无服务计算的未来和挑战: A Berkeley View on Serverless Computing
加州大学伯克利分校继 2009 年发布 《The Berkeley View on Cloud Computing》一举拨开云计算迷雾,十年后又一次发布了 《A Berkeley View on Serverless Computing》,试图再次指出下个 10 年云计算的发展方向及挑战,并断言无服务计算将成为云时代的默认计算范式,在很大程度上取代 serverful 计算,从而结束客户机-服务器时代。由此可见无服务计算( Serverless Computing) 这一新云计算范式所具有的里程碑意义。
如下图所示,是 Google Trend 总结的过去五年中关键词 “Serverless” 和 “Microservices” 的搜索趋势,发现在 2017 年 Serverless 的搜索趋势开始超过微服务,也从用户搜索层面表明无服务越来越多的进入大家的视野。

本文从伯克利这篇文章入手,为大家揭开 Serverless 神秘的面纱。
以下长文预警。。。
以下长文预警。。。
广告时间:
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。
摘要
无服务云计算几乎了处理所有系统管理操作,使得程序员能够更加容易地使用云。 无服务计算提供了一个接口极大地简化了云编程,并且代表了从汇编语言到高级编程语言的转变。 本文简要介绍了云计算的历史,包括了 2009 年伯克利对云计算的预测,揭示了无服务计算的 motivation,描述了扩展无服务当前限制的应用程序,然后列出了发挥无服务计算潜力所遇到的阻碍和机会。 就像 2009 年的论文确定了云的挑战并预测它们将得到解决,以及云会越来越被广泛使用一样,我们预测这些问题是在未来可被以解决的,并且无服务计算将成为云计算未来的主导。
1 Introduction to Serverless Computing
The data center is now the computer.
Luiz Barroso (2007)
在 2009 年,为了帮助解释云计算所带来的优势,伯克利在 《The Berkeley View on Cloud Computing》一文中提出了六个潜在优势:
- 可以按需使用无限量的计算资源
- 消除运用户的预先承诺
- 根据实际需要支付短期使用计算资源的费用
- 规模经济显著降低了成本,因为数据中心非常大
- 通过资源虚拟化技术简化了操作病提高了资源利用率
- 通过多路复用的方式运行来自不同组织的负载,提高硬件资源利用率
在过去的这十年中,我们可以看到这些优势大部分都实现了,但是云用户仍然要忍受着复杂操作的压力,许多负载仍然没有从高效的多路复用中收益。这些不足主要于未能实现的两个潜在优势有关,云计算虽然减轻了用户对物理资源(即基础设施)的管理,但是他们需要管理大量的虚拟资源。多路复用对于批处理类型的负载(如 MapReduce 或高性能计算)非常有效,这些负载可以充分利用分配给它们的实例,但是对于有状态的服务并没有那么有效,例如将企业的软件移植到云计算上时(如数据库管理系统)。
在 2009 年,有两种相互竞争的云虚拟化方法,正如这篇论文中所解释的:
Amazon EC2 is at one end of the spectrum. An EC2 instance looks much like physicalhardware, and users can control nearly the entire software stack, from the kernel upward… At the other extreme of the spectrum are application domain-specific platforms suchas Google App Engine … enforcing an application structure of clean separation between astateless computation tier and a stateful storage tier. App Engine’s impressive automaticscaling and high-availability mechanisms … rely on these constraints.
Amazon EC2 是一个极端,EC2 实例看起来很像物理硬件,用户几乎可以控制整个软件栈,从内核向上… 另一个极端是针对于特定领域的应用平台,比如 Google App Engine… 在无状态计算层和有状态存储层之间强制使用分离的应用程序结构,App Engine 的自动扩展和高可用性机制… 依赖这些约束。
最终市场使用了 Amazon 这种针对云计算的 low-level 虚拟机方式,所以 Google、Microsoft 和其他云计算公司也提供了相似的接口。我们相信这种 low-level 虚拟机成功的主要原因是,早起的云计算用户希望在云中可以重新创建一个与本地计算机上相同的计算环境,以简化将其负载迁移到云上的工作。很明显,这种实际需求比为云重新编写新的程序更重要,尤其是在当时云计算能否成功尚不明确的情况下。
这种选择的缺点是,开发人员必须自己管理虚拟机,所以要么成为系统管理员,要么与它们一起设置环境。表1列出了在云中操作时必须管理的问题,这一长串需要负责的底层虚拟机管理问题,促使那些只使用简单化应用的客户向云服务商提出新要求,希望能有更简单的方式来运行这些简单应用。例如,假设应用希望将图片从手机端应用发送到云上,这需要创建极小的图片并将其放在 web 上,完成这个任务可能只需要几十行 JavaScript 代码,这与设置适当的服务器环境来运行这段代码相比,这个代码的开发是很微不足道的。

