python爬虫-自建IP代理池
写在前面
最近跟静觅大神学习了维护代理池
就借此机会整理一下
整体思路
代理池主要分为4个模块:存储模块、获取模块、检测模块、接口模块
- 存储模块:使用Redis有序集合,用来做代理的去重和状态标识
- 获取模块:定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库
- 检测模块:定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识
- 接口模块:通过Web API提供服务接口,接口通过连接数据库并通过Web形式返回可用代理
接下来,就一一实现这些模块吧。
存储模块
这里我们使用Redis的有序集合,集合的每一个元素都是不重复的。另外,有序集合的每一个元素都有一个分数字段。
对于代理池来说,这个分数可以作为判断一个代理是否可用的标志,100为最高分,代表最可用;0为最低分,代表不可用。
如果要获取代理,可以从代理池中随机获取分数最高的代理。
分数的设置规则:新获取的代理的分数为10,如果测试可行,分数立即置为100,检测到不可用就将分数减1,分数减至0后代理移除。
具体代码实现如下(ippool_save.py)
MAX_SCORE = 100 #最高分
MIN_SCORE = 0 #最低分
INITIAL_SCORE = 10 #初始分数
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
REDIS_PASSWORD = None
REDIS_KEY = 'proxies' #键名
import redis
from random import choice
class PoolEmptyError():
def __str__(self):
return PoolEmptyError
class RedisClient(object):
def __init__(self,host=REDIS_HOST,port=REDIS_PORT,password=REDIS_PASSWORD):
'''
初始化
:param host:地址
:param port: 端口号
:param password: 密码
'''
self.db = redis.StrictRedis(host=host,port=port,password=password,decode_responses=True)
def add(self,proxy,score=INITIAL_SCORE):
'''
添加代理,设置初始分数
:param proxy: 代理
:param score: 分数
:return: 添加结果
'''
if not self.db.zscore(REDIS_KEY,proxy):
return self.db.zadd(REDIS_KEY,{proxy:score})
def random(self):
'''
随即获取有效代理,首先尝试获取最高分数代理,如果最高分数不存在,则按照排名获取
:return:
'''
result = self.db.zrangebyscore(REDIS_KEY,MAX_SCORE,MAX_SCORE)
if len(result):
return choice(result)
else:
result = self.db.zrevrange(REDIS_KEY,0,100)
if len(result):
return choice(result)
else:
raise PoolEmptyError
def decrease(self, proxy):
'''
代理值减一分,分数小于最小值,则代理删除
:param proxy: 代理
:return: 修改后的代理分数
'''
score = self.db.zscore(REDIS_KEY,proxy)
if score and score>MIN_SCORE:
print("代理",proxy,"当前分数",score,"减1")
return self.db.zincrby(REDIS_KEY,-1,proxy)
else:
print("代理",proxy,"当前分数",score,"移除")
return self.db.zrem(REDIS_KEY,proxy)
def exists(self,proxy):
'''
判断是否存在
:param proxy: 代理
:return: 是否存在
'''
return not self.db.zscore(REDIS_KEY,proxy) == None
def max(self,proxy):
'''
将代理设置为MAX_SCORE
:param proxy: 代理
:return: 设置结果
'''
print("代理",proxy,"可用,设置为",MAX_SCORE)
return self.db.zadd(REDIS_KEY,{proxy:MAX_SCORE})
def count(self):
'''
获取数量
:return:数量
'''
return self.db.zcard(REDIS_KEY)
def all(self):
'''
获取全部代理
:return: 全部代理列表
'''
return self.db.zrangebyscore(REDIS_KEY,MIN_SCORE,MAX_SCORE)
获取模块
获取模块的逻辑相对简单,首先要定义一个ippool_crawler.py来从各大网站抓取,具体代码如下:
import json
import requests
from lxml import etree
from ippool_save import RedisClient
class ProxyMetaclass(type):
#参数依次是当前准备创建的类的对象;类的名字;类继承的父类集合;类的方法集合。
def __new__(cls, name,bases,attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k,v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
count+=1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls,name,bases,attrs)
class Crawler(object,metaclass=ProxyMetaclass):
