GCC 7.5.0 选项 及 NEON 选项
gcc 编译选项
-std=
确定语言标准。当前仅在编译C或C ++时才支持此选项。
必须提供此选项的值。可能的值是
‘c90’
‘c89’
‘iso9899:1990’
Support all ISO C90 programs (禁用了与ISO C90冲突的某些GNU扩展). Same as -ansi for C code.
‘iso9899:199409’
ISO C90 as modified in amendment 1.
‘c99’
ISO C99. This standard is substantially completely supported,
‘c11’
ISO C11, the 2011 revision of the ISO C standard. This standard is substantially completely supported,
‘gnu90’
‘gnu89’
GNU dialect of ISO C90 (including some C99 features).
‘gnu99’
GNU dialect of ISO C99.
‘gnu11’
GNU dialect of ISO C11. This is the default for C code.
‘c++98’
‘c++03’
1998 ISO C ++标准以及2003技术勘误表和一些其他缺陷报告. Same as -ansi for C++ code.
‘gnu++98’
‘gnu++03’
GNU方言 -std=c++98.
‘c++11’
2011 ISO C ++标准及其修订版
‘gnu++11’
GNU方言 -std=c++11.
‘c++14’
2014 ISO C ++标准及其修订版
‘gnu++14’
GNU方言 -std = c ++ 14 这是C ++代码的默认设置。
最初的ANSI C标准(X3.159-1989)于1989年批准并于1990年发布。该标准在1990年晚些时候被批准为ISO标准(ISO / IEC 9899:1990)。
要在GCC中选择此标准,请使用以下选项之一 -ansi, -std=c90 或者 -std=iso9899:1990;
1995年发布了对1990年标准的修订。修订后的标准有时称为C94或 C95。要在GCC中选择此标准,请使用 -std = iso9899:199409
ISO C标准的新版本于1999年作为ISO / IEC 9899:1999发布,通常称为C99。(在开发过程中,此标准版本的草案被称为C9X。)GCC对该标准版本提供了基本完整的支持; 请使用-std = c99 或 -std = iso9899:1999。
C标准的第四个版本称为C11,于2011年发布为ISO / IEC 9899:2011。(在开发过程中,此标准版本的草案被称为C1X。)GCC对该标准提供了基本完整的支持,并启用了-std = c11 要么 -std = iso9899:2011。
调试程序的选项
要告诉GCC生成更多信息供调试器使用,几乎在所有情况下,您只需要添加 -g 选项
如果没有使用其他优化选项,可以考虑使用-Og。如果没有-O选项,some compiler passes that collect information useful for debugging do not run at all,因此-Og可能会带来更好的调试体验。
控制优化的选项
如果没有任何优化选项,编译器的目标是降低编译成本并使调试产生预期的结果。语句是独立的:如果您在语句之间使用断点来停止程序,则可以将新值分配给任何变量,或者将程序计数器更改为函数中的任何其他语句,并从源代码中准确获取期望的结果。
启用优化标志会使编译器尝试以牺牲编译时间和调试程序的能力为代价来提高性能和/或代码大小。
并不是所有的优化都是由一个标志直接控制的。本节只列出有标记的优化。
大多数优化只有在命令行上设置-O级别时才启用。否则,即使指定了各个优化标志,它们也会被禁用。(指详细的单个优化标志,例如-fcrossjumping)
-O
-O1
优化。对于大型函数,优化编译需要更多的时间和更多的内存。
用 -O, 编译器会尝试减少代码大小和执行时间,不执行任何需要大量编译时间的优化。
-O2
更多的优化。GCC执行几乎所有支持的优化,而这些优化不涉及以空间换时间。相比于-O,此选项会增加编译时间和所生成代码的性能。
-O2 打开所有-O 指定的优化标志 .
-O3
进一步优化. -O3打开-O2指定的所有优化,也打开 -finline-functions, -funswitch-loops, -fpredictive-commoning, -fgcse-after-reload, -ftree-loop-vectorize, -ftree-loop-distribute-patterns, -fsplit-paths -ftree-slp-vectorize, -fvect-cost-model, -ftree-partial-pre, -fpeel-loops and -fipa-cp-clone options.
-O0
减少编译时间,使调试产生预期的结果。这是默认设置。
-Os
优化大小. -Os 打开所有-O2 中通常不会增加代码大小的优化.