认识到这些需求后,Amazon 在 2015 年推出了一个名为 AWS Lambda service 的新服务。Lambda 提供云函数,这引起了大家对无服务计算的广泛关注。尽管无服务可以说是一个很矛盾的说法,因为你仍然使用服务器去进行计算,这个名字之所以被保留下来,大概是因为它表明用户只需要编写代码,服务器供应和任务管理问题都由服务提供商来负责。尽管云函数打包为 FaaS(Function as a service),代表了无服务器计算的核心,但是云平台还提供了专门的无服务器框架,以满足特定的程序需求,如 BaaS(Backend as a Service)。简单地说,无服务计算定义如下:
Serverless Computing = FaaS + BaaS。
在我们的定义中,要将服务视为无服务的,他必须能够自动扩缩容,并且根据实际使用情况计费,在本文的其余部分中,我们将重点讨论云函数的出现、演化和未来。云函数是当今无服务计算的通用元素,它为云提供了简化的通用编程模型。
接下来,我们将定义无服务计算(serverless computing),与十年前的 《The Berkeley View on Cloud Computing》文章一样,我们后面会列出实现无服务计算的承诺所面临的挑战和研究机会,虽然我们不确定哪种解决方案会胜出,但是我们相信所有问题最终都会得到解决,从而使无服务计算称为云计算的新面貌。
2 Emergence of Serverless Computing
在任何无服务平台,用户只需要用高级语言编写云函数,选择触发云函数运行的事件就可以了,例如加载一个镜像到云存储中,或者向数据库添加一个很小的图片,让无服务系统来处理其他所有事情,如选择实例、扩缩容、部署、容错、监控、日志、安全补丁等等。表2 总结了无服务和传统方式之间的差异,本文将其称为 serverful 云计算。需要注意的是,这两种方法表示 function-based/server-centered 的计算平台的端点,而 Kubernetes 之类的容器编排框架则表示中间层。

图1 说明了 serverless 如何通过简化云资源的使用来简化应用程序的开发。在云上下文中,serverful 计算类似于使用低级汇编语言进行编程,而无服务计算类似于使用高级语言(例如 python)进行编程。计算例如 c = a + b 的简单表达式的汇编程序员必须选择一个或者多个寄存器,将值加载到这些寄存器中,执行运算,然后存储结果。这反映了 serverful 云编程的几个步骤,首先提供资源或者标识可用的资源,然后用必要的代码和数据加载这些资源,执行计算,返回或者存储结果,最终管理资源释放。无服务计算的目标是为云程序员提供类似于高级编程语言的便捷性。无服务计算与高级编程环境的其他特性也有相似之处,例如自动内存管理使程序员不用再管理内存资源,而无服务计算使程序员不用再管理服务器资源。
准确来说,serverless 和 serverful 计算有三个关键的不同之处:
- 将计算与存储解耦。存储和计算资源是分开提供的,相当于这两种资源的分配和计价都是独立的,通常来说存储资源是由一个独立的云服务来提供的,并且计算是无状态的。
- 执行代码而不需要管理资源分配。与传统云计算用户需要请求资源的方式不同,serverless 是用户提交一段代码,云会自动给这段代码分配资源并执行。
- 以实际使用的资源量付费,而不是根据分配的资源数。serverless 计费是根据一系列与执行相关的因素来计算的,例如代码的执行时间,而不实根据云平台,例如分配的 VM 的大小和数量。
接下来,根据这些区别,我们会解释 serverless 在过去和现在与类似的产品会有何不同。

2.1 Contextualizing Serverless Computing
要使无服务计算成为可能,需要突破哪些技术呢?一些人认为,无服务计算只是对以前产品的重新命名,可能是对平台即服务(Platform as a Service,PaaS)的一个概括。其他人可能会指出,上世纪 90 年代流行的共享 web 主机环境提供了许多无服务计算所能提供的功能。例如,它们有一个无状态编程模型,允许多租户、对可变需求的弹性响应和一套标准化的函数调用 API、公共网关接口(CGI),甚至允许直接部署用 Perl 或 PHP 等高级语言编写的代码。Google 最初的 App Engine,它也允许开发者直接部署代码,同时将大部分的操作交由云提供上来进行,但是在无服务计算流行起来前的那几年,基本上是不被市场接纳的。我们相信,相对于 PaaS 和其他以前的模型,无服务计算代表了重大的创新。
当下的无服务计算与之前的产品不同点在于:更好的自动扩缩容、强隔离、平台灵活性和服务生态支持,在这些不同点中,AWS Lambda 提供的自动扩缩容标志着与之前产品最大的不同。Serverless 平台跟踪应用的负载并进行自动扩缩容做的比 serverful 好很多,可以在需要时快速响应扩容,并在没有需求的情况下将资源一直缩容到零。它以一种更加细粒度的方式管理,当其自动扩缩容服务按时间计费时,它提供了 100ms 粒度的最小增长。当峰值时刻离开时,它按照代码实际执行的时间进行收费,而不是按照位程序预留的资源,这一区别确保了云提供商在自动扩缩容上风险共担,从而提供了确保有效资源分配。
无服务计算依赖于强大的性能和安全隔离,使多租户共享硬件成为可能。VM 类似的隔离是当前云函数下多租户硬件共享的标准,但是因为 VM 配置需要较长的时间,为了缩短这个时间,无服务计算提供商使用复杂的技术来加快函数运行环境的创建。AWS Lambda 中使用的方法是维护一个热的 VM 实例池,以及维护一个用于运行函数实例的池子,以服务于未来服务的调用。资源的生命周期管理和多租户下负载打包是无服务计算中提高利用率的关键技术,我们注意到,最近一些工作旨在通过利用容器、unikerkernel、操作系统库或语言 VM 来介绍提供多租户隔离的开销。例如谷歌已经宣布 gVisor 已经应用在 App Engine、Cloud Functions 和 Cloud Engine,Amazon 发布了针对 AWS Lambda 和 AWS Fargate 的 Firecracker VMs,并且 CloudFlare Workers 无服务计算平台使用 Web 沙盒技术提供了多租户之间 JavaScript 函数之间的隔离。
