概率论与随机过程笔记(1):样本空间与概率
概率论与随机过程笔记(1):样本空间与概率
2019-10-27
这部分的笔记依据Dimitri P. Bertsekas和John N. Tsitsiklis的《概率导论》第1章内容(不包括1.6节组合数学的内容)。鉴于线性代数的笔记中大量latex公式输入中,切换中英文输入法浪费了很多时间,所以概率笔记会用英文完成。
1.1 集合(sets)
【集合的定义】A set is a collection of objects, which are the elements of the set. If S S S is a set and x x x is an element of S S S, we write x ∈ S x \in S x∈S. If x x x is not an element of S S S, we write x ∉ S x \notin S x∈/S. A set can have no elements, in which case it is called the empty set, denoted by ∅ \varnothing ∅
【集合的表示方法】Sets can be specified in a variety of ways:
S = { x 1 , x 2 , ⋯ , x n } S=\{x_1,x_2,\cdots,x_n\} S={x1,x2,⋯,xn} S = { x 1 , x 2 , ⋯ } S=\{x_1,x_2,\cdots\} S={x1,x2,⋯} { x ∣ x s a t i s f i e s P } \{x \vert x \; satisfies \; P \} {x∣xsatisfiesP}
The symbol “ ∣ \vert ∣” is to be read as “such that.”
【集合之间的关系】If every element of a set S S S is also an element of a set T T T, we say that S S S is a subset of T T T, and we write S ⊂ T S \subset T S⊂T or T ⊃ S T \supset S T⊃S. If S ⊂ T S \subset T S⊂T and T ⊂ S T \subset S T⊂S, the two sets are equal, and we write S = T S = T S=T.
【空间 Ω \Omega Ω】It is also expedient to introduce a universal set, denoted by Ω \Omega Ω, which contains all objects that could conceivably be of interest in a particular context. Having specified the context in terms of a universal set Ω \Omega Ω, we only consider sets S S S that are subsets of Ω \Omega Ω.
【补集】The complement of a set S S S, with respect to the universe Ω \Omega Ω, is the set { x ∈ Ω ∣ x ∉ S } \{x\in \Omega \vert x \notin S\} {x∈Ω∣x∈/S} of all the elements of Ω \Omega Ω that do not belong to S S S, and is denoted by S c S^c Sc. Note that Ω c = ∅ \Omega^c = \varnothing Ωc=∅.
【集合的交和并】The union of two sets S S S and T T T is the set of all elements that belong to S S S or T T T (or both), and is denoted by S ∪ T S \cup T S∪T. The intersection of two sets S S S and T T T is the set of all elements that belong to both S S S and T T T, and is denoted by S ∩ T S \cap T S∩T. Thus, S ∪ T = { x ∣ x ∈ S o r x ∈ T } S \cup T=\{x \;\vert \;x \in S \;or \;x \in T\} S∪T={x∣x∈Sorx∈T} S ∩ T = { x ∣ x ∈ S a n d x ∈ T } S \cap T=\{x \;\vert \;x \in S \;and \;x \in T\} S∩T={x∣x∈Sandx∈T} ⋃ n = 1 ∞ = S 1 ∪ S 2 ⋯ = { x ∣ x ∈ S n f o r s o m e n } \bigcup_{n=1}^\infty = S_1 \cup S_2 \cdots = \{x\;\vert\;x \in S_n \;for \;some \;n\} n=1⋃∞=S1∪S2⋯={x∣x∈Snforsomen} ⋂ n = 1 ∞ = S 1 ∩ S 2 ⋯ = { x ∣ x ∈ S n f o r a l l e n } \bigcap_{n=1}^\infty = S_1 \cap S_2 \cdots = \{x\;\vert\;x \in S_n \;for \;alle \;n\} n=1⋂∞=S1∩S2⋯={x∣x∈Snforallen}
【不想交 & 分割】Two sets are said to be disjoint if their intersection is empty. More generally, several sets are said to be disjoint if no two of them have a common element. A collection of sets is said to be a partition of a set S S S if the sets in the collection are disjoint and their union is S S S.
If x x x and y y y are two objects. we use ( x . y ) (x. y) (x.y) to denote the ordered pair of x x x and y y y. The set of scalars (real numbers) is denoted by R \mathbb{R} R: the set of pairs (or triplets) of scalars, i.e … the two-dimensional plane (or three-dimensional space, respectively) is denoted by R 2 \mathbb{R}^2 R2 (or R 3 \mathbb{R}^3 R3. respectively).