它还使 -finline功能,导致编译器调整代码大小而不是执行速度,并执行旨在减小代码大小的进一步优化。
-Ofast
忽略严格的标准合规性。 -Ofast 使所有 -O3优化。它还启用了并非对所有符合标准的程序都有效的优化。
-Og
优化调试体验。 -Og启用不干扰调试的优化。它应该是标准edit-compile-debug周期的优化级别选择,在保持快速编译和良好调试体验的同时,提供合理的优化级别。
如果您使用多个 -O 选项,带有或不带有级别编号,最后一个这样的选项是有效的。
请求或禁止警告的选项
-w
禁止所有警告消息
-Werror
使所有警告变为错误
-Werror=
将指定的警告变为错误。例如 -Werror=switch 将 -Wswitch 抑制的警告变为错误. 此开关采用负形式,用于对 -Werror 指定的警告进行取反; 例如 -Wno-error=switch 使 -Wswitch 警告不是错误, 即使是 -Werror 有效.
请注意,指定 -Werror=foo 自动暗示 -Wfoo. 然而,, -Wno-error=foo 并不暗示任何东西
-Wfatal-errors
此选项使编译器在发生第一个错误时中止编译,而不是尝试继续进行并打印其他错误消息。您可以使用以 ‘-W’ 开头的选项来请求许多特定的警告 例如 -Wimplicit 请求对隐式声明的警告. 每一个特定警告选项都有一个以‘-Wno-’开头的关闭警告; 例如, -Wno-implicit.
-Wall
这将启用所有有关某些用户认为可疑的构造的警告,即使与宏结合使用,也很容易避免(或进行修改)以防止出现警告
-Wextra
这将启用一些-Wall未启用的额外警告标志(此选项以前称为-W。仍支持较旧的名称,但较新的名称更具描述性。)
-Wchar-subscripts
如果数组下标的类型为char,则发出警告。这是导致错误的常见原因,因为程序员经常忘记这种类型是在某些机器上签名的。此警告通过-Wall启用。
-Wchkp
警告由“指针边界检查器”(-fcheck-pointer-bounds)发现的无效内存访问
-Wformat
-Wformat=n
检查对printf和scanf等的调用,以确保提供的参数具有与指定的格式字符串相对应的类型,并且确保在格式字符串中指定的转换有意义。
程序检测选项
GCC支持许多命令行选项,这些选项控制将运行时工具添加到它通常生成的代码中。例如,检测的目的之一是收集概要分析统计信息,以用于查找程序热点,代码覆盖率分析或配置文件引导的优化。另一类程序工具是添加运行时检查,以检测编程错误,例如无效的指针解引用或越界数组访问,以及故意的敌对攻击,例如堆栈粉碎或C ++ vtable劫持。还有一个通用钩子,可用于实现其他形式的跟踪或功能级检测,以用于调试或程序分析。
-p
生成额外的代码以编写适合分析程序的配置文件信息prof。编译要用于数据的源文件时,必须使用此选项,并且在链接时也必须使用它。
-pg
生成额外的代码以编写适合分析程序的配置文件信息gprof。编译要用于数据的源文件时,必须使用此选项,并且在链接时也必须使用它。
-fprofile-arcs
添加代码,以便检测程序流弧。在执行期间,程序记录每个分支和调用执行了多少次,以及执行或返回了多少次。在支持具有优先级支持的构造函数的目标上,性能分析可以正确处理用作全局变量类型的类的构造函数,析构函数和C ++构造函数(和析构函数)
控制预处理器的选项
-D name
将name预定义为具有定义的宏1
-D name=definition
对定义的内容进行标记和处理,好像它们出现在“#define”指令的翻译第三阶段。特别是,定义被内嵌的换行字符截断。在等号(如果有)前用圆括号括起它的参数列表。括号对于大多数shell都是有意义的,因此应该引用该选项。With sh and csh, -D'name(args…)=definition' works
-U name
取消name的任何以前的定义,该定义是内置的或随-D 选项
-undef
不要预定义任何系统特定的宏或GCC特定的宏。标准的预定义宏保持定义。
-pthread
定义使用POSIX线程库所需的其他宏。对于编译和链接,应始终使用此选项。GNU / Linux目标,大多数其他Unix派生以及x86 Cygwin和MinGW目标都支持此选项。
目录搜索的选项
这些选项指定目录以搜索头文件,库和编译器的一部分
-I dir
添加目录 dir 到预处理过程中搜索头文件的目录列表
-L dir
将目录dir添加到要被 -l 搜索的目录列表中
-isysroot dir
这个选项就像 --sysroot选项,但仅适用于头文件(Darwin目标除外,它适用于头文件和库)