def __init__(self):
self.proxy = RedisClient().random()
self.proxies = {
'http': 'http://' + self.proxy,
'https': 'https://' + self.proxy
}
def get_proxies(self,callback):
proxies = []
for proxy in eval("self.{}()".format(callback)):
print('成功获取代理',proxy)
proxies.append(proxy)
return proxies
#爬取西刺代理
def crawl_xici(self,page_count=10):
start_url = 'https://www.xicidaili.com/nn/{}'
urls = [start_url.format(page) for page in range(1,page_count+1)]
header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
for url in urls:
print('Crawling',url)
data = requests.get(url,headers = header,proxies = self.proxies).content.decode("utf-8")
print("data",len(data))
if data:
html = etree.HTML(data)
trs = html.xpath('//table[@id="ip_list"]//tr[1]/following-sibling::*')
for tr in trs:
ip = tr.xpath('./td[2]/text()')
port = tr.xpath('./td[3]/text()')
if ip and port:
yield ':'.join([ip[0],port[0]])
#爬取89ip
def crawl_89(self,page_count=10):
start_url = 'http://www.89ip.cn/index_{}.html'
urls = [start_url.format(page) for page in range(1,page_count+1)]
header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
for url in urls:
print('Crawling',url)
data = requests.get(url,headers = header,proxies = self.proxies).content.decode("utf-8")
if data:
html = etree.HTML(data)
trs = html.xpath('//table[@class="layui-table"]/tbody/tr')
for tr in trs:
ip = tr.xpath('./td[1]/text()')
port = tr.xpath('./td[2]/text()')
if ip and port:
yield ':'.join([ip[0].strip(),port[0].strip()])
方便起见,我们将获取代理的每一个方法统一定义为以Crawl开头,这样扩展的时候只需要添加crawl开头的方法即可。
在这里,我实现抓取西刺代理与89免费代理,这些方法都定义成了生成器,通过yield返回一个个代理。
然后,定义了一个get_proxies()方法,将所有以crawl开头的方法调用一遍,获取每个方法返回代理并组合成列表形式返回。
那么,如何获取所有以crawl开头的方法名称呢?这里借助了元类来实现。
我们定义了一个ProxyMetaclass,Crawler将它设置为元类,元类中实现了__new__()方法,这个方法中的attrs参数包含了类的属性。我们只需要遍历attrs这个参数即可获得类方法中的所有信息,进而判断方法中是否包含crawl 。
所以,我们还需要定义一个Getter类,用来动态地调用所有以crawl开头的方法,然后获取抓取到的代理,将其加入到数据库存储起来,具体代码如下(ippool_getter.py)
from ippool_save import RedisClient
from ippool_crawler import Crawler
POOL_UPPER_THRESHOLD = 1000
class Getter():
def __init__(self):
self.redis = RedisClient()
self.crawler = Crawler()
def is_over_threshold(self):
if self.redis.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False
def run(self):
print("获取器开始执行")
if not self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
proxies = self.crawler.get_proxies(callback)
for proxy in proxies:
self.redis.add(proxy)
检测模块
我们已经将各个网站的代理都抓取下来了现在就需要一个检测模块来对所有代理进行多轮检测。
若检测代理可用,分数就设置为100,代理不可用,分数减1,这样就可以实时改变每个代理的可用情况。
由于代理的数量特别多,为了提高代理的检测效率,我们在这里使用异步请求库aiohttp来进行检测。
具体代码如下(ippool_check.py):
VALID_STATUS_CODES = [200]
TEST_URL = "http://www.baidu.com"
BATCH_TEST_SIZE = 100
from ippool_save import RedisClient
import aiohttp
import asyncio
import time
class Tester(object):
def __init__(self):
self.redis = RedisClient()
async def test_single_proxy(self,proxy):
conn = aiohttp.TCPConnector(verify_ssl=False)
async with aiohttp.ClientSession(connector=conn) as session:
try:
if isinstance(proxy,bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://'+ proxy
print("正在测试",proxy)
async with session.get(TEST_URL,proxy=real_proxy,timeout=15) as response:
if response.status in VALID_STATUS_CODES:
self.redis.max(proxy)
print('代理可用',proxy)
else:
self.redis.decrease(proxy)
print('请求响应码不合法',proxy)
except (TimeoutError,ArithmeticError):
self.redis.decrease(proxy)
print('代理请求失败',proxy)
def run(self):
print('测试开始运行')
try:
proxies = self.redis.all()
loop = asyncio.get_event_loop()
for i in range(0,len(proxies),BATCH_TEST_SIZE):
test_proxies = proxies[i:i+BATCH_TEST_SIZE]
tasks = [self.test_single_proxy(proxy) for proxy in test_proxies]
loop.run_until_complete(asyncio.wait(tasks))
time.sleep(5)
except Exception as e:
print('测试器发生错误', e.args)
测试链接在这里定义为TEST_URL,如果针对某个网站有抓取需求,建议将TEST_URL设置为目标网站的地址。
另外,我们设置了批量测试的最大值BATCH_TEST_SIZE为100,也就是一批测试最多100个,这可以避免代理池过大时一次性测试全部代理导致内存开销过大的问题。
接口模块
为了更方便地获取可用代理,我们增加了一个接口模块。
使用Flask来实现这个接口模块,实现代码如下(ippool_api.py)
from flask import Flask,g
from ippool_save import RedisClient
__all__ = ['app']
app = Flask(__name__)
def get_conn():
if not hasattr(g,'redis'):
g.redis = RedisClient()
return g.redis
@app.route('/')
def index():
return 'Welcome to Proxy Pool System
'
@app.route('/random')
def get_proxy():
conn = get_conn()
return conn.random()
@app.route('/count')
def get_counts():
conn = get_conn()
return str(conn.count())
if __name__ == '__main__':
app.run()
调度模块
调度模块就是调用以上定义的3个模块,将这3个模块通过多进程的形式运行起来。
最后,只需要调用Scheduler的run()方法即可启动整个代码池。
TESTER_CYCLE = 20
GETTER_CYCLE = 20
TESTER_ENABLED = True
GETTER_ENABLED = True
API_ENABLED = True
from multiprocessing import Process
from ippool_api import app
from ippool_getter import Getter
from ippool_check import Tester
import time
class Scheduler():
def schedule_tester(self,cycle=TESTER_CYCLE):
tester = Tester()
while True:
print('测试器开始运行')
tester.run()
time.sleep(cycle)
def schedule_getter(self,cycle=GETTER_CYCLE):
getter = Getter()
while True:
print('开始抓取代理')
getter.run()
time.sleep(cycle)
def schedule_api(self):
app.run()
def run(self):
print('代理池开始运行')
if TESTER_ENABLED:
tester_process = Process(target=self.schedule_tester)
tester_process.start()
if GETTER_ENABLED:
getter_process = Process(target=self.schedule_getter)
getter_process.start()
if API_ENABLED:
api_process = Process(target=self.schedule_api)
api_process.start()
if __name__ == '__main__':
Scheduler().run()
运行
以上就是整个代理池的架构和相应实现逻辑。
下面我们来运行一下吧~

去数据库中查看代理
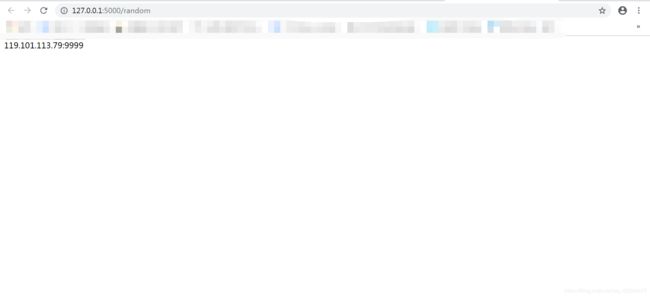
使用接口随机获取可用代理
结语
代理池可以挑选出许多可用代理,但是常常稳定性不高、响应速度慢,而且这些代理通常是公共代理,可能不止一人同时使用,其ip被封的概率很大。另外,这些代理可能有效时间比较短,虽然代理池一直在筛选,但如果没有及时更新状态,也有可能获取到不可用代理。
所以,我们还可以考虑通过ADSL动态拨号的方式获取代理。