Re:从零开始的DS生活 图论学这一篇就够了
引言:Re:从零开始的DS生活 图论学这一篇就够了,详细介绍了图的基本概念;图的存储结构,邻接矩阵,邻接表;图的遍历,广度度优先遍历和深度优先遍历;最小生成树基本概念,Prim算法,Kruskal算法;最短路径问题,Dijkstra算法,Floyd算法;拓扑排序。供读者理解与学习,适合点赞+收藏。有什么错误希望大家直接指出~
友情链接:Re:从零开始的DS生活 轻松从0基础写出链表LRU算法、Re:从零开始的DS生活 轻松从0基础实现多种队列、Re:从零开始的DS生活 轻松从0基础写出Huffman树与红黑树、Re:从零开始的DS生活 轻松和面试官扯一个小时栈
图的基本概念
图的存储结构,邻接矩阵,邻接表;
图的遍历,广度度优先遍历和深度优先遍历;
最小生成树基本概念,Prim算法,Kruskal算法;最短路径问题,Dijkstra算法,Floyd算法;
最小生成树
Prim算法(普里姆)
Kruskal算法(克鲁斯卡尔)
最短路径问题(Djkstra迪杰斯塔拉)
Floyd算法(弗洛伊德)
拓扑排序
图的基本概念
图:由顶点(vertex)和边(edge)组成的一种结构。顶点的集合V,边的集合是E,所以图记为G=(V,E)两类信息:顶点信息,边的信息
无向边:若顶点vi到vj之间的边没有方向,则称这条边为无向边(Edge), 用无序偶对(vi;vj) 来表示。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图(Undirected graphs)。在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。
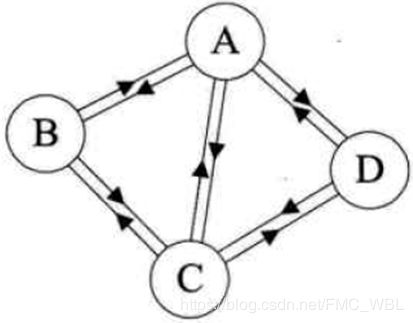
有向边:若从顶点vi到vj的边有方向,则称这条边为有向边,也称为弧(Arc )。用有序偶
图的权:有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权
连通图:在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。如果对于图中任意两个顶点vi、vj∈E, vi 和vj都是连通的,则称G是连通图(Connected Graph)。
度:无向图顶点的边数叫度,有向图顶点的边数叫出度和入度.。
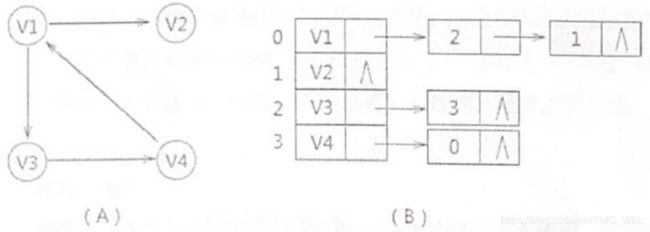
图的存储结构,邻接矩阵,邻接表;
邻接矩阵:设图G有n个顶点,则邻接矩阵是一个nXn的方阵,定义为:

无向图:

有向图:
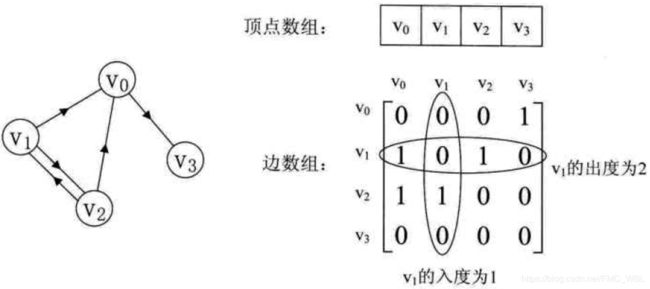
带权的邻接矩阵:(带权的图称为网,包括无向网和有向网)使用二维数组存储网中顶点之间的关系,顶点之间如果有边或者弧的存在,在数组的相应位置存储其权值;反之用∞表示。

使用数组存储图时需要使用两个数组-一个数组存放图中顶点本身的数据一维数组),另外一个数组用于存储各顶点之间的关系(二维数组。
/**
* 定义图的结构
*
* @author macfmc
* @date 2020/6/27-8:18
*/
public class Graph {
//节点数目
protected int size = 20;
//定义数组,保存顶点信息
protected String[] nodes;
//定义矩阵保存顶点信息
protected int[][] edges;
protected int[] visit; //遍历标志
/**
* vo v1 v2 v3
* vo 0 1 1 1
* v1 1 0 1 0
* v2 1 1 0 1
* v3 1 0 1 0
*/
public Graph() {
size = 4;
//初始化顶点
nodes = new String[size];
for (int i = 0; i < size; i++) {
nodes[i] = String.valueOf(i);
}
//初始化边
edges = new int[size][size];
edges[0][1] = 1;
edges[0][2] = 1;
edges[0][3] = 1;
edges[1][0] = 1;
edges[1][2] = 1;
