Trove主要逻辑目前Trove支持用户创建一个数据库服务实例,在实例里可以创建多个数据库并进行管理。数据库服务实例目前通过Nova API来创建,然后同样通过Nova API创建一个Volume(未来通过Cinder API)作为存储,然后在Nova Instance里加载预定义的带有MySQL的Image来启动MySQL。此时用户在得到一个创建好的数据库服务实例以后可以通过API创建数据库并 且指定参数,Trove通过在数据库服务实例里的guest agent来完成相应的命令。下图是Trove处理请求的最主要流程。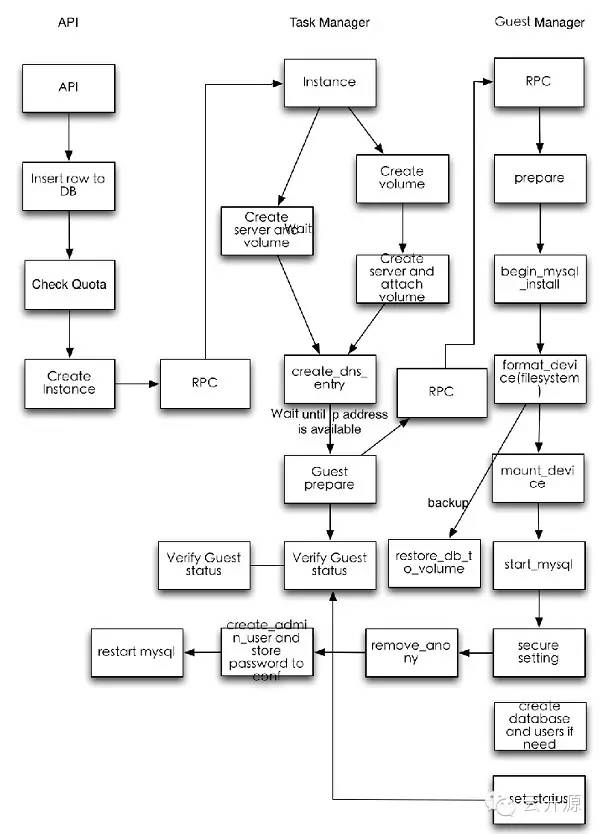 图1 Trove处理请求的主要流程
图1 Trove处理请求的主要流程
Trove的当前架构 图2 Trove的当前架构说明
图2 Trove的当前架构说明
trove-api
提供REST风格的API,支持json和xml,程序源代码入口在trove/cmd/api.py。API server与两个组件通信,所有复杂的异步任务它都交给taskmanager去完成,有些信息它会直接从trove的后端DB中获得。 根据其配置文件api-paste.ini,可以看到起最终APP的入口是:trove/common/api.py,这就是整个trove除了version和extension外所有资源对象操作的总入口。在API类中明确定义了url和处理的controller的路由关系,非常的清晰。 trove-taskmanager
负责配置数据库虚拟机实例,管理数据库虚拟机实例的生命周期和执行这对数据库虚拟机实例的各种操作.监听消息队列服务器的RPC service,程序源代码入口在trove/cmd/taskmanage.py。需要特别注意:trove-taskmanager是一个有状态的服务,它负责组织复杂的业务流程。如果在有状态的处理流程当中,taskmanager挂了,则任务就被认为失败。 trove-guestagent
运行于数据库虚拟机实例的内部,负责管理和实际执行对数据库管理程序的任务。guestagent在消息总线上监听RPC消息,执行要求的操作。程序源代码入口在trove/cmd/guest.py。每一种数据库都有与之对应的不同的guestagent,显而易见,redis的guestagent和mysql的guestagent的行为不可能是一样的。
trove-conductor
负责从guestagents收集状态信息然后将其写入Trove的后端数据库,其与guestagent交互基于RPC实现。这个组件的引入就是为了实现这样的目的,即db instance内的gusestagent不应直接与trove的后端数据库相连。程序源代码入口在trove/cmd/conductor.py。从目前的代码看,这个组件就两个功能函数:
def heartbeat(self, context, instance_id, payload, sent=None)上报DBinstance的心跳和状态信息,如NEW to BUILDING to ACTIVEdef update_backup(self, context, instance_id, backup_id, sent=None, **backup_fields)更新当前backup的状态信息,如当前状态,已备份的大小,类型和校验情况。
Trove规划中的改进架构 将Trove-conductor作为访问trove后端数据库的唯一入口,所有模型的数据库CRDU操作都依靠他来完成。OpenStack很多服务组件都有这样的设计倾向,如nova,都想将db的操作隔离出来,这样做的好处是可以将服务的后端DB与应用层隔离,后端DB可以运行在另一个网络中,实现网络隔离,除conductor外的所有组件都不能直接访问到DB所在的网络。
将Trove-conductor作为访问trove后端数据库的唯一入口,所有模型的数据库CRDU操作都依靠他来完成。OpenStack很多服务组件都有这样的设计倾向,如nova,都想将db的操作隔离出来,这样做的好处是可以将服务的后端DB与应用层隔离,后端DB可以运行在另一个网络中,实现网络隔离,除conductor外的所有组件都不能直接访问到DB所在的网络。
Trove API初步解读下表列出了Trove 主要的API:

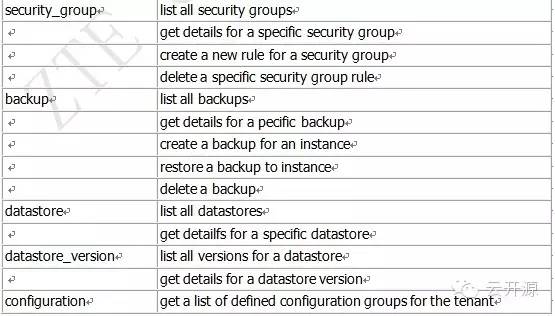

API解读:1.这里的datastore和datastore_version是指存储数据的数据库管理程序和它的版本。例如trove现在支持的数据库管理程序有MySQL、cassandra、mongodb,datastore就是指的是这些。而datastore_version是指这些数据库管理程序的版本,例如5.1,还是5.5之类的。这里可以看到对于datastore和datastore_version,只有查询操作,这也是很正常的,对于DBaaS的服务来说,也只能支持指定的若干数据库类型。这两个resource用来在create db instance的时候供用户选择。
2.flavor是从nova中获取的预先设定好的几种虚拟机规格,只提供查询操作,供用户选择。
3.configuration是指数据库程序配置文件中一堆的配置项,这些配置项由key-value的形式组成;而configuration_parameter是对配置项key的详细信息的记录,它包括配置参数的默认值、是否应该配置、是否可以动态生效以及数据类型是什么。 4.从API我们可以看到security group的操作中没有创建操作,这是因为数据库安全组的目前的设计原则决定的。trove对于security group的目前的设计是:每个数据库实例对应一个安全组,用户不能直接操作安全组,只能添加或删除安全组的规则。未来这个设计可能改变,同时会在加入默认的安全规则集。 5.数据库日志文件可以被保存并上传到swift上。