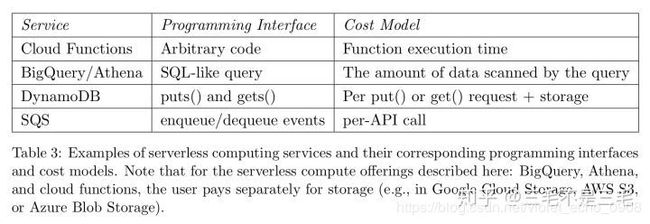
其他一些特性也帮助无服务计算获得了成功。通过允许用户自带库,无服务计算可以支持比 PaaS 服务更广泛的应用程序。无服务计算运行在现代数据中心中,其运行规模比之前的共享 web 主机环境要大得多。如第1节所述,云函数(FaaS)推广了无服务计算范例,然而,值得承认的是,他们的成功在一定程度上归功于公有云(如 AWS S3 等服务)诞生以来就存在的 BaaS 产品。在我们看来,这些服务是特定领域的、高度优化的无服务计算实现,云函数以更加通用的形式表示无服务计算。通过比较几个服务的编程接口和成本模型,我们在表3中总结了一个图。
在讨论无服务计算时,一个常见的问题是它如何与部署微服务的 Kubernetes “容器编排” 技术相关联。与无服务计算不同,Kubernetes 是一种简化的服务器计算管理的技术,由于多年来 Google 内部的开发和使用,它得到了快速的发展。Kubernetes 可以提供短期的计算环境,比如无服务计算,并在硬件资源、执行时间和网络通信方面有更少的限制。它还可以将原本为内部使用而开发的软件完全部署到公有云上,而无需进行任何修改。在另一方面,无服务计算引入了一个范式转变,完全将操作责任转交给服务提供商,使得更细粒度的多租户下的多路复用成为可能。托管的 Kubernetes 产品,如 Google Kubernetes Engine(GKE)和 AWS Elastic Kubernetes Service(EKS)提供了一个中间地带:用户不需要考虑 Kubernetes 的操作管理,同时为开发人员提供了配置任意容器的灵活性。托管式的 Kubernetes 服务和无服务计算之间的一个关键区别是计算模型,前者按照预留的资源收费,而后者按照函数执行时间收费。
Kubernetes 也非常适合混合应用程序,其中一部分运行在本地硬件上,另一部分运行在云中。我们的观点是,这种混合应用程序在向云的过渡中是很有意义的,然而从长期来看,我们认为云的规模经济、更快的网络贷款、不断增加的云服务以及通过无服务计算简化云管理,降低此类混合应用的重要性。边缘计算是后 PC 时代云计算的合作伙伴,虽然我们在这里关注的是无服务计算将如何改变数据中心中的编程方式,但是边缘计算也具有潜在的影响,一些 Content Delivery Network(CDN)运营商提供了在接近用户的设施中之行无服务函数的能力,无论用户可能在那里,AWS IoT Greengrass 甚至可以在边缘设备中嵌入无服务执行。
现在我们已经定义了无服务计算,并介绍了其上下文,让我们看看为什么它对云提供商、云用户和研究人员具有吸引力。
2.2 Attractiveness of Serverless Computing
对于云服务提供商来说,无服务计算促进业务的增长,因为其使得云计算更容易编程,进而有助于吸引新客户并帮助现有客户更多地使用云计算。例如,最近的调查发现,大约 24% 的无服务计算用户是云计算的新用户,30% 现有的 serverful 用户也使用了无服务计算。此外,短的运行时间、较小的内存占用和无状态特性使得云提供商更容易找到那哪些未使用的资源来运行这些任务,从而改进了资源复用。云提供商还可以利用不太流行的计算机(实例类型由云提供商决定),比如对 serverful 云客户吸引较小的旧服务器,这两项优点都可以最大化现有的资源并提高收益。
用户可以从编程效率的提高中获益,而且在许多情况下还可以节约成本,这是底层服务器利用率提高的结果。即使无服务计算可以让客户更高效,Jevons paradox 建议他们增加对云的使用,而不是减少,因为更高的效率将通过增加用户来增加需求。无服务也从 x86 机器代码(有99%的云机器使用 x86指令集)提升到更高级的编程语言,这有助于计算机体系结构的创新。如果 ARM 或 RISC-V 可以提供比 x86 更好的性价比,那么无服务计算使得更改指令集更容易,云服务提供商甚至可以接受面向语言优化的研究和特定领域的体系结构,尤其是针对编程语言的加速,例如 Python,将在第四章进行介绍。
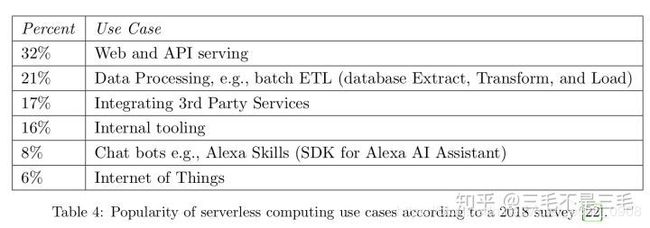
云用户更加喜欢无服务计算,因为新手可以在不需要理解云基础设施的前提下部署函数,并且老用户可以节省出部署的时间并聚焦于应用本身的问题。无服务计算可以节省开支因为函数只有在事件发生时才会计费,而且细粒度的计费(通常是 100 毫秒)意味着用户只需要支付他们实际使用的部分而不是为他们预留的部分。表4展示了当今最流行的无服务计算。
由于无服务计算是一种新的通用计算抽象,并且有望成为云计算的未来,因此无服务计算尤其是云函数深深地吸引了研究人员的注意,而且有很多机会可以提升当前无服务计算的性能和克服一些当前的限制。
3 Limitations of Today’s Serverless Computing Platforms
无服务云函数已经成功地用于几类负载,包括 API 服务、事件流处理和有限的 ETL(见表3)。为了弄清楚什么阻碍了无服务计算支持更多通用的负载,我们试图创建无服务版本的应用,并且研究别人发布的例子,这并不代表当前无服务计算生态外的其他技术,它们只是一些实例,用于发现可能阻止其他应用转换为无服务版本的常见缺点。