--sysroot=dir
使用dir作为头和库的逻辑根目录。例如,如果编译器通常在以下位置搜索头文件 /usr/include 和库 /usr/lib,,而是搜索 dir / usr / include 和 目录 / usr / lib。
如果同时使用此选项和 -isysroot 选项,然后 --sysroot 该选项适用于库,但是 -isysroot 该选项适用于头文件。
GNU链接器(从2.16版开始)具有对此选项的必要支持。如果您的链接器不支持此选项,则头文件方面--sysroot 仍然有效,但库方面无效
参数可变的宏。
在1999年的ISO C标准中,可以将宏声明为接受可变数量的参数,就像函数可以接受的那样。定义宏的语法类似于函数的语法。这是一个例子:
#define debug(format, ...) fprintf (stderr, format, __VA_ARGS__)
GCC长期以来支持可变参数宏,并使用了不同的语法,使您可以像其他任何参数一样为变量参数命名。这是一个例子:
#define debug(format, args...) fprintf (stderr, format, args)
这在所有方面都等同于上述ISO C示例,但是可以说更具可读性和描述性。
GNU CPP还有另外两个可变的宏扩展,并允许它们与上述两种形式的宏定义一起使用。
在标准C中,不允许完全省略变量参数。但您可以传递一个空参数。例如,此调用在ISO C中是无效的,因为字符串后没有逗号:
debug ("A message")
GNU CPP允许您以这种方式完全省略变量参数,在上面的例子中,编译器会报错.尽管由于宏的展开仍然在格式字符串后面有额外的逗号。
为了帮助解决这个问题,CPP特别针对令牌粘贴操作符' ## '使用的变量参数。如果你写:
#define debug(format, ...) fprintf (stderr, format, ## __VA_ARGS__)
如果变量参数被省略或为空,' ## '操作符使预处理程序删除它前面的逗号。如果在宏调用中提供了一些变参,GNU CPP并报错,而是将变量参数放在逗号之后,与任何其他粘贴的宏参数一样,这些参数不是宏展开的。
转义的换行符的松散规则
转义的换行符的预处理器处理比C90标准所指定的宽松,这要求换行符立即跟在反斜杠之后。GCC的实现允许以空格,水平和垂直制表符的形式出现空格,并在反斜杠和后续换行符之间形成换页。预处理器发出警告,但将其视为有效的转义换行符,并将这两行合并以形成一条逻辑行。这适用于注释和标记以及标记之间。出于放松目的,注释不被视为空白,因为它们尚未被空格代替。
关于void指针和函数指针的算术运算
在GNU C中,指向void和指向函数的指针支持加法和减法运算 。这是通过将void或函数的大小处理为1来实现的。
其结果是,在void和函数类型上也允许sizeof,并返回1。如果使用了这些扩展,选项 -Wpointer-arith 请求一个警告
ARM 选项
-mfloat-abi=name
指定使用哪个浮点ABI。允许的值是: ‘soft’, ‘softfp’ and ‘hard’.
指定“soft”将导致GCC生成包含对浮点操作的库调用的输出。“softfp”允许使用硬件浮点指令生成代码,但仍然使用软浮点调用约定。‘hard’ 允许生成浮点指令并使用特定于fpu的调用约定。
默认值取决于特定的目标配置。注意,硬浮动和软浮动ABIs是不兼容的链接; 您必须使用相同的ABI编译整个程序,并使用一组兼容的库进行链接。
-march=name
这指定了目标ARM架构的名称。GCC使用这个名称来确定在生成汇编代码时可以发出什么样的指令。这个选项可以与-mcpu=选项一起使用,也可以代替-mcpu=选项。允许的名字是:‘armv2’, ‘armv2a’, ‘armv3’, ‘armv3m’, ‘armv4’, ‘armv4t’, ‘armv5’, ‘armv5e’, ‘armv5t’, ‘armv5te’, ‘armv6’, ‘armv6-m’, ‘armv6j’, ‘armv6k’, ‘armv6kz’, ‘armv6s-m’, ‘armv6t2’, ‘armv6z’, ‘armv6zk’, ‘armv7’, ‘armv7-a’, ‘armv7-m’, ‘armv7-r’, ‘armv7e-m’, ‘armv7ve’, ‘armv8-a’, ‘armv8-a+crc’, ‘armv8.1-a’, ‘armv8.1-a+crc’, ‘armv8-m.base’, ‘armv8-m.main’, ‘armv8-m.main+dsp’, ‘iwmmxt’, ‘iwmmxt2’.
