《视觉SLAM十四讲》读书笔记--前八讲
一.初识SLAM
1.单目相机局限性:平移之后才能计算深度以及无法确定真实尺度。
双目相机测量原理:由两个单目相机构成,由两个相机之间的距离-基线估计每个像素的空间位置。基线距离越大测量的越远。
局限性:深度量程和精度受基线和分辨率限制,视差计算量大非常耗资源(主要问题),需GPU和FPGA加速才能实时输出 图像距离信息。
深度相机(RGB-D)利用光的发射与接受物理手段测量物体离相机的距离。
局限性:测量范围窄、噪声大、视野小、容易受日光干扰、无法测量投射材质。
2.SLAM框架
传感器数据->视觉里程计->后端非线性优化->回环检测->建图
视觉里程计:任务是估算相邻图像间相机的运动,以及局部地图的样子。
后端优化:理论上来说,如果视觉里程计模块估计的相机的旋转矩阵R和平移向量t都正确,就能得到完美的定位和建图了。但 实际试验中,我们得到的数据往往有很多噪声,且由于传感器的精度、错误的匹配等,都对造成结果有误差。并且 由于我们是只把新的一帧与前一个关键帧进行比较,当某一帧的结果有误差时,就会对后面的结果产生累计误差 (累计漂移),导致误差越来越大。为了解决这个问题,引入后端优化。
任务:从带有噪声的数据中估计整个系统的状态(相机自身轨迹及地图)以及这个状态估计的不确定性-最大后验概率估计。
回环检测:判断是否之前曾到达过这个位置,主要解决位置估计随时间漂移。如果有回环,交给后端去处理。
在vSlam中,前端和计算机视觉更为相关,涉及到图像的特征提取与匹配等,后端主要是滤波与非线性优化算法。
建图:根据不同需要建图形式及算法不同,包括度量地图和拓扑地图两种。
度量地图:稀疏地图可用来定位,选取路标mark。稠密地图可用来导航
3.SLAM系统的数学形式
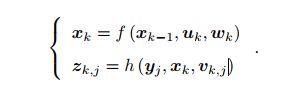
u为运动测量的读数,z为传感器的读数,y为路标(特征)位置,x为相机位置,w和v为噪声数据。
根据f和h分为是否为线性,根据噪声数据的分布分为是否为高斯分布。其中线性高斯最为简单,无偏最有估计可以有卡尔 曼滤波器给出,而非线性非高斯以扩展的卡尔曼滤波器(将系统线性化,并以预测-更新两大步骤求解)和非线性优化(代 表BA和图优化)来求解。
二.三维空间刚体运动
1.向量内积表示向量间的投影关系。向量外积(只对三维向量有定义)可以用来表示旋转,方向垂直于这两个向量,大小 为|a||b|sin
2.坐标系间的欧式变换
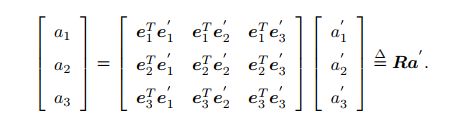
其中R为旋转矩阵,行列式为1的正交矩阵,可以描述相机的旋转,定义如下:
![]()
由于旋转矩阵为正交阵,它的逆(即转置)描述了一个相反的旋转。
欧式变换由平移和旋转构成,旋转可由旋转矩阵SO(3)描述,平移由一个R(3)向量描述,完整的坐标变换关系为:
![]()
3.变换矩阵与齐次坐标
由2中表达式进行描述在进行多次变换时表述很麻烦,因此将旋转和平移放到同一矩阵中SE(3)中
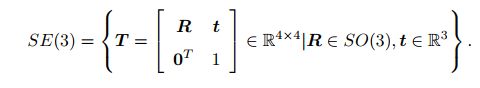
与SO(3)相同。该矩阵的逆表示一个反向的变换:
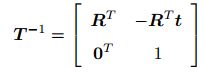
4.旋转变换与欧拉角
任意旋转都可以用一个旋转轴和一个旋转角来刻画,于是,我们可以使用一个向量,其方向与旋转轴一致,而长度等于旋转角。这种向量,称为旋转向量。假设有一个旋转轴为 n,角度为 θ 的旋转,显然,它对应的旋转向量为 θn。由旋转向量到旋转矩阵的过程R = cos θI + (1 - cos θ) nnT + sin θn^。符号 ^ 是向量到反对称的转换符。反之,我们也可以计算从一个旋转矩阵到旋转向量的转换。对于转角 θ,有:
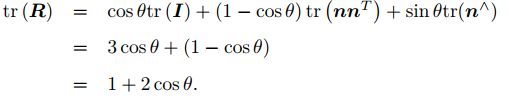
![]()
5.四元数
四元数既是紧凑的,也没有奇异性,但表达不够直观,运算复杂。表示形式及约束如下:
![]()
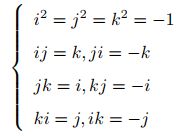
单位四元数(模长为1)表示三维空间的任意一个旋转,乘以i意味着旋转180°,ixi=-1意味着绕i轴旋转360°之后得到了一个相 反的东西,而这个东西旋转两周才会和原来的样子相同。
某个旋转绕单位向量![]() 进行角度为θ的旋转,那么这个旋转的四元数形式为:
进行角度为θ的旋转,那么这个旋转的四元数形式为:
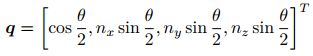
反之我们也可从单位四元数中计算出对应的旋转轴及旋转角:

任意的旋转都可以由两个互为相反数的四元数表示,θ为0时,则得到一个没有任何旋转的实四元数:
![]()
四元数的运算:加减法、乘法、共轭(虚部取反)、模长(乘积的模等于模的乘积)、求逆(两者相乘为实四元数1、数乘与 点乘(四元数每个位置上的数值相乘)
用四元数表示旋转:一个空间三维点![]() ,由轴n,角度θ指定的旋转,则旋转后的点p'可由下列表示:
,由轴n,角度θ指定的旋转,则旋转后的点p'可由下列表示:
![]()
![]()
![]()
计算结果的实部为0,虚部的三个分量表示旋转后3D点的坐标。
四元数到旋转矩阵的转换:
![]()
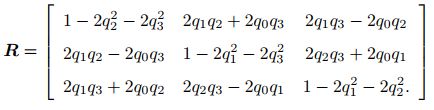
旋转矩阵到四元数的转换:
![]()
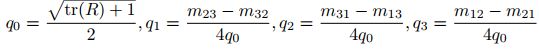
因为q和-q表示同一个旋转,因此一个R对应的四元数表示并不唯一。
三.李群与李代数
1.目的:通过观测数据求最优的相机位姿估计,即求最优的R与t(旋转与平移),而旋转矩阵自身带有约束(正交且行列式为1)在做优化变量时会引入额外的约束,使优化变得困难,通过李群-李代数之间的转换,变成无约束问题。
2.李群:指具有连续(光滑)性质的群。一个刚体能够连续在空间中运动,所以都是李群。
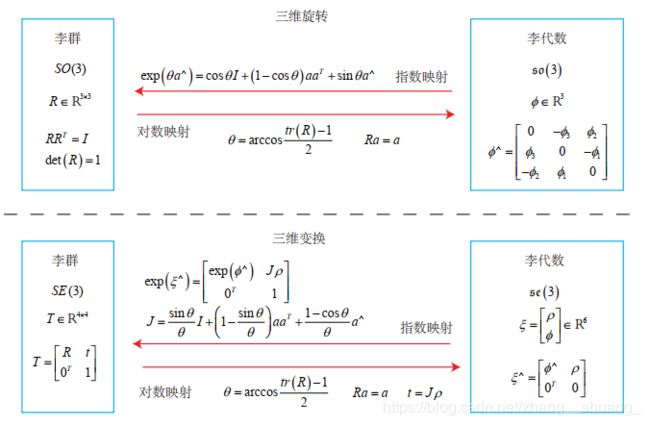
so(3) 实际上就是由所谓的旋转向量组成的空间,而指数映射即罗德里格斯公式。通过它们,我们把so(3) 中任意一个向量对应到了一个位于 SO(3) 中的旋转矩阵。
是否对于任意的 R 都能找到一个唯一的 ϕ?很遗憾,指数映射只是一个满射。这意味着每个SO(3) 中的元素,都可以找到一个 so(3) 元素与之对应;但是可能存在多个 so(3) 中的元素,对应到同一个 SO(3)。至少对于旋转角 θ,我们知道多转 360 度和没有转是一样的——它具有周期性。但是,如果我们把旋转角度固定在 ±π 之间,那么李群和李代数元素是一一对应的。
3.李代数求导与扰动模型
BCH近似:
![]()
![]()
如果我们把 T 当成一个普通矩阵来处理优化,那就必须对它加以约束。而从李代数角度来说,由于李代数由向量组成,具有良好的加法运算。因此,使用李代数解决求导问题的思路分为两种:
a. 用李代数表示姿态,然后对根据李代数加法来对李代数求导。
b. 对李群左乘或右乘微小扰动,然后对该扰动求导,称为左扰动和右扰动模型。
李代数的求导模型:
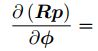
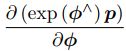
![]()
扰动模型(左乘):

![]()
四.相机与图像
1.相机成像过程:物体反射或发出的光线,穿过相机光心后,投影在相机的成像平面上,相机的感光器件接受到光线后产生了测量值,就得到了像素,形成了照片。
2.针孔模型,描述了一束光线通过针孔后在针孔背面投影成像的关系。由于相机镜头上透镜的存在,会使得光线投影到成像平面的过程中产生畸变。因此以下用针孔和畸变两个模型来描述整个投影过程,通过两个模型可以把外部的三维点投影到相机内部成像平面,构成了相机的内参数。
3.针孔模型
像素坐标系与成像平面之间相差了一个缩放和一个原点的平移。像素坐标[u,v]可表示为“
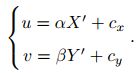
把αf、βf合并后:
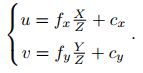
f的单位是米,α、β的单位为像素每米,所以fx、fy的单位为像素,把上式写成齐次坐标矩阵形式:

K即为相机的内参数矩阵。
相机的位姿由它的旋转矩阵R和平移向量t来描述,于是有
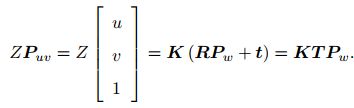
上式描述了P的世界坐标到像素坐标的投影关系。相机的位姿又称为相机的外参数,会随着运动而改变,是SLAM中待估计的 目标,代表着机器人的轨迹。
P与T相乘表示将一个世界坐标系转换到相机坐标系,归一化平面后(t变1)再与K相乘表示(经过内参)就得到了像素坐标。所以可以把像素坐标[u,v],看成对归一化平面上的点进行量化测量的结果。