在本章中,我们概述了五个研究项目,并讨论了阻碍现有无服务计算平台实现最好性能的障碍,即在相同负载下匹配 serverful 云的性能。我们特别关注使用通用云函数进行计算的方法,而不是大量依赖于其他特定应用程序的无服务产品(BaaS),然而在最后一个示例 Serverless SQLite 中,我们定义了一个使用场景,该用例与 FaaS 的映射非常糟糕,因此我们得出结论,数据库和其他状态较重的应用将保持 BaaS 的状态。
有趣的是,即使这种折中的应用组合也暴露了类似的弱点,我们在描述应用程序之后列出了这些弱点,表5总结了这五个应用程序。
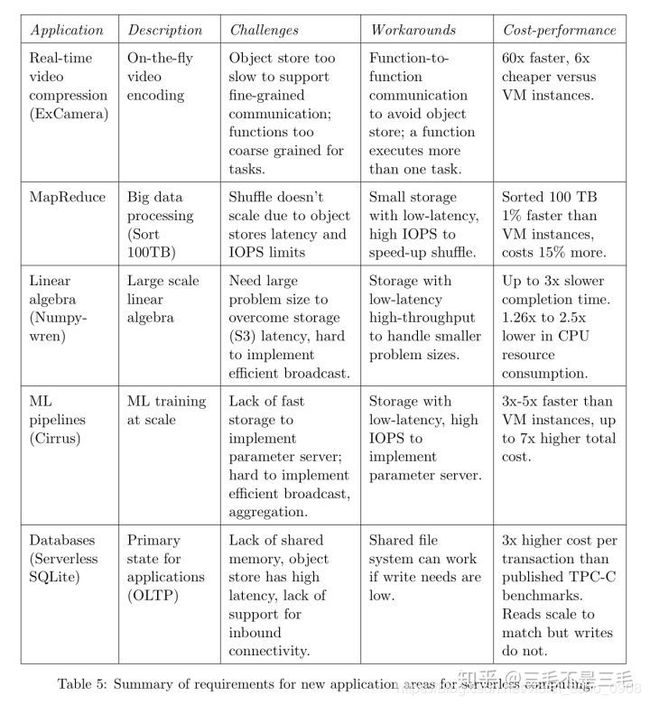
ExCamera:实时视频编码。ExCamera 旨在为向 YouTube 等网站上传视频的用户提供实时编码服务,根据视频的大小,现在的编码解决方案可能需要几十分钟,甚至几个小时。为了保证实时编码,ExCamera 并行处理编码中“慢”的部分,连续执行“快”的部分,ExCamera 公开他们内部的视频编码器和解码器,允许使用纯函数语义执行执行编码和解码任务,特别是,每个任务都将内部状态和视频帧作为输入,并将修改后的内部状态作为输出。
MapReduce。分析框架如 MapReduce、Hadoop 和 Spark 都已经传统地部署在集群中,虽然一部分分析类负载正在转向无服务计算,但这些负载主要由只包含 map 的作业组成,下一步就是支持成熟的 MapReduce 作业。这种往 Serverless 转变背后的驱动力之一就是利用无服务计算的灵活性,以有效地支持在执行过程中资源需求差异很大的作业。
Numpywren:线性代数。大规模线性代数计算传统上部署在超级计算机或者由高速、低延迟网络连接的高性能计算集群上,考虑到这段历史,无服务计算最初看起来不太合适,然而,无服务计算对于线性代数计算仍然有意义,有两个主要原因:1)对许多非 CS 科学家来说,集群管理师一个很大的障碍;2)在计算过程中,并行度可能会有很大的变化。提供一个固定大小的集群要么会降低作业执行的速度,要么会使得集群资源没有得到充分地利用。
Cirrus:机器学习训练。机器学习研究人员传统上使用 VM 集群来完成 ML 工作流中的不同任务,比如预处理、模型训练和超参数调优。这种方式的一个挑战是,这个训练的不同阶段需要的资源数明显不同,与线性代数算法一样,固定的集群大小将严重影响作业的运行速度和集群的资源利用率,无服务计算可以通过使每个阶段都可伸缩以满足其资源需求来解决这一挑战,此外,它还将开发人员从集群管理中解放出来。
Serverless SQLite:数据库。各种自动扩缩容的数据库服务已经存在,但是为了更好地理解无服务计算的局限性,理解是什么使数据库负载难以实现使很重要的。在上下文中,我们考虑第三方能否直接使用云函数实现一个无服务数据库。一个解决方案是在云函数中运行常见的事务数据库,如 PostgreSQL、Oracle 或者 MySQL。然而这马上就遇到了一些挑战,首先无服务计算没有内置的持久性存储,因此我们需要利用一些远程持久性存储,这会带来较大的延迟;其次,假设这些数据库是面向连接的协议,例如数据库作为服务器运行,接受来自客户机的连接,这些假设与现有的云函数运行在网络地址翻译器之后,因此不支持传入的连接相矛盾;最后,虽然许多高性能数据库依赖于共享内存,但云函数是独立运行的,因此不能共享内存,虽然无共享的分布式数据库不需要共享内存,但它们希望节点保持在线并可直接寻址。所有这些问题都对在无服务计算的基础上运行传统数据库软件或实现相同的功能提出了重大挑战,因此我们希望数据库仍然保留 BaaS。
这些应用程序希望使用无服务计算的一个关键原因是细粒度的自动扩缩容,因此资源利用率与每个应用程序的不同需求紧密匹配,表5总结了这五个应用程序的特征、挑战和解决方案,接下来我们将使用它们来确定当前无服务计算状态中的四个限制。
3.1 Inadequate storage for fine-grained operations
无服务平台的无状态特性使得很难支持具有细粒度状态共享需求的应用程序,这主要是由于云提供商提供的现有存储服务的限制,表6总结了现有云存储服务的属性。

对象存储服务(如AWS S3、Azure Blob Storage 和 Google 云存储)都具有很高的可伸缩性,并且提供廉价的长期对象存储,但是具有较高的访问成本和访问延迟,根据最近的测试,所有这些服务读取或写入小对象至少需要10毫秒。关于 IOPS,在最近限制增加之后,S3 提供了高吞吐量,但也带来了高成本,维持 10 万个 IOPS 的成本为 30 美元/分钟,比运行 AWS ElastiCache 实例要高 3 到 4 个数量级。这样的 ElastiCache 实例提供了更好的性能和毫秒级的读写延迟,并且每个实例都配置了超过 100K IOPS 来运行单线程的 Redis 服务器。
键值数据库提供了高 IOPS,例如 AWS DynamoDB、谷歌云存储,但是价格很高,并且需要很长的时间来进行扩容。最后,尽管云提供商提供基于流行的开源项目(如 Memcached 或 Redis)的内存存储实例,但它们不具备容错能力,也不像无服务计算平台那样能够自动扩缩容。
如表5所示,在无服务基础设施上构建的应用程序需要具有透明供应的存储服务,这相当于计算资源的自动扩缩容。不同的应用程序对持久性和可用性可能会有不同的要求,并且在延迟或者其他性能指标方面有所不同,我们认为这需要开发临时的和持久的无服务存储选项,我们将在第四章中进一步讨论。
3.2 Lack of fine-grained coordination
为了进一步支持有状态应用,无服务框架需要提供一种方法来协调任务。例如如果任务 A 使用任务 B 的输出,那么即使 A 和 B 位于不同的节点上,也必须有办法让 A 知道它的输入何时可用,很多保障数据一致性的协议也需要类似的协调。
现有的云存储服务都没有通知功能,虽然云服务提供商提供了独立的通知服务,比如 SNS 和 SQS,但这些服务会显著地增加延迟,有时会延迟数百毫秒,此外,当用于细粒度协调时,它们的成本可能很高。已经有人提出了一些系统,比如 Pocket,它们没有这些缺点,但是还没有被云提供商采用。