Sets and the associated operations are easy to visualize in terms of Venn diagrams. as illustrated in Fig. 1.1.
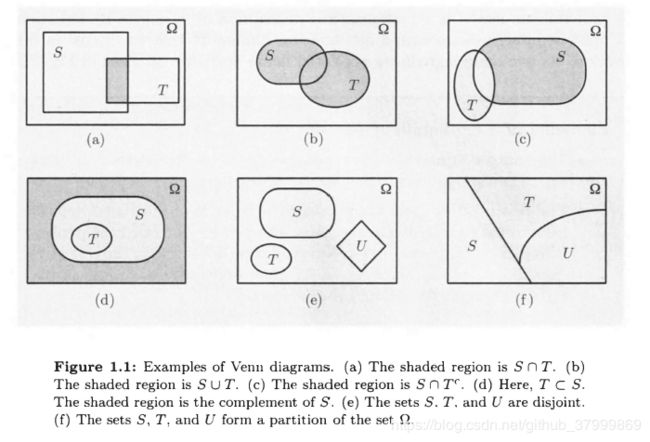
【矩阵代数】Set operations have several properties, which are elementary consequences of the definitions. Some exa1nples are:
- S ∪ T = T ∪ S S \cup T = T\cup S S∪T=T∪S
- S ∪ ( T ∪ U ) = ( S ∪ T ) ∪ U S \cup (T \cup U) = (S \cup T) \cup U S∪(T∪U)=(S∪T)∪U
- S ∩ ( T ∪ U ) = ( S ∩ T ) ∪ ( S ∩ U ) S \cap(T \cup U) = (S \cap T)\cup(S \cap U) S∩(T∪U)=(S∩T)∪(S∩U)
- S ∪ ( T ∩ U ) = ( S ∪ T ) ∩ ( S ∪ U ) S \cup(T \cap U) = (S \cup T)\cap(S \cup U) S∪(T∩U)=(S∪T)∩(S∪U)
- ( S c ) c = S (S^c)^c=S (Sc)c=S
- S ∩ S c = ∅ S \cap S^c = \varnothing S∩Sc=∅
- S ∪ Ω = Ω S \cup \Omega = \Omega S∪Ω=Ω
- S ∩ Ω = S S \cap \Omega = S S∩Ω=S
Two particularly useful properties are given by De Morgan’s laws which state that: ( ⋃ n S n ) c = ⋂ n S n c (\bigcup_n S_n)^c=\bigcap_n S_{n}^c (n⋃Sn)c=n⋂Snc ( ⋂ n S n ) c = ⋃ n S n c (\bigcap_n S_n)^c=\bigcup_n S_{n}^c (n⋂Sn)c=n⋃Snc
1.2 概率模型(probablistic models)
A probabilistic model is a mathematical description of an uncertain situation.Its two main ingredients are listed below and are visualized in Fig. 1.2.
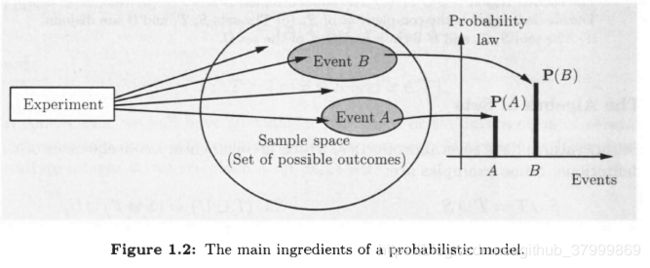
Elements of a Probabilistic Model:
- The sample space Ω \Omega Ω, which is the set of all possible outcomes of an experiment.
- The probability law, which assigns to a set A A A of possible outcomes (also called an event) a nonnegative number P ( A ) P(A) P(A) (called the probability of A A A) that encodes our knowledge or belisf about the collective “likelihood” of the elements of A A A.
【样本空间和事件】Every probabilistic model involves an underlying process, called the experiment, that will produce exactly one out of several possible outcomes. The set of all possible outcomes is called the sample space of the experiment, and is denoted by Ω \Omega Ω. A subset of the sample space, that is, a collection of possible outcomes, is called an event. here is no restriction on what constitutes an experiment.
The sample space of an experiment may consist of a finite or an infinite number of possible outcomes. Finite sample spaces are conceptually and mathematically simpler.