4.畸变模型
由透镜形状引起的畸变称为径向畸变。在实际拍摄中,摄像机的透镜往往使得真实环境中的一条直线在图片中变成了曲线,而且越靠近图像边缘,这种现象越明显。主要分为两大类,桶形畸变和枕形畸变。

桶形畸变是由于图像放大率随着离光轴的距离增加而减小,而枕形畸变恰相反。在两者中,穿过图像中心和光轴有交点的直线形状不变。
除了透镜形状引起的径向畸变外,在相机的组装过程中由于透镜不能和成像平面严格平行也会引入切向畸变。
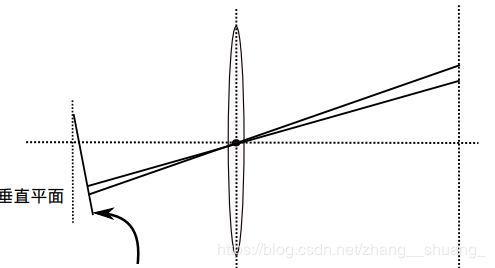
对畸变的校正:
径向畸变,畸变一般的引入k1和k2即可,对于畸变较大的例如鱼眼镜头,加入k3畸变项进行纠正。
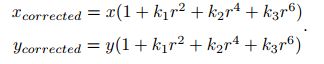
其中p点坐标为[x,y],极坐标表示形式[r,θ],r是p离坐标系原点的距离,θ是与水平轴的夹角。径向畸变可看成r发生 变化,切向畸变可看成θ发生变化。
切向畸变:
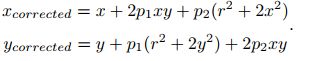
总体校正可表示为:
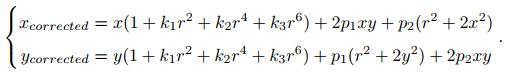
5.单目相机成像过程总结
1)世界坐标系固定点p,世界坐标为Pw
2)相机在运动,P的相机坐标为P'=RPw+t
3)此时P'坐标仍有X,Y,Z三个量,把他们投影归一化平面Z=1上,得到归一化相机坐标Pc=[X/Z,Y/Z,1]
4)最后Pc经过内参后,对应得到像素坐标:Puv=KPc
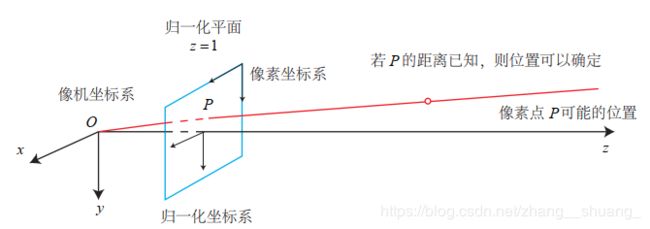
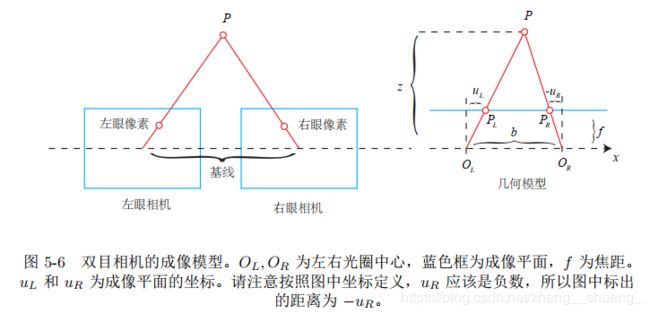
6.双目相机模型
仅根据一个像素是无法确定这个空间点的具体位置的,因为所有点都可以投影到该像素上,只有当P的深度确定时才可确定具体位置。双目相机测量深度原理,即同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。
![]()
整理得:
![]()
上式中,d为左右图得横坐标之差,称为视差,根据视差可以估计一个像素离相机的距离。视差与距离成反比:视差越大,距离越近。由于视差最小为一个像素,因此双目的深度存在一个理论上的最大值,由fb确定。同时基线越长,能测到的距离越远。但是视差计算比较困难,需要确切的知道左边图像上某个像素出现在右眼图像上的哪一个位置,其计算量和精度都会成为问题,而且只有在图像纹理变化丰富的地方才能计算视差,由于计算量的原因,双目深度估计仍需使用GPU或FPGA来计算。
7.RGB-D相机模型
1.按原理可分为两大类:
1)通过红外结构光来测量像素距离,根据返回的结构光图案,计算物体离自身的距离。
2)飞行时间法(Time-of-flight,TOF),相机向目标发射脉冲光,根据发送到返回之间的光束飞行时间,确定距离。与激光传感器类似,但激光通过逐点扫描,而TOF则可以获得整个图像的深度。
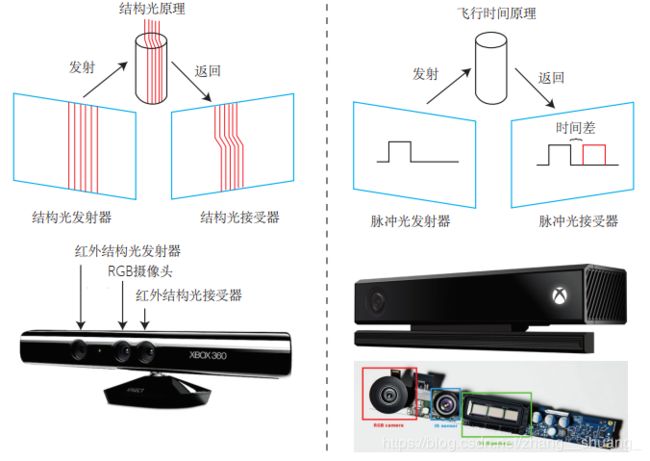
2.在测量深度后,相机会按照生产时各个相机的摆放位置,完成深度和色彩图之间的配对,输出一一对应的彩色图和深度图,我们可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的3D相机坐标,生成点云。
但通过发射-接受的方式,容易受日光或其他传感器发射的红外光干扰,因此不能在室外使用,同时使用多个也会相互干扰,同时对于透射材质的物体也无法测量。
8.图像
灰度图:每个像素位置对应一个灰度值,所以一张宽度为w,高度为h的图像,数学形式可以记成一个矩阵:![]()
彩色图:对于每个像素有R,G,B三个通道构成,每个通道由8位整数表示,因此一个像素占据了24位空间。在OpenCV中,通道的默认顺序为B,G,R,即得到的24位像素时,前8表示蓝色数值,中间8位为绿色,后8位为红色。如果还需表示透明度时,就需要四个通道来表示。
五.非线性优化
1.状态估计问题
在非线性优化中,把所有待估计的变量放在一个状态变量中:![]()
对机器人状态的估计,就是求已知输入数据u和观测数据z的条件下,计算状态x的条件概率分布:![]()
为了估计状态变量的条件分布,利用贝叶斯法则,有:
其中贝叶斯左侧称为后验概率,右侧![]() 称为似然,