-mtune=name
此选项指定目标ARM处理器的名称,GCC应该为该处理器调优代码的性能。对于某些ARM实现,通过使用这个选项可以获得更好的性能。允许的名字是: ‘arm2’, ‘arm250’, ‘arm3’, ‘arm6’, ‘arm60’, ‘arm600’, ‘arm610’, ‘arm620’, ‘arm7’, ‘arm7m’, ‘arm7d’, ‘arm7dm’, ‘arm7di’, ‘arm7dmi’, ‘arm70’, ‘arm700’, ‘arm700i’, ‘arm710’, ‘arm710c’, ‘arm7100’, ‘arm720’, ‘arm7500’, ‘arm7500fe’, ‘arm7tdmi’, ‘arm7tdmi-s’, ‘arm710t’, ‘arm720t’, ‘arm740t’, ‘strongarm’, ‘strongarm110’, ‘strongarm1100’, ‘strongarm1110’, ‘arm8’, ‘arm810’, ‘arm9’, ‘arm9e’, ‘arm920’, ‘arm920t’, ‘arm922t’, ‘arm946e-s’, ‘arm966e-s’, ‘arm968e-s’, ‘arm926ej-s’, ‘arm940t’, ‘arm9tdmi’, ‘arm10tdmi’, ‘arm1020t’, ‘arm1026ej-s’, ‘arm10e’, ‘arm1020e’, ‘arm1022e’, ‘arm1136j-s’, ‘arm1136jf-s’, ‘mpcore’, ‘mpcorenovfp’, ‘arm1156t2-s’, ‘arm1156t2f-s’, ‘arm1176jz-s’, ‘arm1176jzf-s’, ‘generic-armv7-a’, ‘cortex-a5’, ‘cortex-a7’, ‘cortex-a8’, ‘cortex-a9’, ‘cortex-a12’, ‘cortex-a15’, ‘cortex-a17’, ‘cortex-a32’, ‘cortex-a35’, ‘cortex-a53’, ‘cortex-a57’, ‘cortex-a72’, ‘cortex-a73’, ‘cortex-r4’, ‘cortex-r4f’, ‘cortex-r5’, ‘cortex-r7’, ‘cortex-r8’, ‘cortex-m33’, ‘cortex-m23’, ‘cortex-m7’, ‘cortex-m4’, ‘cortex-m3’, ‘cortex-m1’, ‘cortex-m0’, ‘cortex-m0plus’, ‘cortex-m1.small-multiply’, ‘cortex-m0.small-multiply’, ‘cortex-m0plus.small-multiply’, ‘exynos-m1’, ‘marvell-pj4’, ‘xscale’, ‘iwmmxt’, ‘iwmmxt2’, ‘ep9312’, ‘fa526’, ‘fa626’, ‘fa606te’, ‘fa626te’, ‘fmp626’, ‘fa726te’, ‘xgene1’.
-mcpu=name
它指定目标ARM处理器的名称。GCC使用这个名称派生目标ARM体系结构的名称(就像由-march指定的那样)和ARM处理器类型(就像由-mtune指定的那样)。当此选项与-march或-mtune一起使用时,这些选项优先于此选项的适当部分。
此选项的允许名称与-mtune相同。-mcpu=generic-arch也是允许的,相当于-march=arch -mtune=generic-arch。有关更多信息,请参见-mtune
-mfpu=name
它指定目标上可用的浮点硬件(或硬件仿真)。允许的名称为:'vfpv2','vfpv3','vfpv3-fp16','vfpv3-d16','vfpv3-d16-fp16','vfpv3xd','vfpv3xd-fp16',vfpv2’, ‘vfpv3’, ‘vfpv3-fp16’, ‘vfpv3-d16’, ‘vfpv3-d16-fp16’, ‘vfpv3xd’, ‘vfpv3xd-fp16’, ‘neon-vfpv3’, ‘neon-fp16’, ‘vfpv4’, ‘vfpv4-d16’, ‘fpv4-sp-d16’, ‘neon-vfpv4’, ‘fpv5-d16’, ‘fpv5-sp-d16’, ‘fp-armv8’, ‘neon-fp-armv8’ and ‘crypto-neon-fp-armv8’. 注意 ‘neon’ 是‘neon-vfpv3’ 的别名,‘vfp’ 是 ‘vfpv2’ 的别名.