edges[2][0] = 1;
edges[2][1] = 1;
edges[2][3] = 1;
edges[3][0] = 1;
edges[3][2] = 1;
}
public static void main(String[] args) {
Graph graph = new Graph();
}
}
邻接表是图的一种链式存储结构。使用邻接表存储图时,对于图中的每一个顶点和它相关的邻接点都存储到一个链表中。每个链表都配有头结点,头结点的数据域不为NULL ,而是用于存储顶点本身的数据;后续链表中的各个结点存储的是当前顶点的所有邻接点。
所以,采用邻接表存储图时,有多少顶点就会构建多少个链表,为了便于管理这些链表,常用的方法是将所有链表的链表头按照一定的顺序存储在一个数组中(也可以用链表串起来)。
在邻接表中,每个链表的头结点和其它结点的组成成分有略微的不同。头结点需要存储每个顶点的数据和指向下一个结点的指针, 由两部分构成:而在存储邻接点时,由于各个顶点的数据都存储在数组中,所以每个邻接点只需要存储自己在数组中的位置下标即可。另外还需要一个指向下一个结点的指针。除此之外,如果存储的是网,还需要一个记录权值的信息域。所以表头结点和其它结点的构造分别为:
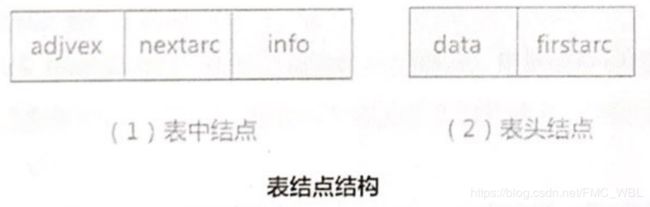
info域对于无向图来说,本身不具备权值和其它相关信息,就可以根据需要将之删除。
图的遍历,广度度优先遍历和深度优先遍历;
深度优先遍历:

第1步:访问A。 第2步:A之后有去向“C,D,F”中的三条路。 随意选择一个----(A的邻接点)C。第3步: C之后有去向“B,D”中的两条路.随意选择一个----(C的邻接点)B。第4步:B已是尽头,无路可走(撞南墙)。 于是回溯到上一步的C。第5步: C之后去向“B”中的路已走过了。现在只有选择D。第6步:D之后的路通向A,A已访问过。于是回溯到C。 第7步:C的两条路都走过了,不通。继续回溯到A。 第8步:A的(”C,D”)都走过了,不通。只剩下F可走,走到F。 第9步:F有路(”G”)可走。走到G。
访问顺序是: A -> C -> B -> D -> F -> G -> E
广度优先遍历:

第1步:访问A。第2步:访问上一步A的邻接点,有“C,D,F” 。依次访问C,D,F。第3步: 访问上一步( C,D,F )的邻接点,有B,G。第4步:访问上一步(B,G)的邻接点,有E。第5步: 访问上一步E的邻接点,没有了,结束。
访问顺序是: A -> C -> D -> F -> B -> G -> E
/**
* @author macfmc
* @date 2020/6/27-9:33
*/
public class GraphCover extends Graph {
private int[] visit = new int[size]; //遍历标志,防止死环遍历
/**
* 深度优先遍历
* 一条路走到黑,不撞南墙不回头,对每一个可能的分支路径深入到不能再深入为止
*/
public void DeepFirst(int start) {//从第n个节点开始遍历
visit[start] = 1; //标记为1表示该顶点已经被处理过
System.out.println("齐天大圣到—>" + this.nodes[start] + "一游"); //输出节点数据
for (int i = 0; i < this.size; i++) {
if (this.edges[start][i] == 1 && visit[i] == 0) {
//邻接点
DeepFirst(i);
}
}
}
private int[] queue = new int[size];
/**
* 广度优先遍历
* 广度优先搜索遍历图的过程中以v 为起始点,由近至远,依次访问和v 有路径相通且路径长度为1,2,…的顶点,第一批节点的邻接点
*/
public void BreadthFirst(int front, int tail) {
int last = tail;
for (int index = front; index <= tail; index++) {
int node = queue[index];
