TF2.0深度学习实战(一):分类问题之手写数字识别
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与记录。如果您也对深度学习、机器视觉、算法、Python、C++感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
我的Github项目地址是:【AI 菌】的Github
本教程会持续更新,如果对您有帮助的话,欢迎star收藏~
前言:
当你在芸芸博客之中看到《TF2.0深度学习实战:图像分类/目标检测》系列,说明我俩注定有缘,因为这里已留下你的脚印~
本博客将分享我从零开始搭建神经网络的学习过程,力争打造最易上手的小白教程。在这过程中,我将使用谷歌TensorFlow2.0框架逐一复现经典的卷积神经网络:LeNet-5、AlexNet、VGG系列、GooLeNet、ResNet 系列、DenseNet 系列,实现图像分类与识别。之后也将逐一复现现在很流行的目标检测算法:RCNN系列、SSD、YOLO系列等,实现多目标的检测任务。
本博客持续更新,欢迎关注。本着学习的心,希望和大家相互交流,一起进步!
俗话说,工欲善其事,必先利其器。所以还没有搭建好环境的盆友戳戳下面吧~
实战系列:
深度学习环境搭建:Anaconda3+tensorflow2.0+PyCharm
TF2.0深度学习实战(一):分类问题之手写数字识别
TF2.0深度学习实战(二):用compile()和fit()快速搭建MNIST分类器
TF2.0深度学习实战(三):LeNet-5搭建MNIST分类器
TF2.0深度学习实战(四):搭建AlexNet卷积神经网络
TF2.0深度学习实战(五):搭建VGG系列卷积神经网络
TF2.0深度学习实战(六):搭建GoogLeNet卷积神经网络
TF2.0深度学习实战(七):手撕深度残差网络ResNet
TF2.0深度学习实战(八):搭建DenseNet稠密神经网络
理论系列:
深度学习笔记(一):卷积层+激活函数+池化层+全连接层
深度学习笔记(二):激活函数总结
深度学习笔记(三):BatchNorm(BN)层
深度学习笔记(四):梯度下降法与局部最优解
深度学习笔记(五):欠拟合、过拟合
防止过拟合(5.1):正则化
防止过拟合(5.2):Dropout
防止过拟合(5.3):数据增强
文章目录
- 一、手写数字识别简介
- 二、MNIST数据集介绍
- 三、深度学习实战
- 3.1 数据集加载
- 3.2 网络结构搭建
- 3.3 模型装配与训练
- 3.4 测试结果
- 四、完整程序清单(附详细注释)
一、手写数字识别简介
手写数字识别是一个非常经典的图像分类任务,经常被作为深度学习入门的第一个指导案例。相当于我们学编程语言时,编写的第一个程序“Hello World !”。不一样的是,入门深度学习,需要有一定量的理论基础。对于基础理论还不熟悉的同学,建议先加加餐:深度学习理论系列。
手写数字识别是基于MNIST数据集的一个图像分类任务,目的是通过搭建深度神经网络,实现对手写数字的识别(分类)。
二、MNIST数据集介绍
为了方便业界统一测试和评估算法, (Lecun, Bottou, Bengio, & Haffner, 1998)发布了手写数字图片数据集,命名为 MNIST,它包含了 0~9 共 10 种数字的手写图片,每种数字一共有 7000 张图片,采集自不同书写风格的真实手写图片,一共 70000 张图片。其中60000张图片作为训练集,用来训练模型。10000张图片作为测试集,用来训练或者预测。训练集和测试集共同组成了整个 MNIST 数据集。
MINIST数据集中的每张图片,大小为28 × \times × 28,同时只保留灰度信息(即单通道)。下图是MNIST数据集中的部分图片:

三、深度学习实战
3.1 数据集加载
(1)本实验可直接通过TensorFlow2.0的内置函数加载minist数据集,TensorFlow2.0实现方式为:
# 加载MNIST数据集,返回的是两个元组,分别表示训练集和测试集
(x, y), (x_val, y_val) = datasets.mnist.load_data()
(2)将数据集格式转换为张量,方便进行张量运算,并且将灰度值缩放到0-1,方便训练。
x = tf.convert_to_tensor(x, dtype=tf.float32)/255. # 转换为张量,并缩放到0~1
y = tf.convert_to_tensor(y, dtype=tf.int32) # 转换为张量(标签)
(3)构建数据集对象,设置batch和epos。
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 构建数据集对象
train_dataset = train_dataset.batch(32).repeat(10) # 设置批量训练的batch为32,要将训练集重复训练10遍
3.2 网络结构搭建
由于MNIST数据集里的图像特征较为简单,所以本次以搭建一个3层的全连接网络为例,来实现MNIST数据集10分类任务。其中,每个全连接层的节点数分别为:256,128和10。
# 网络搭建
network = Sequential([
layers.Dense(256, activation='relu'), # 第一层
layers.Dense(128, activation='relu'), # 第二层
layers.Dense(10) # 输出层
])
network.build(input_shape=(None, 28*28)) # 输入
network.summary() # 打印出每层的参数列表
3.3 模型装配与训练
搭建好网络结构后,首先要对网路模型装配,指定网络使用的优化器对象,损失函数,评价指标等。然后对网络模型进行训练,在这过程中,要将数据送入神经网络进行训练,同时建立好梯度记录环境,最终打印出图片分类精度的测试结果。