称为似然,![]() 称为先验。直接求后验分布很难,但是求一个状态最优估计,使得在该状态下,后验概率最大化则可行:
称为先验。直接求后验分布很难,但是求一个状态最优估计,使得在该状态下,后验概率最大化则可行:![]() 。但是我们并不知道机器人位姿在什么地方,此时就没有了先验,那么可以求解x的最大似然估计:
。但是我们并不知道机器人位姿在什么地方,此时就没有了先验,那么可以求解x的最大似然估计:![]()
直观来讲,似然就是”在现在的位姿下会产生怎样的观测数据“,而最大似然估计,可以理解成”在什么状态下最有可能产生现在观测到的数据“。
2.非线性最小二乘
对于不方便直接求解的最小二乘问题,我们可以用迭代的方式,从一个初始值出发,不断地更新当前的优化变量,使目标函数下降。具体步骤可列写如下:
a. 给定某个初始值 x0。
b. 对于第 k 次迭代,寻找一个增量 ∆xk,使得 ∥f (xk + ∆xk)∥2 达到极小值。
c. 若 ∆xk 足够小,则停止。
d. 否则,令 xk+1 = xk + ∆xk,返回 2
1) 一阶和二阶梯度法:
求解增量最直观的方式是将目标函数在 x 附近进行泰勒展开:
![]()
如果保留一阶梯度,那么增量的方向为:![]()
它的直观意义非常简单,只要我们沿着反向梯度方向前进即可。当然,我们还需要该方向上取一个步长 λ,求得最快的下降方式。这种方法被称为最速下降法。
如果保留二阶梯度信息,那么增量方程为:![]()
求右侧等式关于 ∆x 的导数并令它为零,就得到了增量的解:![]() 该方法称又为牛顿法。
该方法称又为牛顿法。
这两种方法也存在它们自身的问题。最速下降法过于贪心,容易走出锯齿路线,反而增加了迭代次数。而牛顿法则需要计算目标函数的 H 矩阵,这在问题规模较大时非常困难,我们通常倾向于避免 H 的计算。所以,接下来我们详细地介绍两类更加实用的方法:高斯牛顿法和列文伯格——马夸尔特方法。
2) Gauss-Newton
将 f(x) 进行一阶的泰勒展开(请注意不是目标函数 f(x)2):![]()
这里 J(x) 为 f(x) 关于 x 的导数,实际上是一个 m × n 的矩阵,也是一个雅可比矩阵。根据前面的框架,当前的目标是为了寻找下降矢量 ∆x,使得 ∥f (x + ∆x)∥2 达到最小。为了求 ∆x,我们需要解一个线性的最小二乘问题:
![]()
根据极值条件,将上述目标函数对 ∆x 求导,并令导数为零。由于这里考虑的是 ∆x 的导数(而不是 x),我们最后将得到一个线性的方程: ![]()
我们要求解的变量是 ∆x,因此这是一个线性方程组,我们称它为增量方程,也可以称为高斯牛顿方程 (Gauss Newton equations) 或者正规方程 (Normal equations)。我们把左边的系数定义为 H,右边定义为 g,那么上式变为:
![]()
对比牛顿法可见, Gauss-Newton 用 JT J 作为牛顿法中二阶 Hessian 矩阵的近似,从而省略了计算 H 的过程。 求解增量方程是整个优化问题的核心所在。
如果我们能够顺利解出该方程,那么 Gauss-Newton 的算法步骤可以写成:
a. 给定初始值 x0。
b. 对于第 k 次迭代,求出当前的雅可比矩阵 J(xk) 和误差 f(xk)。
c. 求解增量方程: H∆xk = g:
d. 若 ∆xk 足够小,则停止。否则,令 xk+1 = xk + ∆xk,返回 2
3) Levenberg-Marquadt
收敛速度可能会比 Gauss Newton 更慢,被称之为阻尼牛顿法(Damped Newton Method),但是在 SLAM 里面却被大量应用。
该给 ∆x 添加一个信赖区域(Trust Region),不能让它太大而使得近似不准确。如何确定这个信赖区域的范围呢?一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定这个范围:如果差异小,我们就让范围尽可能大;如果差异大,我们就缩小这个近似范围。因此,考虑使用:
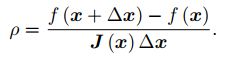
来判断泰勒近似是否够好。 ρ 的分子是实际函数下降的值,分母是近似模型下降的值。如果 ρ 接近于 1,则近似是好的。如果 ρ 太小,说明实际减小的值远少于近似减小的值,则认为近似比较差,需要缩小近似范围。反之,如果 ρ 比较大,则说明实际下降的比预计的更大,我们可以放大近似范围.