System.out.println("齐天大圣到—>" + this.nodes[node] + "一游"); //输出节点数据
//找出所有的邻接点
for (int i = 0; i < this.size; i++) {
if (this.edges[node][i] == 1 && visit[i] == 0) {
//邻接点
visit[i] = 1;
queue[++last] = i;
}
}
}
//遍历下一批节点
if (last > tail) {
BreadthFirst(tail + 1, last);
}
}
public void BreadthFirst(int start) {
queue[0] = start;
visit[start] = 1;
BreadthFirst(0, 0);
}
public static void main(String[] args) {
GraphCover graph0 = new GraphCover();
graph0.DeepFirst(0);
System.out.println("--------------");
GraphCover graph1 = new GraphCover();
graph1.BreadthFirst(0);
}
}
最小生成树基本概念,Prim算法,Kruskal算法;最短路径问题,Dijkstra算法,Floyd算法;
最小生成树
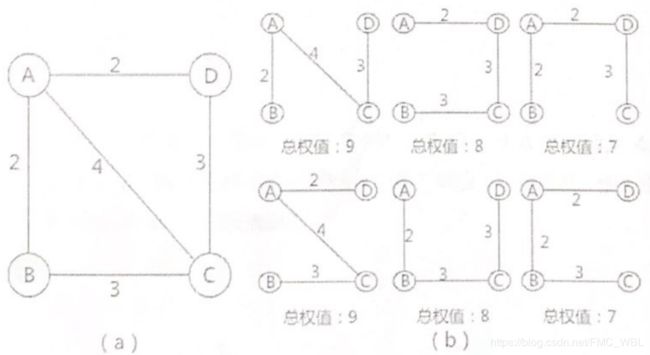
假设通过综合分析,城市之间的权值如图2(a)所示,对于(b)的方案中,选择权值总和为7的两种方案最节约经费
简单得理解就是给定一个带有权值的连通图(连通网),如何从众多的生成树中筛选出权值总和最小的生成树,即为该图的最小生成树。
给定一个连通网,求最小生成树的方法有:普里姆( Prim )算法和克鲁斯卡尔( Kruskal )算法
Prim算法(普里姆):
普里姆算法在找最小生成树时,将顶点分为两类,一类 是在查找的过程中已经包含在树中的(假设为 A类), 剩下的是另一类(假设为 B类)对于给定的连通网,起始状态全部顶点都归为B类。在找最小生成树时,选定任意一个顶点作为起始点,并将之从B类移至A类;然后找出B类中到A类中的顶点之间权值最小的顶点,将之从B类移至A类,如此重复,直到B类中没有顶点为止。所走过的顶点和边就是该连通图的最小生成树。
例如,通过普里姆算法查找图2(a)的最小生成树的步骤为:假如从顶点A出发,顶点B、C、D到顶点A的权值分别为2、4、2,所以,对于顶点A来说,顶点B和顶点D到A的权值最小,假设先找到的顶点B:继续分析顶点C和D,顶点C到B的权值为3,到A的权值为4;顶点D到A的权值为2,到B的权值为无穷大(如果之间没有直接通路,设定权值为无穷大的所以顶点D到A的权值最小:最后,只剩下顶点C,到A的权值为4,到B的权值和到D的权值一样大,为3。所以该连通图有两个最小生成树:
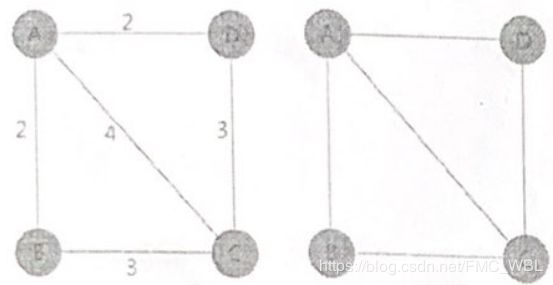
例子:此图结果应为: A-C, C-F, F-D, C-B, B-E

普里姆算法的运行效率只与连通网中包含的顶点数相关, 而和网所含的边数无关。所以普里姆算法适合于解决边稠密的网,该算法运行的时间复杂度为: O(n^2)
Kruskal算法(克鲁斯卡尔):
克鲁斯卡尔算法的具体思路是:将所有边按照权值的大小进行升序排序,然后从小到大判断,条件为:如果这个边不会与之前选择的所有边组成回路,就可以作为最小生成树的一部分;反之,舍去。直到具有n个顶点的连通网筛选出来n-1条边为止。筛选出来的边和所有的顶点构成此连通网的最小生成树。判断是否会产生回路的方法为:在初始状态下给每个顶点赋予不同的标记,对于遍历过程的每条边,其都有两个顶点,判断这两个顶点的标记是否一致,如果一致,说明它们本身就处在一棵树中,如果继续连接就会产性回路;如果不一致,说明它们之间还没有任何关系,可以连接。
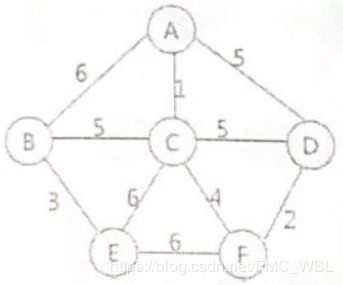
假设遍历到一条由顶点A和B构成的边,而顶点A和顶点B标记不同,此时不仅需要将顶点A的标记更新为顶点B的标记,还需要更改所有和顶点A标记相同的顶点的标记,全部改为顶点B的标记。
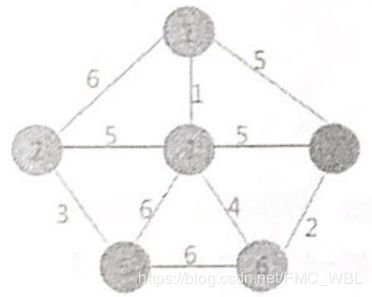