Generally, the sample space chosen for a probabilistic model must be collectively exhaustive, in the sense that no matter what happens in the experiment, we always obtain an outcome that has been included in the sample space. In addition, the sample space should have enough detail to distinguish between all outcomes of interest to the modeler, while avoiding irrelevant details.
【概率律(probability law.)】the probabilitylaw assigns to every event A A A. a number P ( A ) P(A) P(A), called the probability of A A A. satisfying the following axioms:
- (Nonnegativity) P ( A ) ≥ 0 P(A) \ge 0 P(A)≥0, for every event A A A
- (Additivity) If A A A and B B B are two disjoint events, then the probability of their union satisfies P ( A ∪ B ) = P ( A ) + P ( B ) P(A \cup B) = P(A) + P(B) P(A∪B)=P(A)+P(B). More generally, if the sample space has an infinite number of elements and A 1 A_1 A1, A 2 A_2 A2, ⋯ \cdots ⋯ is a sequence of disjoint events, then the probability of their union satifies P ( A 1 ∪ A 2 ∪ ⋯ ) = P ( A 1 ) + P ( A 2 ) + ⋯ P(A_1 \cup A_2 \cup \cdots) = P(A_1) + P(A_2) + \cdots P(A1∪A2∪⋯)=P(A1)+P(A2)+⋯
- (Normalization) The probability of the entire sample space Ω \Omega Ω is equal to 1, that is, P ( Ω ) = 1 P(\Omega)=1 P(Ω)=1
【离散概率律(Discrete Probability Law)】If the sample space consists of a finite number of possible outcomes, then the probability law is specified by the probabilities of the events that consist of a single element. In particular, the probability of any event { s 1 , s 2 , ⋯ , s n } \{s_1,s_2,\cdots,s_n\} {s1,s2,⋯,sn} is the sum of the probabilities of its elements: P ( { s 1 , s 2 , ⋯ , s n } ) = P ( s 1 ) + P ( s 2 ) + ⋯ + P ( s n ) P(\{s_1,s_2,\cdots, s_n\})=P(s_1)+P(s_2)+\cdots+P(s_n) P({s1,s2,⋯,sn})=P(s1)+P(s2)+⋯+P(sn)
【离散均匀概率律(古典模型)(Discrete Uniform Probability Law)】In the special case where the probabilities P ( s 1 ) , ⋯ , P ( s n ) P(s_1),\cdots,P(s_n) P(s1),⋯,P(sn) are all the same (by necessity equal to 1 / n 1/n 1/n, in view of the normalization axiom). If the sample space consists of n possible outcomes which are equally likely (i.e, all single-element events have he same probability), then the probability of any event A A A is given by P ( A ) = n u m b e r o f e l e m e n t s o f A n P(A) = \frac{number\;of\;elements\;of \;A}{n} P(A)=nnumberofelementsofA
【连续模型】Probabilistic models with continuous sample spaces differ from their discrete counterparts in that the probabilities of the single-element events may not be sufficient to characterize the probability law. This is illustrated in the following examples, which also indicate how to generalize the uniform probability law to the case of a continuous sample space.
A wheel of fortune is continuously calibrated from 0 to 1, so the possible outcomes of an experiment consisting of a single spin are the numbers in the interval n = [ 0 , 1 ] n = [0, 1] n=[0,1]. Assuming a fair wheel, it is appropriate to consider all outcomes equally likely, but what is the probability of the event consisting of a single element? It cannot be positive, because then, using the additivity axiom, it would follow that events with a sufficiently large number of elements would have probability larger than 1. Therefore, the probability of any event that consists of a single element must be 0.
In this example, it makes sense to assign probability b − a b - a b−a to any subinterval [ a , b ] [a, b] [a,b] of [ 0 , 1 ] [0, 1] [0,1], and to calculate the probability of a more complicated set by evaluating its “length”. ( ∫ S d t \int_{S}dt ∫Sdt) This assignment satisfies the three probability axioms and qualifies as a legitimate probability law.
【概率律的性质】Probability laws have a number of properties, which can be deduced from the axioms. Some of them are summarized below.
- if A ⊂ B A \subset B A⊂B, then P ( A ) ≤ P ( B ) P(A) \le P(B) P(A)≤P(B).