于是,我们构建一个改良版的非线性优化框架,该框架会比 Gauss Newton 有更好的效果:

不论如何,在 L-M 优化中,我们都需要解式(6.24)那样一个子问题来获得梯度。这个子问题是带不等式约束的优化问题,我们用 Lagrange 乘子将它转化为一个无约束优化问题:
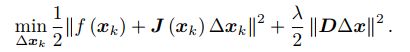
这里 λ 为 Lagrange 乘子。类似于 Gauss-Newton 中的做法,把它展开后,我们发现该问题的核心仍是计算增量的线性方程:
![]()
当参数 λ 比较小时, H 占主要地位,这说明二次近似模型在该范围内是比较好的, L-M 方法更接近于 G-N 法。另一方面,当 λ 比较大时, λI 占据主要地位, L-M更接近于一阶梯度下降法(即最速下降),这说明附近的二次近似不够好。 L-M 的求解方
式,可在一定程度上避免线性方程组的系数矩阵的非奇异和病态问题,提供更稳定更准确的增量 ∆x。
非线性优化问题的框架,分为 Line Search 和 Trust Region 两类。 Line Search 先固定搜索方向,然后在该方向寻找步长,以最速下降法和 Gauss-Newton 法为代表。而 Trust Region 则先固定搜索区域,再考虑找该区域内的最优点。此类方法以 L-M 为代表。实际问题中,我们通常选择 G-N 或 L-M 之一作为梯度下降策略。
3.图优化理论
非线性最小二乘的求解是由很多个误差项之和组成的。然而,仅有一组优化变量和许多个误差项,我们并不清楚它们之间的联。
图优化,是把优化问题表现成图(Graph) 的一种方式。这里的图是图论意义上的图。一个图由若干个顶点(Vertex) ,以及连接着这些节点的边(Edge) 组成。用顶点表示优化变量,用边表示误差项。
g2o步骤:
a. 定义顶点和边的类型;
b. 构建图;
c. 选择优化算法;
d. 调用 g2o 进行优化,返回结果。
六.视觉里程计
1.特征点
图像中比较有代表性的点,这些点在相机视角发生少量变化后会保持不变,所以会在各个图像中找到相同的点。在经典问题中称为路标,在视觉SLAM中,指的是图像特征,特征是图像信息的另一种数字表达形式。
然而在大多数应用中,单纯的角点依然不能满足需求,例如从远处看是角点的地方,走进一看不是角点,或者当旋转相机时,角点的外观会发生变化。因此会人工设计更加稳定的局部图像特征,他们具有如下性质:
1)可重复性:相同区域可以在不同的图像中被找到。
2)可区别性:不同的区域有不同的表达。
3)高效率性:同一图像中,特征点的数量应远小于像素的数量。
4)本地性:特征仅与一小片图片区域相关。
特征点由关键点和描述子两部分组成。关键点是指该特征点在图像中的位置,有的特征点还具有朝向、大小等信息。描述子通常是一个向量,按照某种人为设计的方式,描述该关键点周围像素的信息,本着”外观相似的特征应该有相近的描述子“的原则来设计,因此若两个特征点的描述子在向量空间上的距离相近,就可以认为它们是同样的特征点。
SIFT特征:尺度不变特征变换,充分考虑了在图像变换过程中出现的光照、尺度、旋转等变化,但随之而来的是极大的计算量,因此用的很少。
FAST特征:主要检测局部像素灰度变化明显的地方(只比较亮度),运算快,但是没有描述子。
ORB特征:关键点是一种改进的FAST角点,具有代表性的实时图像特征,有速度极快的二进制描述子BRIEF。
FAST关键点检测过程:
1)在图像中选取像素P,假设他得亮度为Ip
2)设置一个阈值T(比如Ip的20%)
3)以像素p为中心,选取半径为3的圆上的16个像素点
4)假如在选取的圆上有连续的N个点的亮度大于Ip+T或小于Ip-T,那么像素p则被认为是特征点。
缺点:特征点数量很大且不确定,还会有角点集中的问题。
在ORB中,对原始的FAST进行改进,可以指定最终要提取的角点数量N,对原始FAST角点分别计算Harris响应值,最后取前N个具有最大响应值额角点作为最终角点集合。FAST角点不具有方向信息,而且取半径为3的圆存在尺度问题:远处看着是角点的地方接近后看可能就不是角点了,ORB添加了尺度和旋转的描述。尺度不变性由构建图像金字塔,在金字塔的每一层检测角点来实现,特征的旋转由灰度质心法来实现。质心是指以图像块灰度值作为权重的中心,具体操作步骤如下:
1)在一个小图像块B中,定义图像块的矩为:

2)通过矩可以找到图像块的质心:
![]()
3)图像块的几何中心O和质心C,得到的方向向量OC,特征点的方向可以定义为:
![]()
BRIEF描述子:
是一种二进制描述字,它的描述向量由许多个0和1组成,这里的0和1编码了关键点附近的两个元素(比如p和q),如果p比q大,则取1.特征匹配的过程最简单的是暴力匹配,即对每一个特征点计算所有特征点与其距离,然后排序,取最近的一个作为匹配点,描述子距离之间表示了两个特征之间的相似程度。对于二进制的描述子(例如BRIEF),可以使用汉明距离(不同位数的个数)来做为度量。然而,当特征点距离较多或者实时性要求很高时,快速近似最近邻(FLANN)更适合(OpenCV)。
相机位姿求解方法:
1). 当相机为单目时,我们只知道 2D 的像素坐标,因而问题是根据两组 2D 点估计运动。该问题用对极几何来解决。
2). 当相机为双目、 RGB-D 时,或者我们通过某种方法得到了距离信息,那问题就是根据两组 3D 点估计运动。该问题通常用 ICP 来解决。
3). 如果我们有 3D 点和它们在相机的投影位置,也能估计相机的运动。该问题通过 PnP求解
2.2D-2D:对极几何
1.对极约束

其中O1、O2、P三个点可以确定个平面,称为极平面。O1O2连线与像平面的交点称为极点,O1O2称为基线,极平面与两个像平面之间的相交线称为极线。
设P的空间位置为:![]()
根据针孔相机模型,两个像素点p1,p2的像素位置为:![]()
将上式变成齐次坐标:![]()
取: ![]()
![]()

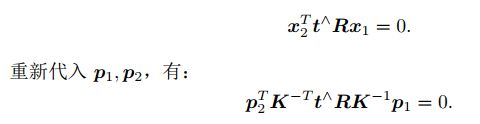
基础矩阵F和本质矩阵E,进一步简化对极约束:![]()
因此相机位姿估计问题变为以下两步:
1)根据配对点的像素位置,求出 E 或 F 。
2)根据E或F求出 R 和 t。
由![]() ,是一个3x3的矩阵,有9个未知数,但其奇异值必定是
,是一个3x3的矩阵,有9个未知数,但其奇异值必定是![]() 形式(这被称为本质矩阵的内在性质)。另一方面,由于平移和旋转各有三个自由度,所以t ^ R共有六个自由度,但由于尺度等价性,E实际只有五个自由度。因此最少需要五对点可以求解E,但是E的内在性质是一种非线性性质,在求解线性方程时会带来麻烦。也可只考虑它的尺度等价性,使用八对点来估计E(经典的八点法)。
形式(这被称为本质矩阵的内在性质)。另一方面,由于平移和旋转各有三个自由度,所以t ^ R共有六个自由度,但由于尺度等价性,E实际只有五个自由度。因此最少需要五对点可以求解E,但是E的内在性质是一种非线性性质,在求解线性方程时会带来麻烦。也可只考虑它的尺度等价性,使用八对点来估计E(经典的八点法)。
考虑到一对匹配点,归一化坐标为![]() ,
,
根据对极约束有:

找到对应的8对点:

因此可以根据估得得本质矩阵E恢复出相机得运动R,t。这是由奇异值分解(SVD)得到得:
![]()
其中U,V为正交阵,Σ为奇异值矩阵,根据E的内在性质,可以知道![]() ,但是在实际求解的线性方程中,可能不满足E的内在性质,而是
,但是在实际求解的线性方程中,可能不满足E的内在性质,而是![]() ,这是可以取
,这是可以取![]() ,相当于把求出来的矩阵投影到E所在的流形上。更简单的做法是取成(1,1,0),因为E具有尺度等价性。
,相当于把求出来的矩阵投影到E所在的流形上。更简单的做法是取成(1,1,0),因为E具有尺度等价性。
单应矩阵H:描述了两个平面之间的映射关系。若场景中的特征点都落在同一平面上(例如墙、地面)在无人机携带的俯视相机或扫死机携带的顶视相机中比较常见,则可以通过单应性来进行运动估计。
特征点落在平面上的方程:![]()
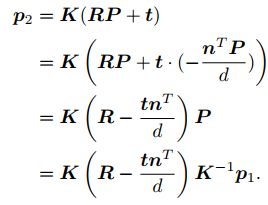
![]()
尺度不确定性:由E具有尺度等价性,分解的t 和 R 也有一个尺度等价性,即在分解中对 t 乘以任意非零常数,分解都成立,因此,我们通常把 t 进行归一化,让它的长度等于 1。对 t 长度的归一化,直接导致了单目视觉的尺度不确定性(Scale Ambiguity),换言之,在单目 SLAM 中,对轨迹和地图同时缩放任意倍数,我们得到的图像依然是一样的。在单目视觉中,我们对两张图像的 t 归一化,相当于固定了尺度。虽然我们不知道它的实际长度为多少,但我们以这时的 t 为单位 1,计算相机运动和特征点的 3D 位置。这被称为单目 SLAM 的初始化。初始化之后的轨迹和地图的单位,就是初始化时固定的尺度。因此,单目 SLAM 有一步不可避免的初始化。初始化的两张图像必须有一定程度的平移,而后的轨迹和地图都将以此步的平移为单位。
单目初始化不能只有纯旋转,必须要有一定程度的平移。如果没有平移,单目将无法初始化。
当匹配特征点数多于8对时:原约束方程:![]()
1)可以计算一个最小二乘:![]()
2)当可能出现误匹配时,更倾向于使用随机采样一致性。
3.三角测量
上两节用对极几何估计了相机的运动,下一步用相机运动估计特征点的空间位置。在单目SLAM中,仅靠单张图像无法获得像素的深度信息,因此我们需要通过三角测量来估计地图点的深度信息,是指通过两处观察同一个点的夹角来确定该点距离。