同样的,应用程序要么管理一个基于 VM 的系统通知(例如在 ElastiCache 或 SAND 中),或者实现自己的通知机制(例如在 ExCamera 中的那样),使得云函数能够通过长期运行的 VM 来彼此沟通。这一限制还表明,无服务计算的新形式可能值得研究,例如命名函数实例并允许直接寻址访问它们的内部状态。
3.3 Poor performance for standard communication patterns
在分布式系统中,广播、聚合和 shuffle 是一些最常见的通信原语,这些操作经常被机器学习训练和大数据分析所使用,图2显示了基于 VM 和基于函数的通信模式。

使用基于 VM 的解决方案,在同一个实例上运行的任务都可以共享数据广播的副本,或者在将部分结果发送到其他实例之前执行本地聚合,因此广播和聚合操作的通信复杂度为 O(N),其中 N 是系统中 VM 实例的数量。然而,对于云函数,这种复杂度为 O(NK),其中 K 是每个 VM 中的函数数量。这种操作在 shuffle 操作中更为显著,在基于 VM 的解决方案中,所有本地任务都可以组合它们的数据,这样两个 VM 实例之间就只有一条消息,假设发送方和接收方的数量相同,则产生 NN 条消息,对于云函数来说,我们需要发送 (NK)(N*K) 条消息,由于现有函数拥有的核数量比 VM 少的多,K 通常在 10 到 100 之间。因为应用程序无法控制云函数的位置,因此无服务计算应用可能需要发送比同等的基于 VM 的方法多 2-4 个数量级的数据。
3.4 Predictable Performance
尽管云函数的启动延迟比传统的基于 VM 实例要低得多,但是对于某些应用来说,启动新实例时的延迟可能很高。影响冷启动延迟的因素有三个:1)启动云函数所需要的时间;2)初始化函数的软件环境所需要的时间,如加载 Python 库;3)用户代码中特定应用程序的初始化。后两个需要的时间会更高一些,虽然启动一个云函数可能需要不到1秒,但加载所有应用程序库可能需要几十秒。
性能可预测性的另一个障碍是硬件资源的可变性,这是由于云提供商选择底层服务器的灵活性,在我们的实验中,我们有时会获得来自于不同硬件的 CPU 资源,这种不确定性暴露了云提供商希望最大化资源利用率和性能可预测之间的权衡。
4 What Serverless Computing Should Become
既然我们已经解释了当下的无服务计算及其局限性,让我们展望未来,了解如何将其优势应用到更多的应用中。研究人员已经开始着手解决上面提到的问题,并探索如何改进无服务平台和运行在其之上的负载性能。在伯克利的一些同事和我们的一些工作强调了分布式系统、机器学习、编程模型的在无服务计算中的一些机遇和挑战。在这里,我们将更加广泛地讨论如何增加能够一些应用和硬件类型,使得无服务计算更好的运行,并在五个领域中确定研究所遇到的挑战:抽象、系统、网络、安全和体系结构。
4.1 Abstraction challenges
资源需求:使用当下的无服务产品时,开发人员需要指定云函数需要的内存大小和执行时间限制,但是不需要指定其他资源。这些抽象阻碍了那些希望在一些指定资源(如 CPU、GPU 或其他类型的加速器)方面有更多控制权的人。一个方法是让开发者自己去明确指定这些资源需求,但是这将使云提供商更难通过统计多路复用的方式来实现高利用率,因为它对函数的调度施加了更多的约束,同时这也违背了无服务计算中让开发者从管理云应用中释放出来的理念。
更好的替代方法是提高抽象级别,让云提供商推断资源需求,而不是让开发人员指定它们。为此,云提供商可以使用多种方法,从静态代码分析、分析以前的运行情况,到动态(重新)编译,将代码重新定向到其他体系结构。当解决方案必须与高级语言运行时使用的垃圾自动回收交互时,自动向函数提供适当大小的内存量就非常有吸引力,但也特别具有挑战性。一些研究表明,这些语言运行时可以继承进无服务平台。
数据依赖:当下的云函数平台并没有云函数之间数据依赖的先验知识,更不用说这些函数之间可能存在数据交换,这可能会导致次优的任务放置,从而导致低效的通信模式,如 MapReduce 和 numpywren 示例所示(参见第三章)。
解决这一挑战的一种方法是,云提供商公开一个 API 允许应用程序指定其计算图,从而实现更好的放置决策并最小化通信开销、提高性能。我们注意到,许多通用的分布式框架(如 MapReduce、Apache Spark 和 Apache Beam/CLoud Dataflow)、并行 SQL 引擎(例如 BigQuery、Azure Cosmos DB)以及编排框架(例如 Apache Airflow)已经在内部生成了这样的计算图。原则上可以修改这些系统,使其运行在云函数上,并将其计算图公开给云提供商。AWS Step Functions 通过提供状态机语言和 API 在往这个方向前进。
4.2 System challenges
High-performance, affordable, transparently provisioned storage:正如第三章和表 5 中所讨论的,我们可以看到两种截然不同的无编址存储器需求,Serverless Ephemeral Storage 和 Serverless Durable Storage。
临时性存储(Ephemeral Storage) 。在第三章中的前四个应用程序受到云函数之间传输状态的存储系统的速度和延迟所限制,虽然它们的容量需求各不相同,但是都需要这样的存储来在应用生命周期中维护应用的状态,应用完成后,可以丢弃状态,这种临时存储也可以在其他应用中作为缓存。
为无服务应用提供临时存储的一种方法是使用优化的网络栈构建分布式内存服务,以保证微秒级的延迟。该系统可以使应用的函数在其生命周期内有效地存储和交换,这样的内存服务需要根据应用程序的需求自动扩展存储容量和 IOPS。这样的服务独特之处在于,它不仅需要透明地分配内存,还需要透明地释放内存,特别是当应用终止或失败时,应该自动释放分配给该应用的存储。这种类似于操作系统在进程完成(或崩溃)时自动释放进程分配的资源,此外,这种存储必须提供跨应用的访问保护和性能隔离。