如果指定了-msoft-float,则此选项指定浮点值的格式。
如果所选的浮点硬件包括NEON扩展 (e.g. -mfpu=‘neon’), 注意,浮点操作不是由GCC的自动向量化传递生成的,除非还指定了-funsafe-math-optimization。这是因为NEON硬件没有完全实现IEEE 754浮点运算标准(特别是 denormal values值被视为零)所以使用NEON指令可能会导致精度下降。
-funsafe-math-optimizations
允许对浮点算法进行优化,以确保(a)假定参数和结果有效,并且(b)可能违反IEEE或ANSI标准。在链接时使用时,它可能包括更改默认FPU控制字或其他类似优化的库或启动文件。
该选项没有被任何 -O选项打开,因为它可能导致程序的错误输出,这些程序依赖于数学函数的IEEE或ISO规则/规范的确切实现。但是,对于不需要这些规范保证的程序,它可能会产生更快的代码。The default is -fno-unsafe-math-optimizations.
科普 denormal values:
https://en.wikipedia.org/wiki/Denormal_number
任何小于最小正态数的非零数都是“次正态”。

https://en.wikipedia.org/wiki/ARM_architecture#Advanced_SIMD_(NEON)
高级SIMD(NEON)[ 编辑]
的高级SIMD扩展(又名NEON或“MPE”媒体处理引擎)是组合的64位和128位的SIMD指令集,提供了一种用于媒体和信号处理应用标准化加速度。NEON包含在所有Cortex-A8设备中,但在Cortex-A9设备中是可选的。[103] NEON可以在以10 MHz运行的CPU上执行MP3音频解码,并且可以以13 MHz 运行GSM 自适应多速率(AMR)语音编解码器。它具有全面的指令集,独立的寄存器文件和独立的执行硬件。[104]NEON支持8位,16位,32位和64位整数和单精度(32位)浮点数据以及SIMD操作,用于处理音频和视频处理以及图形和游戏处理。在NEON中,SIMD最多同时支持16个操作。NEON硬件共享与VFP中使用的浮点寄存器相同的寄存器。诸如ARM Cortex-A8和Cortex-A9之类的设备支持128位向量,但一次只能执行64位[100],而较新的Cortex-A15设备可以一次执行128位。
在ARMv7设备中,NEON的一个怪癖是它将所有次正规数刷新为零,因此GCC编译器将不会使用它,除非-funsafe-math-optimizations打开,它允许丢失非正规数。由于ARMv8没有这个怪异,因此定义了“增强型” NEON,但是从GCC 8.2开始,启用NEON指令仍需要相同的标志。[105]另一方面,GCC确实认为NEON在ARMv8的AArch64上安全。
ProjectNe10是ARM的第一个开源项目(从成立之初;他们收购了一个较旧的项目,现在称为Mbed TLS)。Ne10库是用NEON和C编写的一组通用,有用的函数(出于兼容性考虑)。创建该库的目的是使开发人员无需学习NEON就可以使用NEON优化,但它也可以作为一组高度优化的NEON内在代码和汇编代码示例,用于常见的DSP,算术和图像处理例程。源代码可在GitHub上获得。[106]
关于 ARM FPU(VFP / NEON)类型:https://dench.flatlib.jp/opengl/fpu_vfp
针对gcc的ARMv7A NEON优化需要-funsafe-math优化。因为它不符合IEEE754。
https://blog.csdn.net/heli200482128/article/details/79303286
自动向量化选项
gcc编译器的向量化选项-ftree-vectorize来使能向量化选项,使用-O3会自动使能-ftree-vectorize选项
系统运行时使能NEON
内核在遇到第一个NEON指令时会产生一个UndefinedInstruction的异常,这会让内核自动重启NEON协处理器,内核还可以在上下文切换时关闭NEON来省电。
内核使能NEON
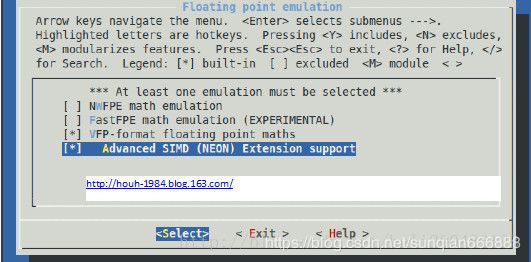
使能NEON,需要选择以下选项
Floating point emulation → VFP-format floating point maths
Floating pointemulation → Advanced SIMD (NEON) Extension
检查Linux的配置文件来确认内核是否使能NEON
zcat /proc/config.gz | grep NEON
看是否存在
CONFIG_NEON=y
确认处理器是否支持NEON
cat /proc/cpuinfo | grep neon