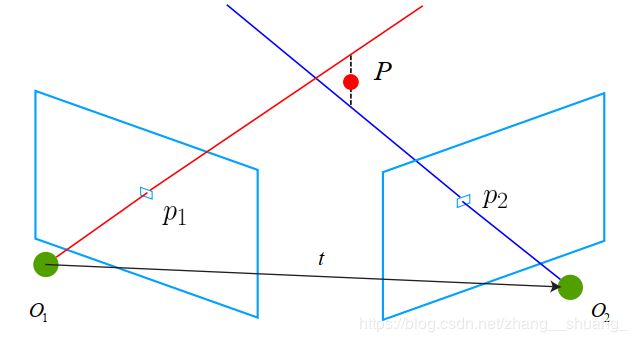
在现实生活中,由于噪声的影响,这两条直线往往无法相交,因此可以用最小二乘去求解。
按照对极几何中的定义,设 x1,x2 为两个特征点的归一化坐标:![]()
![]()
左侧为0,可求出右侧s2深度信息。由于噪声的存在,我们估得的 R,t不一定精确使式为零,所以更常见的做法求最小二乘解而不是零解。三角测量是由平移得到的,有平移才会有对极几何中的三角形,才谈的上三角测量。因此,纯旋转是无法使用三角测量的,因为对极约束将永远满足。在增大平移,会导致匹配失效;而平移太小,则三角化精度不够—这是三角化的矛盾。
4.3D-2D:PnP
如果两张图像中,其中一张特征点的 3D 位置已知,那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动。因此,在双目或 RGB-D 的视觉里程计中,我们可以直接使用 PnP 估计相机运动。而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。PnP 问题有很多种求解方法,例如用三对点估计位姿的 P3P,直接线性变换(DLT),EPnP(Efficient PnP),UPnP等等)。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,也就是万金油式的 Bundle Adjustment。
1)直接线性变换
增广矩阵[ R|t ]是一个3x4的矩阵。
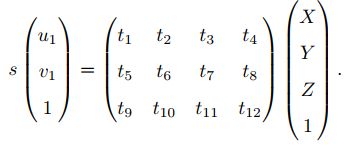
最少找到六对匹配点对,可实现线性求解。当匹配点大于六对时,(又)可以使用 SVD 等方法对超定方程求最小二乘解。
在 DLT 求解中,我们直接将 T 矩阵看成了 12 个未知数,忽略了它们之间的联系。因为旋转矩阵 R 2 SO(3),用 DLT 求出的解不一定满足该约束,它是一个一般矩阵。平移向量比较好办,它属于向量空间。对于旋转矩阵 R,我们必须针对 DLT 估计的 T 的左边3 × 3 的矩阵块,寻找一个最好的旋转矩阵对它进行近似。这可以由 QR 分解完成 [3, 48],相当于把结果从矩阵空间重新投影到 SE(3) 流形上,转换成旋转和平移两部分。
2)P3P

其中A,B,C世界坐标已知,a,b,c图像位置已知,因此夹角已知,需求解A,B,C在相机坐标系下的3D坐标,然后根据3D-3D的点对,计算相机的运动R,t。
缺点:a. P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。
b. 如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。
在SLAM中,通常的做法是先使用 P3P/EPnP 等方法估计相机位姿,然后构建最小二乘优化问题对估计值进行调整(Bundle Adjustment)。
3)Bundle Adjustment
前面说的线性方法,往往是先求相机位姿,再求空间点位置,而非线性优化则是把它们都看成优化变量,放在一起优化。
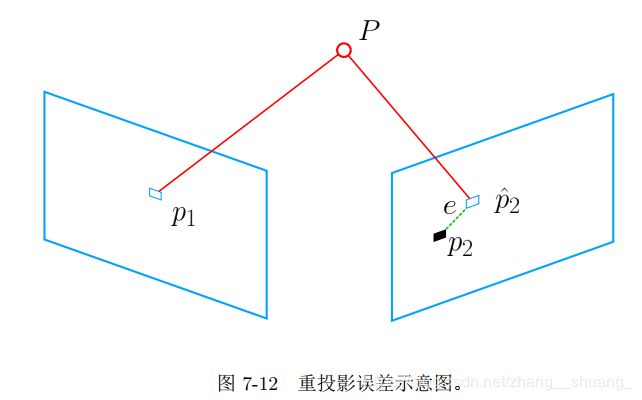
由于相机位姿未知以及观测点的噪声,该等式存在一个误差。因此,我们把误差求和,构建最小二乘问题,然后寻找最好的相机位姿,使它最小化:
该问题的误差项,是将像素坐标(观测到的投影位置)与 3D 点按照当前估计的位姿进行投影得到的位置相比较得到的误差,所以称之为重投影误差。通过特征匹配,知道了 p1和 p2 是同一个空间点 P 的投影,但是我们不知道相机的位姿。在初始值中, P 的投影 p^2与实际的 p2 之间有一定的距离。于是我们调整相机的位姿,使得这个距离变小。
4)3D-3D:ICP
![]()
3D-3D 位姿估计问题中,并没有出现相机模型,也就是说,仅考虑两组 3D 点之间的变换时,和相机并没有关系。ICP 的求解也分为两种方式:利用线性代数的求解(主要是 SVD),以及利用非线性优化方式的求解(类似于 Bundle Adjustment)。
七.视觉里程计-二(直接法)
1.特征点法缺点:
a. 关键点的提取与描述子的计算非常耗时。实践当中, SIFT 目前在 CPU 上是无法实时计算的,而 ORB 也需要近 20 毫秒的计算。如果整个 SLAM 以 30 毫秒/帧的速度运行,那么一大半时间都花在计算特征点上。
b. 使用特征点时,忽略了除特征点以外的所有信息。一张图像有几十万个像素,而特征点只有几百个。只使用特征点丢弃了大部分可能有用的图像信息。
c. 相机有时会运动到特征缺失的地方,往往这些地方没有明显的纹理信息。例如,有时我们会面对一堵白墙,或者一个空荡荡的走廓。这些场景下特征点数量会明显减少,我们可能找不到足够的匹配点来计算相机运动.