例如,使用克鲁斯卡尔算法找图1的最小生成树的过程为:首先,在初始状态下,对各顶点赋予不同的标记(用颜色区别),如下图所示:
对所有边按照权值的大小进行排序,按照从小到大的顺序进行判断,首先是(1, 3),由于顶点1和顶点3标记不同,所以可以构成生成树的一部分,遍历所有顶点,将与顶点3标记相同的全部更改为顶点1的标记,如上图所示:
其次是(4, 6)边,两顶点标记不同,所以可以构成生成树的一部分,更新所有顶点的标记为:其次是(2 ,5 )边,两顶点标记不同,可以构成生成树的一部分, 更新所有顶点的标记为:
其次是(2,5)边,两顶点标记不同,可以构成生成树的一部分,更新所有顶点的标记为:然后最小的是(3,6)边,两者标记不同,可以连接,遍历所有顶点,将与顶点6标记相同的所有顶点的标记更改为顶点1的标记:
继续选择权值最小的边,此时会发现,权值为5的边有3个,其中(1,4)和(3, 4)各自两顶点的标记-样,如果连接会产生回路,所以舍去,而(2,3)标记不一样,可以选择,将所有与顶点2标记相同的顶点的标记全部改为同顶点3相同的标记:
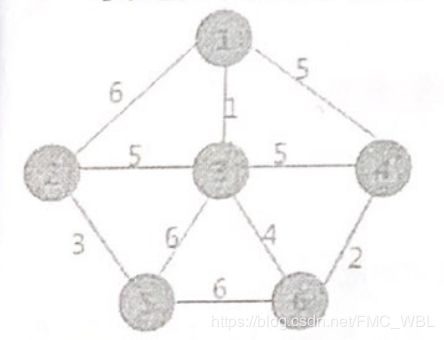
当选取的边的数量相比与顶点的数量小1时,说明最小生成树已经生成。所以最终采用兄鲁斯卡尔算法得到的最小生成树为(6 )所示
总结:普里姆算法。该算法从顶点的角度为出发点,时间复杂度为o(n2) ,更适合与解决边的绸密度更高的连通网。
克鲁斯卡尔算法,从边的角度求网的最小生成树,时间复杂度为O(eloge)。和普里姆算法恰恰相反,更适合于求边稀疏的网的最小生成树。
最短路径问题(Djkstra)
在一个网(有权图)中, 求-个顶点到另一个顶点的最短路径的计算方式有两种:迪杰斯特拉( Dijkstra算法)和弗洛伊德( Floyd )算法。迪杰斯特拉算法计算的是有向网中的某个顶点到其余所有顶点的最短路径;弗洛伊德算法计算的是任意两顶点之间的最短路径。
迪杰斯特拉( Djkstra算法):迪杰斯特拉算法计算的是从网中一个顶点到其它顶点之间的最短路径问题。
1、扫描AA邻接点,记录邻接点权重值
2、找出邻接点里最小的那个值
/**
* @author macfmc
* @date 2020/6/27-17:57
*/
public class Dijkstra {
//节点数目
protected int size;
//定义数组,保存顶点信息
protected String[] nodes;
//定义矩阵保存顶点信息
protected int[][] edges;
private int[] isMarked;//节点确认--中心标识
private String[] path;//源到节点的路径信息
private int[] distances;//源到节点的距离
public Dijkstra() {
init();
isMarked = new int[size];
path = new String[size];
distances = new int[size];
for (int i = 0; i < size; i++) {
path[i] = "";
distances[i] = Integer.MAX_VALUE;
}
}
public static void main(String[] args) {
Dijkstra dijkstra = new Dijkstra();
dijkstra.search(3);
}
public void search(int node) {
path[node] = nodes[node];
distances[node] = 0;
do {
flushlast(node);
node = getShort();
} while (node != -1);
}
//1、扫描AA邻接点,记录邻接点权重值
private void flushlast(int node) {
isMarked[node] = 1;
System.out.println(path[node]);
//扫描邻接点
for (int i = 0; i < size; i++) {
if (this.edges[node][i] > 0) {
//计算AA节点到 i节点的权重值
int distant = distances[node] + this.edges[node][i];
if (distant < distances[i]) {
distances[i] = distant;
path[i] = path[node] + "-->" + nodes[i];
}
}
}
}
// 2、找出邻接点里最小的那个值
private int getShort() {
int last = -1;
int min = Integer.MAX_VALUE;
for (int i = 0; i < size; i++) {
if (isMarked[i] == 1) {
continue;
}
if (distances[i] < min) {
min = distances[i];
last = i;
}
}
return last;
}
public void init() {
//初始化顶点
nodes = new String[]{"AA", "A", "B", "C", "D", "E", "F", "G", "H", "M", "K", "N"};
//节点编号-常量
final int AA = 0, A = 1, B = 2, C = 3, D = 4, E = 5, F = 6, G = 7, H = 8, M = 9, K = 10, N = 11;
size = nodes.length;
edges = new int[size][size];
edges[AA][A] = 3;
edges[AA][B] = 2;
edges[AA][C] = 5;
edges[A][AA] = 3;
edges[A][D] = 4;
edges[B][AA] = 2;
edges[B][C] = 2;
edges[B][G] = 2;
edges[B][E] = 3;
edges[C][AA] = 5;
edges[C][E] = 2;
edges[C][B] = 2;
edges[C][F] = 3;
edges[D][A] = 4;
edges[D][G] = 1;
edges[E][B] = 3;
edges[E][C] = 2;
edges[E][F] = 2;
edges[E][K] = 1;
edges[E][H] = 3;
edges[E][M] = 1;
edges[F][C] = 3;
edges[F][E] = 2;
edges[F][K] = 4;
edges[G][B] = 2;
edges[G][D] = 1;
edges[G][H] = 2;
edges[H][G] = 2;
edges[H][E] = 3;
edges[K][E] = 1;
edges[K][F] = 4;
edges[K][N] = 2;
edges[M][E] = 1;
edges[M][N] = 3;
edges[N][K] = 2;
edges[N][M] = 3;
}
}
总结:迪杰斯特拉算法解决的是从网中的一个顶点到所有其它顶点之间的最短路径算法整体的时间复杂度为O(n2)。但是如果需要求任意两顶点之间的最短路径,使用迪杰斯特拉算法虽然最终虽然也能解决问题,但是大材小用相比之下使用弗洛伊德算法解决此类问题会更合适。
Floyd算法(弗洛伊德):
弗洛伊德的核心思想是:对于网中的任意两个顶点(例如顶点A到顶点B )来说,之间的最短路径不外乎有2种情况:一、直接从顶点A到顶点B的弧的权值为顶点A到顶点B的最短路径;二、从顶点A开始,经过若干个顶点,最终达到顶点B ,期间经过的弧的权值和为顶点A到顶点B的最短路径。
拓扑排序
对有向无环图进行拓扑排序,只需要遵循两个原则:
一、在图中选择- -一个没有前驱的顶点V ;
二、从图中删除顶点V和所有以该顶点为尾的弧。
有向无环图如果顶点本身具有某种实际意义,例如用有向无环图表示大学期间所学习的全部课程,每个顶点都表示一门课程,有向边表示课程学习的先后次序,例如要先学《程序设计

进行拓扑排序时,首先找到没有前驱的顶点V1 ,如(1)所示;在删除顶点V1及以V1作为起点的弧后,继续查找没有前驱的顶点,此时,V2和V3都符合条件,可以随机选择一个,例如(2)所示,选择V2 , 然后继续重复以上的操作,直至最后找不到没有前驱的顶点。
所以,针对图2来说,拓扑排序最后得到的序列有两种:
●V1-> V2-> V3-> V4 ●V1-> V3-> V2 -> V4