RAMCloud 和 FaRM 表明,构建内存存储系统是可能的,该系统可以提供微秒级延迟,并支持每个实例数十万次 IOPS。它们通过优化整个软件栈和利用 RDMA 来最小化延迟并实现这种性能,但是它们要求应用程序显示地提供存储,也不提供多个租户之间的强隔离。最近的另一项工作 Pocket 旨在提供临时存储的抽象,但也缺乏自动扩缩容,需要应用预先分配存储。
通过利用多路复用,这种临时存储可以比当今的 serverful 计算更节省内存,对于无服务计算,如果应用需要的内存少于分配的 VM 实例聚合的内存,那么这些内存就会被浪费,相反对于共享内存服务,一个无服务应用程序没有使用的内存都可以分配给另一个应用使用。事实上,多路复用甚至可以使单个应用程序受益:在 serverful 计算中,属于同一应用程序的运行在另一个 VM 上的程序不能使用 VM 未使用的内存,而在共享内存服务的情况下它可以。当然,即使没有无服务计算,如果云函数不使用它的整个本地内存,也可能存在内部碎片,在某些情况下,将云函数应用的状态存储在共享内存服务中可以减轻内存碎片化。
持久性存储(Durable Storage) 。与其他应用程序一样,我们的无服务数据库应用受到存储系统的延迟和 IOPS 的限制,但它也需要长期的数据存储和文件系统的可变状态语义。虽然很可能数据库功能(包括 OLTP)将越来越多地座位 BaaS 提供,但是我们认为这个应用代表了好几种应用程序,这些应用程序需要比临时存储更长的保留时间和更强的持久性。要实现高性能的无服务持久性存储,一种方法是利用基于 SSD 的分布式存储和分布式内存缓存。最近的一个系统实现了这些目标,叫做 Anna key-value 数据库,它通过组合多个现有的云存储产品实现了成本效率和高性能,这种设计的一个关键挑战是在存在大量长尾访问分布的情况下实现低长尾延迟,因为内存缓存容量可能比 SSD 容量低得多。使用这种微秒级访问延迟的存储技术,正在成为解决这一挑战的办法。
与无服务临时存储类似,这种服务应该透明的提供并应确保应用程序和租户之间的隔离,以确保安全性和可预测的性能。然而,无服务临时性存储当应用终止时将回收资源,无服务持久性存储只能显示地释放资源(例如 “delete” 或 “remove” 命令),就像在传统的存储系统中,此外,它必须确保持久性,以便任何公认的写操作都能保证容错。
最小化启动时间 。启动时间分为三个部分:(1)调度并启动资源来运行云函数;(2)下载应用软件的运行时环境来运行函数代码(例如操作系统、库);(3)执行特定于应用程序的启动任务,如加载和初始化数据结构和库。由于创建一个独立的执行环境以及配置客户的 VPC 和 IAM 策略,资源调度和初始化可能会导致严重的延迟和开销。云提供商最近都致力于通过开发新的轻量级隔离机制来减少启动时间。
减少(2)的一种方法是利用 unikernels,Unikernels 通过两种方式消除了传统操作系统带来的开销。首先,不像传统操作系统那样动态监测硬件、应用配置和分配数据结构,Unikernels 通过为运行的硬件预先配置和静态分配数据结构来压缩这些开销;其次,Unikernels 只包含应用程序严格要求的驱动程序和系统库,这比传统操作系统占用的内存要少得多。值得注意的是,由于 Unikernels 是为特定的应用程序定制的,所以当运行多个标准化内核的实例时,它们无法实现一些可能的效率,例如在同一个 VM 上的不同云函数之间共享内核代码页,或者通过提前缓存减少启动时间。减少(2)的另一种办法是动态地、增量地加载应用程序调用的库,例如通过 Azure 函数中使用的共享文件系统启用库。
特定应用程序的初始化(3)是程序员的责任,但是云提供商可以在其 API 中包含一个准备就绪信号,以避免在开始处理之前就将负载发送给函数实例,更广泛地说,云提供商可以在函数真正被调用前的一小段时间里启动任务。这对于与客户无关的任务(例如使用流行的操作系统和一组库启动 VM)很有效,因为此类实例的 “warm pool” 可以在租户之间共享。
4.3 Networking challenges
如第三章和图 2 所示,云函数会给流行的通信原语(如广播、聚合和 shuffle)带来很大的开销,假设我们可以将 K 个云函数打包到一个 VM 实例上,一个云函数版本将发送 K 倍于实例版本的信息,并且在 shuffle 时发送 K*K 多的信息。
有以下几种方法可以应对这一挑战:
为云函数提供更多的 CPU 核。类似于 VM 实例,多个任务可以在通过网络发送数据之前或接收数据之后在这些核之间组合和共享数据;
允许开发人员显示地将云函数放在同一个 VM 实例上。提供应用程序可以直接使用的分布式通信原语,以便云提供商可以将云函数分配给同一 VM 实例;
让应用程序提供一个计算图,使云提供商能够定位云函数,以最小化通信开销(参见上面的 “抽象挑战”)
需要注意的是,前两个建议可能会降低云提供商放置云函数的灵活性,从而降低数据中心的利用率,可以说,它们还违背了无服务计算的精神,迫使开发人员考虑系统管理。
4.4 Security challenges
无服务计算重新划分了安全职责,将其中许多职责从云用户转移到云提供商,而没有从根本上改变它们。然而,无服务计算还必须解决应用分解后多租户资源共享所固有的风险。
调度随机化和物理隔离。物理混合部署是硬件级别侧通道或 Rowhammer 攻击的核心,作为这类攻击的第一步,攻击者需要确认与受害者在同一物理主机上是混部的,而不是随意攻击陌生人。云函数的短暂性可能会限制攻击者识别并行运行的目标的能力,一个随机的 adversary-aware 调度算法可能会降低攻击者和受害者混部在一起的风险,使得这种攻击更佳困难。然而,故意阻止物理混部可能与作业放置来优化启动时间、资源利用率或通信相冲突。
细粒度安全环境。云函数需要细粒度的配置,包括获得私钥、存储对象,甚至是本地的临时资源,这需要从现有的 serverful 应用转换安全策略,并为在云函数中动态使用提供易表达的安全接口。例如,一个云函数可能必须将安全特权委托给另一个云函数或云服务,使用基于加密保护的访问控制机制非常适合这种分布式安全模型。最近的工作建议在多方设置中使用信息流控制实现跨函数的访问控制,如果为云函数动态地创建短期密钥和证书,则为安全原语提供分布式管理的挑战将会加剧。
在系统级,用户需要对每个函数进行更细粒度的安全隔离,至少可以选择这样做。提供函数级别的沙箱所面临的挑战在于,在不缓存执行环境的情况下保持很短的启动时间,而不会在重复函数调用之间共享状态。一种可能是给实例建立本地快照,这样每个函数都可以从干净的状态开始。另外,轻量级虚拟化技术开始被无服务提供商采用:库操作系统(包括 gVisor)在用户空间的 “shim layer” 中实现系统 API,而 unikernel 和 microVMS(包括 AWS Firecracker)简化了客户内核并帮助减少攻击。与以秒为单位测量的 VM 启动时间相比,这些隔离技术将启动时间减少到几十毫秒。这些解决方案是否能在安全性方面与 VM 对等还有待证明,我们希望寻找具有低启动开销的隔离机制,这将是当前研究和开发的一个活跃领域。从积极的角度来看,在无服务计算中,提供管理和短生命周期的实例可以使得漏斗更快地得到修补。
对于那些想要保护自己不受邻居攻击的用户,一种解决方案是要求物理隔离。最近的硬件攻击(例如 Spectre 和 Meltdown)也是保留整个 CPU 核甚至整个物理机来吸引用户。云提供商可以为用户提供一个高级选项,让他们在专用于自己的物理机上启动函数。
Oblivious serverless computing。云函数可以通过通信泄露其访问模式和时间信息。对于 serverful 应用,通常以批处理方式检索数据,并在本地缓存,相反的是,因为云函数都很短暂并且广泛地分布在整个云上,网络传输模式可以向网络攻击者泄露更多敏感的信息,即使负载是端到端加密的。将无服务应用分解为许多小函数的趋势加剧了这种安全性暴露,虽然主要的安全问题来自外部攻击者,但是通过采用 oblivious 算法可以保护网络模式不受员工的攻击,不幸的是,这些方法的开销往往很高。
4.5 Computer architecture challenges
硬件异构性、定价、易于管理。主导云计算的 x86 位处理器的性能几乎没有提高,在 2017年,单个项目的性能提升仅为 3%,假设按照这种趋势继续下去,在 20 年内性能不会翻倍。同样,每个芯片的 DRAM 容量正在接近极限,现在有 16 Gbit 的 DRAM 在出售,但是要制造一个 32 个 Gbit 的 DRAM 芯片几乎是不可能的。这种缓慢变化带来的一线希望是,随着旧电脑的磨损,供应商可以更换它们,而对当前的无服务市场几乎没有影响。
通用微处理器的性能问题不会降低对更快的计算的需求。有两条路可以走,对于用 JavaScript 或 Python 等高级脚本语言编写的函数,软硬件协同设计可以使特定于语言的定制处理器的运行速度提高 1-3 个数量级;另一条路是特定领域的体系结构(DSA)。DSA 针对特定的问题领域进行了定制,并为该领域提供了显著的性能和效率提高,但是对于该领域之外的应用性能很差。GPU 长期以来一直被用来加速图像,我们开始看到 DSAs 用于机器学习,比如 TPU。TPU 的性能可以比 CPU 高出 30 倍,这些示例只是众多示例中的第一个,因为使用 DSA 增强用于不同领域的通用处理器将成为规范。
正如在 4.1 节中提到的,我们看到了两种无服务计算方法来支持即将到来的硬件异构性:
- Serverless 可以包含多种实例类型,每个计费单元的价格取决于使用的硬件;
- 云提供商可以自动选择基于语言的加速器和 DSAs。这种自动化可以隐式地基于云函数中使用的软件库和语言来完成,比如用于 CUDA 代码的 GPU 硬件和用于 TensorFlow 代码的 TPU 硬件,或者云提供商可以监视云函数的性能,并在下次运行时将它们迁移到最合适的硬件上。
对于 x86 的 SIMD 指令,无服务计算正以一种较小的方式面临异构性。AMD 和英特尔通过增加每个时钟周期执行的操作数量和添加新的指令,改进了部分 x86 指令集。对于使用 SIMD 指令的程序,在最新的 Intel Skylake 微处理器上运行带有 512 位宽指令的程序要比在老的 Intel Broadwell 微处理器上运行带有 128 位宽的 SIMD 指令程序快得多。今天,这两个微处理器在 AWS Lambda 中价格相同,但是对于无服务计算用户来说,目前没有办法表明他们想要更快的 SIMD 硬件,在我们看来,编译器应该建议哪种硬件是最好的。
随着加速器在云中越来越流行,无服务计算的云提供商不能在忽视异构带来的困境,特别是在可能的补救措施存在的情况下。
5 Fallacies and Pitfalls
本章使用 Hennessy 和 Patterson 的 Fallacy 和 Pitfall 风格。
Fallacy。因为一个 AWS Lambda 云函数实例与内存大小相同的 on-demand AWS t3.nano 实例每分钟开销要多 7.5 倍,无服务计算比 serverful 云计算价格更高。
无服务计算的优点在于价格中包含了实际使用的资源外还包括了整个系统管理,包括可用性冗余、监控、日志记录和弹性伸缩。云提供商的数据显示,当客户将应用迁移到无服务环境中时,可以节省 4-10 倍的成本,并且其在相同功能下远不止一个 t3.nano 实例。对于一个单点故障,其 credit 系统会将其限制在每个小时最多使用 6 分钟 CPU,所以它可以在负载高峰期拒绝服务,而 serverless 可以很容易应用这个负载高峰。Serverless 可以更细粒度地进行计费,包括自动扩缩容,因此在计算量上可能更加高效,因为云函数在没有被调用时是不计费的,所以 serverless 可能更加便宜。
Pitfall。无服务器计算可能存在成本不可预测的情况。
对于一些用户来说,无服务计算采用即付即用的计费模型的一个缺点是成本不可预测。这与许多组织管理预算的方式不太一致,当公司想要知道下一年无服务计算的成本预算是多少,并来批准预算时就不太好制定预算。这种需求是合理的,云提供商可能会通过提供基于 bucket 的定价方式来缓解这个问题,类似于电话公司为特定使用量提供固定费率计费方式一样。我们还相信,随着越来越多的组织使用无服务计算,他们将能够基于历史来预测他们的成本,就像当今公共事业服务(如电力)所使用的办法。
Fallacy。由于无服务计算编程是用高级语言编写的(例如 Python),所以很容易在无服务计算提供商之间移植应用。
在不同的无服务计算提供商之间,不仅仅是函数的调用语义和打包方式不同,许多无服务应用也依赖于其生态系统的专有 BaaS 服务(例如对象存储、键值数据库、身份验证、日志监控等),缺乏统一标准化。为了实现可移植,无服务计算的用户将不得不提出并接受某种标准 API,例如 POSIX 试图为操作系统提供这种 API。Google 的 Knative 项目就是为了解决这个问题,它为应用开发者提供了一组统一的原语,以便在部署环境中使用。
Pitfall。与使用 serverful 计算相比,使用无服务计算时,供应商 lock-in 可能会更强。
这个陷阱是前一个谬论的结果,如果一直很困难,那么供应商 lock-in 是可能的,一些框架承诺通过跨云支持来减轻这种 lock-in。
Fallacy。云函数不能处理非常低延迟的应用程序,这需要预测其性能。
Serverful 实例能够很好地处理这种低延迟应用的原因是,它们总是处于待命状态,所以当它们接收到请求时,可以快速响应。我们注意到,如果一个云函数的启动性能对于给定的应用来说还不够好,那么可以使用类似的策略:通过定期执行云函数来预热云函数,以确保在任何给定时间都有足够的云函数。
Pitfall。很少有所谓的“弹性”服务能够满足无服务计算的实际灵活性需求。
“弹性” 是当下很流行的一个术语,但是它被应用于那些伸缩性不如无服务计算服务的服务。我们对那些可以快速改变它们容量大小的服务很感兴趣,并且用户的干预度最小,在不使用时可以“缩容到0”。例如,尽管 AWS ElastiCache 名字中有弹性一词,但它之允许实例化一个整数个 Redis 实例。其他“弹性”服务需要显示的进行容量供应,有些服务需要花费许多时间来响应需求的变化,或者之扩展到有限的范围。当用户构建一个高弹性的应用,并且包含数据库、搜索索引或者有有限弹性的 serverful 应用时,他们会失去很多无服务计算的优势,如果没有一个量化的、被广泛接受的技术定义或度量(有助于比较或组合系统),“弹性” 将仍然是一个模糊的词汇。
6 总结和预测
通过提供一个简化的编程环境,无服务计算加强了云的易用性,从而吸引更多的人。无服务计算由 FaaS 和 BaaS 服务组成,标志着云编程的成熟,它消除了 serverful 计算强加给应用开发人员的资源管理和优化的工作,这类似于四十多年前从汇编语言迁移到高级语言的转变。
我们预测无服务计算的使用将会激增,我们还预测,将混合云应用将随着时间的推移而减少,尽管由于监管约束和数据治理规则,一些部署可能会持续。
虽然无服务计算已经取得了成功,但是我们明确了一些其可能遇到的挑战,如果这些困难能得以解决,无服务计算将在更大的范围内被广泛使用。第一步是无服务计算的临时存储,它必须以合理的成本提供低延迟和高 IOPS,但不需要提供经济的长期存储。第二类应用程序将受益于无服务器的持久性存储,新的非易失性内存技术可能对这种存储系统有所帮助。低延迟的信令服务和对流行通信原语的支持将使得无服务计算受益匪浅。
未来无服务计算的两个挑战在于如何提高安全性和适应来自特殊用途处理器的成本性能改进,在这两种情况下,无服务计算的特性可能有助于解决这些挑战。物理上的共存是侧道攻击的必要条件,但是在无服务计算中很难确定函数的位置,而且很容易地进行位置随机化。云函数是使用高级语言进行编程的,例如 JavaScript、Python 或 TensorFlow,这些高级语言提升了编程的抽象层级并且更加容易进行创新,进而使得底层的硬件可以带来开销和性能的提升。
在 《The Berkeley View on Cloud Computing》 一文中作者预测,2009 云计算所面临的挑战将得到解决,并将蓬勃发展。云业务现在正以每年 50% 的速度增长,并且实时证明,云提供商的利润非常丰厚。
最后,我们对未来十年的无服务计算做出如下预测:
- 我们希望能创建新的 BaaS 存储服务,在无服务计算上能扩展更多的应用类型,这样的存储将与本地块存储的性能相匹配,并且具有临时性和持久性存储的特性,我们将看到计算机硬件的异构性要比传统的 x86 微处理器强得多。
- 我们希望无服务计算可以比 serverful 计算更容易安全地编程,这得益于高级编程的抽象和云函数的细粒度隔离。
- 我们没有看到无服务计算的成本应该高于 serverful 计算的根本原因,因此我们预测计费模型将会继续发展,这样几乎任何应用程序可以运行在任何规模上,并且使得无服务计算的成本都不会增加,甚至可能更少。
- 未来的 Serverful 计算将会为 BaaS 提供便利,事实证明,例如像 OLTP 数据库或通信原语(如队列)这类应用,很难在无服务计算之上编写,未来可能会作为云提供商所提供服务的一部分。
- 虽然 serverful 计算不会消失,但随着无服务计算解决了当前限制,这部分云计算的相对重要性将会下降。
- 无服务计算将成为云时代的默认计算范式,在很大程度上取代 serverful 计算,从而结束客户机-服务器时代。
欢迎大家关注我的知乎专栏,进击的云计算。