解决思路:
a.保留特征点,但只计算关键点,不计算描述子。同时,使用光流法(Optical Flow)来跟踪特征点的运动。这样可以回避计算和匹配描述子带来的时间,但光流本身的计算需要一定时间.(仍使用特征点处理的几个算法)
b.只计算关键点,不计算描述子。同时,使用直接法(Direct Method)来计算特征点在下一时刻图像的位置。这同样可以跳过描述子的计算过程,而且直接法的计算更加简单。(利用图像灰度信息计算相机运动--直接法)
c.既不计算关键点、也不计算描述子,而是根据像素灰度的差异, 直接计算相机运动(利用图像灰度信息计算相机运动-直接法)
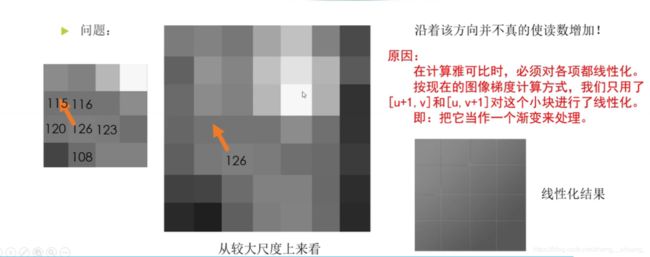
使用特征点法估计相机运动时,我们把特征点看作固定在三维空间的不动点。根据它们在相机中的投影位置,通过最小化重投影误差(Reprojection error)来优化相机运动。在这个过程中,我们需要精确地知道空间点在两个相机中投影后的像素位置,计算、匹配特征需要付出大量的计算量。相对的,在直接法中,我们并不需要知道点与点之间之间的对应关系,根据像素的亮度信息,通过最小化光度误差(Photometric error)来估计相机的运动。只要场景中存在明暗变化(可以是渐变,不形成局部的图像梯度),直接法就能工作。根据使用像素的数量,直接法分为稀疏、稠密和半稠密三种。相比于特征点法只能重构稀疏特征点(稀疏地图),直接法还具有恢复稠密或半稠密结构的能力。
2.光流
光流是一种描述像素随着时间,在图像之间运动的方法,计算部分像素运动的称为稀疏光流,计算所有像素的称为稠密光流。
1)Lucas-Kanade 光流(LK)
在 LK 光流中认为来自相机的图像是随时间变化的。图像可以看作时间的函数:I(t)。一个在 t 时刻,位于 (x,y) 处的像素,它的灰度可以满足![]() 满足灰度不变假设:同一个空间点的像素灰度值,在各个图像中是固定不变的。即:
满足灰度不变假设:同一个空间点的像素灰度值,在各个图像中是固定不变的。即:
![]()
因为:![]()
所以: 
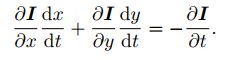
其中 dx/dt 为像素在 x 轴上运动速度,而 dy/dt 为 y 轴速度,把它们记为 u; v。同时 @I/@x 为图像在该点处 x 方向的梯度,另一项则是在 y 方向的梯度,记为 Ix; Iy。把图像灰度对时间的变化量记为 It,写成矩阵形式,有:
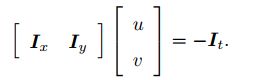
假设某一个窗口内的像素具有相同的运动。考虑一个大小为 w × w 大小的窗口,它含有 w2 数量的像素。由于该窗口内像素具有同样的运动,因此我们共有 w2 个方程:
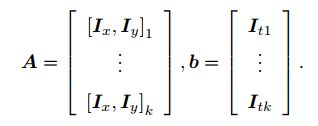
这是一个关于 u; v 的超定线性方程,传统解法是求最小二乘解。

3.直接法
最小化亮度误差:
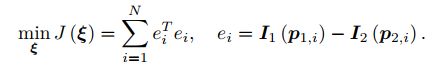
注意这里的优化变量是相机位姿 ξ。为了求解这个优化问题,我们关心误差 e 是如何随着相机位姿 ξ 变化的,需要分析它们的导数关系。因此,使用李代数上的扰动模型。

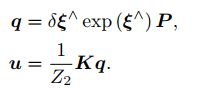
这里的 q 为 P 在扰动之后,位于第二个相机坐标系下的坐标,而 u 为它的像素坐标。
利用一阶泰勒展开,有: