OpenMP简介和计算实例
1. OpenMP简介
OpenMP是一个共享存储并行系统上的应用程序接口。它规范了一系列的编译制导、运行库例程和环境变量,但OpenMP完全依赖用户保证制导的正确性,即使用户给出的制导是错误的,OpenMP兼容的实现也不要求进行错误检查,而是可以简单地忽略。同时,它提供了C/C++和FORTRAN等的应用编程接口,已经应用到UNIX、Windows NT等多种平台上。
OpenMP使用FORK-JOIN并行执行模型。所有的OpenMP程序开始于一个单独的主线程(Master Thread)。主线程会一直串行地执行,直到遇到第一个并行域(Parallel Region)才开始并行执行。接下来的过程如下:①FORK:主线程创建一队并行的线程,然后,并行域中的代码在不同的线程队中并行执行;②JOIN:当诸线程在并行域中执行完之后,它们或被同步或被中断,最后只有主线程在执行。
2. OpenMP计算实例
(1) 实验环境:
在这里简单说明一下求π的积分方法,使用公式arctan(1)=π/4以及(arctan(x))'=1/(1+x^2).
OpenMP是一个共享存储并行系统上的应用程序接口。它规范了一系列的编译制导、运行库例程和环境变量,但OpenMP完全依赖用户保证制导的正确性,即使用户给出的制导是错误的,OpenMP兼容的实现也不要求进行错误检查,而是可以简单地忽略。同时,它提供了C/C++和FORTRAN等的应用编程接口,已经应用到UNIX、Windows NT等多种平台上。
OpenMP使用FORK-JOIN并行执行模型。所有的OpenMP程序开始于一个单独的主线程(Master Thread)。主线程会一直串行地执行,直到遇到第一个并行域(Parallel Region)才开始并行执行。接下来的过程如下:①FORK:主线程创建一队并行的线程,然后,并行域中的代码在不同的线程队中并行执行;②JOIN:当诸线程在并行域中执行完之后,它们或被同步或被中断,最后只有主线程在执行。
2. OpenMP计算实例
(1) 实验环境:
若在机群上,Linux用户可直接使用系统自带的SSH命令登陆,在Windows环境下,可使用xshell工具,或者putty工具,本文使用的是putty。putty默认的鼠标按键行为是右键复制,Windows的用户这点可能不习惯,可以在Window的Selection中的Action of mouse buttons下设置成Windows:
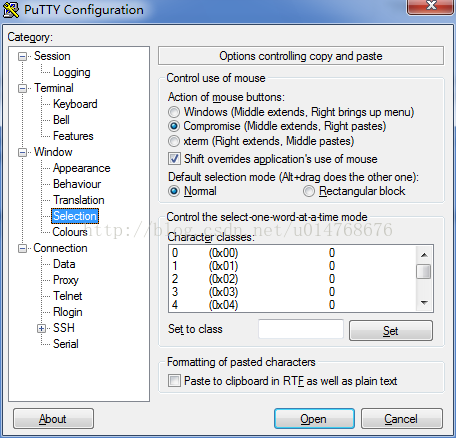
登录进机群后,进入结点,建立文件夹,如mkdir demo,建立程序vi a.c,写入代码,编译gcc –fopenmp –o a a.c,执行./a。
最简单的,在Microsoft Visual Studio中,可以直接配置使用OpenMP,如下图

(2)程序示例
与“Hello World”程序类似,本文编写OpenMP计算π的简单示例。
首先是串行的π程序:
#include
#include
static long num_steps = 100000;//越大值越精确
double step;
void main(){
int i;
double x, pi, sum = 0.0;
step = 1.0/(double)num_steps;
for(i=1;i<= num_steps;i++){
x = (i-0.5)*step;
sum=sum+4.0/(1.0+x*x);
}
pi=step*sum;
printf("%lf\n",pi);
} 在这里简单说明一下求π的积分方法,使用公式arctan(1)=π/4以及(arctan(x))'=1/(1+x^2).
在求解arctan(1)时使用矩形法求解:
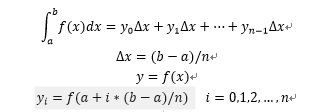
求解arctan(1)是取a=0, b=1.
下面给出4种OpenMP的程序求解π:
1. 使用并行域并行化的程序
#include
#include
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
void main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel private(i) //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
for (i=id, sum[id]=0.0;i< num_steps; i=i+NUM_THREADS){
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i=0, pi=0.0;i 2.使用共享任务结构并行化的程序
#include
#include
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
void main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
sum[id]=0;
#pragma omp for //未指定chunk,迭代平均分配给各线程(0和1),连续划分
for (i=0;i< num_steps; i++){
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i=0, pi=0.0;i 3.使用private子句和critical部分并行化的程序
#include
#include
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
void main ()
{
int i;
double pi=0.0;
double sum=0.0;
double x=0.0;
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel private(x,sum) //该子句表示x,sum变量对于每个线程是私有的
{
int id;
id = omp_get_thread_num();
for (i=id, sum=0.0;i< num_steps; i=i+NUM_THREADS){
x = (i+0.5)*step;
sum += 4.0/(1.0+x*x);
}
#pragma omp critical //指定代码段在同一时刻只能由一个线程进行执行
pi += sum*step;
}
printf("%lf\n",pi);
} 4.使用并行规约的并行程序
#include
#include
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
void main ()
{
int i;
double pi=0.0;
double sum=0.0;
double x=0.0;
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel for reduction(+:sum) private(x) //每个线程保留一份私有拷贝sum,x为线程私有,最后对线程中所以sum进行+规约,并更新sum的全局值
for(i=1;i<= num_steps; i++){
x = (i-0.5)*step;
sum += 4.0/(1.0+x*x);
}
pi = sum * step;
printf("%lf\n",pi);
} 3. 小结
OpenMP是一种基于共享存储系统之上的并行编程标准,OpenMP标准提供了更为简单的编程模型,更易于编程,但是OpenMP完全依赖用户保证制导的正确性。本文以计算π值为例,给出4种OpenMP编程的实现方式,方便上机实践。
参考文献:
陈国良等.并行算法实践[M].北京:高等教育出版社,2004.1.