, l.h, net.w, net.h, l.delta, (2-truth.w*truth.h), l.w*l.h);
//返回目标点confidence的index
int obj_index = entry_index(l, b, mask_n*l.w*l.h + j*l.w + i, 4);
......略
++count;//当前尺度条件下GT目标的个数
++class_count;////目标class的个数,每运行一次加1,参与每个批次的大循环累加
if(iou > .5) recall += 1;//真值点检测出来目标iou>0.5的个数,所有真值中,检测到了,查漏
if(iou > .75) recall75 += 1;//真值点检测出来目标iou>0.75的个数,根据实际数据,>0.5容易,甚至可以达到0.9以上,>0.75不易
avg_iou += iou;//计算平均IOU
}
}
}
......略
printf("...... .5R: %f, .75R: %f, ......", ...... recall/count, recall75/count ......);
}
当训练到足够次数recall.5常常可以达到0.9以上,recall.75要差一点也能达到0.5以上。
2. 关于精确率和召回率的关系
很多解释中都说精确率和召回率是trade off的关系。首先需要注意检测的结果数最多就是总样本数。
第一种情况是希望提高召回率。利用检测为负样本的正样本是有限的,当扩大总样本量时,检测到的负样本中混杂的正样本(FN)增加到一定程度停止增加,而检测到的正样本中混杂的负样本(FP)会越来越多。FP增加会使precision减小,FN增加到一定成都停止增加,TP增加会使得recall不断增加。为啥说FN增加到一定程度停止增加,而FP会越来越多,因为正样本量还是比较少呗,要不然为啥费这么大的劲去检测识别?举个例子,100个人中3个癌症,97个健康,你的任务是识别癌症还是健康的,当然是癌症的了,癌症是正样本嘛。保证召回率的同时,提高精确度可以减少成本支出。
第二种情况是希望提高精确度。就是不考虑召回率,但保证每一次检测到的正样本尽可能都是你想要的,这经常应用于网页搜索、识图搜索等问题中,宁可返回“对不起,没有搜索到您需要的内容”,也不会给你提供一个错的,这时当精确率很高的时候,召回率就会很低,想想大量正确信息被屏蔽掉似乎有点可惜,但是这个样本池很大,漏检成本很低。
对于多目标分类其实是一样的道理,精确度和召回率的取舍看实际需求。当然更好的分类系统可以尽量兼顾二者,如何评价这个系统呢,可以使用F-measure值。
不卖关子上公式,令 P P P 表示precision, R R R 表示recall
加权调和平均数为F为
F = ( 1 + a 2 ) P ∗ R a 2 P + R F=\frac{(1+a^2)P*R}{a^2P+R} F=a2P+R(1+a2)P∗R
令 a = 1 a=1 a=1,可以得到
F 1 = 2 P ∗ R P + R F1=\frac{2P*R}{P+R} F1=P+R2P∗R
这个 F F F 叫做加权调和平均数, F 1 F1 F1 就叫调和平均数。调和平均数经常用于综合衡量周期不同、尺度不同甚至分布有所不同的几类数值的综合平均,如果使用普通的几何平均或者中位数往往难以反映两个指标的综合情况。在目标识别的条件下, P P P 和 R R R 表达方式不同甚至相互牵制,就采用了相比更加合适的调和平均数来衡量一个识别模型同时考虑 P P P 和 R R R 的效果。
类似的还有E值
E = 1 − 1 + b 2 b 2 P + 1 R E=1-\frac{1+b^2}{\frac{b^2}{P}+\frac{1}{R}} E=1−Pb2+R11+b2
b b b越大,精确率权重越大。当 b = 1 b=1 b=1,E1=1-F1。在目标检测中,F值和E值法使用的都不是很多,将来讨论到其他需要的模型再研究。