optimizer = optimizers.SGD(lr=0.01) # 声明采用批量随机梯度下降方法,学习率=0.01
acc_meter = metrics.Accuracy() # 创建准确度测量器
for step, (x, y) in enumerate(train_dataset): # 一次输入batch组数据进行训练
with tf.GradientTape() as tape: # 构建梯度记录环境
x = tf.reshape(x, (-1, 28*28)) # 将输入拉直,[b,28,28]->[b,784]
out = network(x) # 输出[b, 10]
y_onehot = tf.one_hot(y, depth=10) # one-hot编码
loss = tf.square(out - y_onehot)
loss = tf.reduce_sum(loss)/32 # 定义均方差损失函数,注意此处的32对应为batch的大小
grads = tape.gradient(loss, network.trainable_variables) # 计算网络中各个参数的梯度
optimizer.apply_gradients(zip(grads, network.trainable_variables)) # 更新网络参数
acc_meter.update_state(tf.argmax(out, axis=1), y) # 比较预测值与标签,并计算精确度
if step % 200 == 0: # 每200个step,打印一次结果
print('Step', step, ': Loss is: ', float(loss), ' Accuracy: ', acc_meter.result().numpy())
acc_meter.reset_states() # 每一个step后准确度清零
3.4 测试结果
在图像分类或识别任务中,经常会将预测精确度accuracy作为评价一个分类器好坏的指标。当accuracy越接近1(100%)时,说明该分类器的预测效果越好。
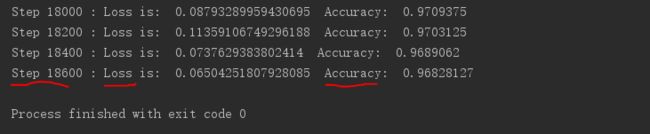
下图展示了训练结束时的一个测试结果。可以看到,此时训练集上的准确度达到了97%左右,已经很接近1了,继续训练应该可以得到更高的精确度。
四、完整程序清单(附详细注释)
import tensorflow as tf # 导入TF库
from tensorflow.keras import layers, optimizers, datasets, Sequential, metrics # 导入TF子库
# 1.数据集准备
(x, y), (x_val, y_val) = datasets.mnist.load_data() # 加载数据集,返回的是两个元组,分别表示训练集和测试集
x = tf.convert_to_tensor(x, dtype=tf.float32)/255. # 转换为张量,并缩放到0~1
y = tf.convert_to_tensor(y, dtype=tf.int32) # 转换为张量(标签)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 构建数据集对象
train_dataset = train_dataset.batch(32).repeat(10) # 设置批量训练的batch为32,要将训练集重复训练10遍
# 2.网络搭建
network = Sequential([
layers.Dense(256, activation='relu'), # 第一层
layers.Dense(128, activation='relu'), # 第二层
layers.Dense(10) # 输出层
])
network.build(input_shape=(None, 28*28)) # 输入
# network.summary()
# 3.模型训练(计算梯度,迭代更新网络参数)
optimizer = optimizers.SGD(lr=0.01) # 声明采用批量随机梯度下降方法,学习率=0.01
acc_meter = metrics.Accuracy() # 创建准确度测量器
for step, (x, y) in enumerate(train_dataset): # 一次输入batch组数据进行训练
with tf.GradientTape() as tape: # 构建梯度记录环境
x = tf.reshape(x, (-1, 28*28)) # 将输入拉直,[b,28,28]->[b,784]
out = network(x) # 输出[b, 10]
y_onehot = tf.one_hot(y, depth=10) # one-hot编码
loss = tf.square(out - y_onehot)
loss = tf.reduce_sum(loss)/32 # 定义均方差损失函数,注意此处的32对应为batch的大小
grads = tape.gradient(loss, network.trainable_variables) # 计算网络中各个参数的梯度
optimizer.apply_gradients(zip(grads, network.trainable_variables)) # 更新网络参数
acc_meter.update_state(tf.argmax(out, axis=1), y) # 比较预测值与标签,并计算精确度
if step % 200 == 0: # 每200个step,打印一次结果
print('Step', step, ': Loss is: ', float(loss), ' Accuracy: ', acc_meter.result().numpy())
acc_meter.reset_states() # 每一个step后准确度清零