ORACLE 按时间创建分区表
有些项目中可能会涉及到表的分区(有的表大小在70G左右) 下面简单写一下创建分区表过程
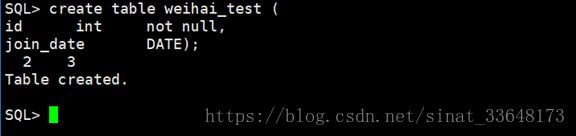
1、创建测试表
首先创建测试表weihai_test语句如下
create table weihai_test (
id int notnull,
join_date DATE);
以上表中join_date字段为分区表字段
2、插入数据
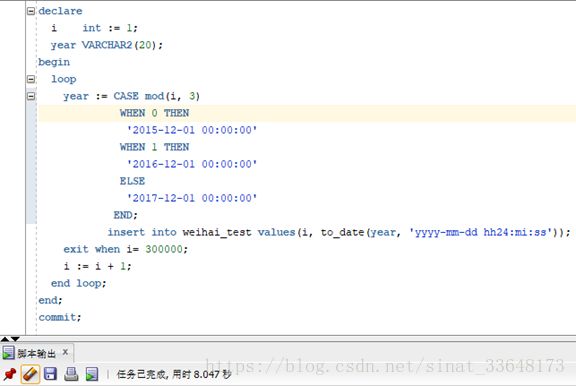
2.1、模拟插入30万条数据
plsql/developer 工具执行
declare
i int := 1;
year VARCHAR2(20);
begin
loop
year :=CASE mod(i, 3)
WHEN 0 THEN
'2015-12-01 00:00:00'
WHEN 1 THEN
'2016-12-01 00:00:00'
ELSE
'2017-12-01 00:00:00'
END;
insert into weihai_test values(i, to_date(year, 'yyyy-mm-dd hh24:mi:ss'));
exit when i= 300000;
i := i+ 1;
end loop;
end;
commit;
2.2、查看是否插入成功
select count(1) from weihai_test;

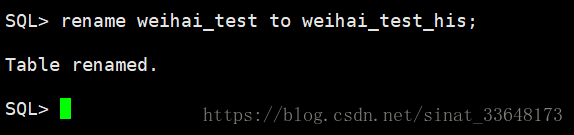
3、重命名原表,生成临时表
数据插入完成后,重命名原表,这里演示的是停机之后的操作,如果是在线操作,建议使用oracle 在线重定义功能来保障数据不丢失
rename weihai_test to weihai_test_his; (这个过程只建议应用停机的时候做)
4、创建分区表
create table weihai_test (
id int notnull,
join_date DATE )
partition by range(join_date)
(
partition weihai_test_2016_less values less than (to_date('2016-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')) tablespace fmt,
partition weihai_test_2016 values less than (to_date('2017-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')) tablespace fmt,
partition weihai_test_2017 values less than (to_date('2018-01-01 00:00:00','yyyy-mm-dd hh24:mi:ss')) tablespace fmt,
partition weihai_test_max values less than (to_date('2999-12-31 23:59:59','yyyy-mm-ddhh24:mi:ss')) tablespace fmt
);

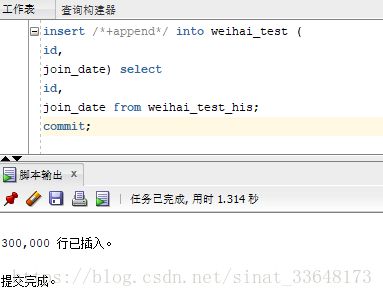
5、数据转移
表创建完成之后,开始导数,
insert /*+append*/ into weihai_test (
id,
join_date) select
id,
join_date from weihai_test_his;
commit;
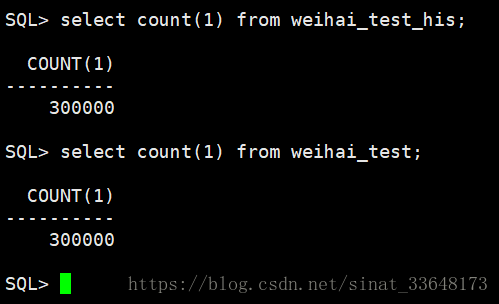
6、数据对比
导入完成之后,对比两张表的数据,一样就表示导入成功
select count(1) from weihai_test_his;
select count(1) from weihai_test;
7、查看执行计划
查询数据,查看执行计划,与临时表weihai_test_his相比较,是否扫描的更少
explain plan for select * from weihai_test_his where join_date <= date'2016-01-01';
select plan_table_output from table(dbms_xplan.display());

同样的查询在分区表执行一遍
explain plan for select * from weihai_test where join_date <= date'2016-01-01';
select plan_table_output from table(dbms_xplan.display());
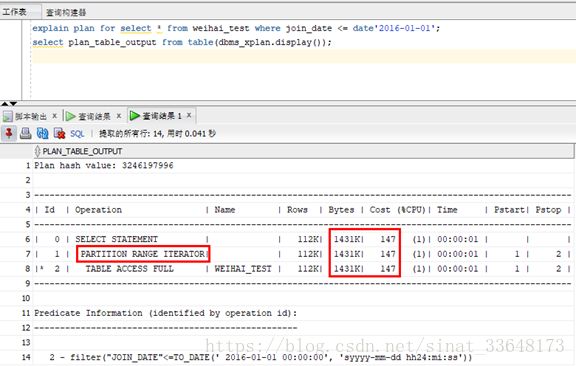
相比之下,分区表耗费的资源更少
8、删除临时表
数据导入完成之后,drop临时表
drop table weihai_test_his;