- P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B ) P(A \cup B) = P(A) + P(B) - P(A \cap B) P(A∪B)=P(A)+P(B)−P(A∩B)
- P ( A ∪ B ) ≤ P ( A ) + P ( B ) P(A \cup B) \le P(A) + P(B) P(A∪B)≤P(A)+P(B)
- P ( A ∪ B ∪ C ) = P ( A ) + P ( A c ∩ B ) + P ( A c ∩ B c ∩ C ) P(A \cup B \cup C) = P(A) + P(A^c \cap B)+ P(A^c \cap B^c \cap C) P(A∪B∪C)=P(A)+P(Ac∩B)+P(Ac∩Bc∩C)
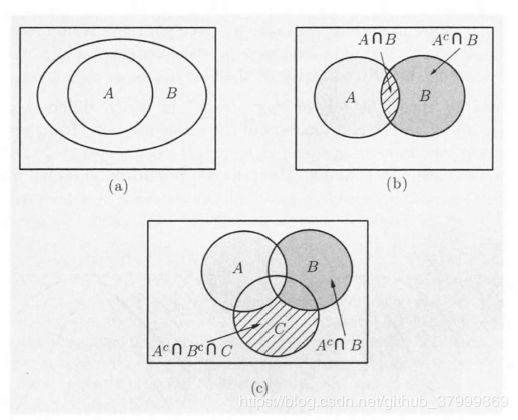
These properties, and other similar ones:
- P ( A 1 ∪ A 2 ∪ ⋯ ∪ A n ) ≤ ∑ i = 1 n P ( A i ) P(A_1 \cup A_2 \cup \cdots \cup A_n) \le \sum\limits_{i=1}^{n}P(A_i) P(A1∪A2∪⋯∪An)≤i=1∑nP(Ai)
- P ( A 1 ∪ A 2 ∪ ⋯ ∪ A n ) ≤ P ( A 1 ) + P ( A 2 ∪ ⋯ ∪ A n ) P(A_1 \cup A_2 \cup \cdots \cup A_n) \le P(A_1) + P(A_2 \cup \cdots \cup A_n) P(A1∪A2∪⋯∪An)≤P(A1)+P(A2∪⋯∪An)
1.3 条件概率(conditional probability)
Conditional probability provides us with a way to reason about the outcome of an experiment, based on partial information. In more precise terms, given an experiment, a corresponding sample space, and a probability law, suppose that we know that the outcome is within some given event B B B. We wish to quantify the likelihood that the outcome also belongs to some other given event A A A. We thus seek to construct a new probability law that takes into account the available knowledge: a probability law that for any event A. specifies the conditional probability of A A A given B B B. denoted by P ( A ∣ B ) P(A \vert B) P(A∣B).
We would like the conditional probabilities P ( A ∣ B ) P(A \vert B) P(A∣B) of different events A A A to constitute a legitimate probability law, which satisfies the probability axioms. Generalizing the argument, we introduce the following definition of conditional probability: P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A \vert B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)In words, out of the total probability of the elements of B B B, P ( A ∣ B ) P(A \vert B) P(A∣B) is the fraction that is assigned to possible outcomes that also belong to A A A.
【条件概率的概率律/性质】
- The conditional probability of an event A A A, given an event B B B with P ( B ) > 0 P(B) >0 P(B)>0, is defined by P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A \vert B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B) and specifies a new (conditional) probability law on the same sample space Ω \Omega Ω. In particular, all properties of probability laws remain valid for conditional probability laws.
- Conditional probabilities can also be viewed as a probability law on a new universe B B B, because all of the conditional probability is concentrated on B B B.
- If the possible outcomes are finitely many and equally likely, then P ( A ∣ B ) = n u m b e r o f e l e m e n t s o f A ∩ B n u m b e r o f e l e m e n t s o f B P(A \vert B) = \frac{number \; of \;elements \; of \; A \cap B}{number \; of \; elements \; of \; B} P(A∣B)=numberofelementsofBnumberofelementsofA∩B
【利用条件概率定义概率模型】When constructing probabilistic models for experiments that have a sequential character, it is often natural and convenient to first specify conditional probabilities and then use them to determine unconditional probabilities. The rule P ( A ∩ B ) = P ( B ) P ( A ∣ B ) P(A \cap B) = P(B)P(A \vert B) P(A∩B)=P(B)P(A∣B), which is a restatement of the definition of conditional probability, is often helpful in this process.
【贯序树形图】We have a general rule for calculating various probabilities in conjunction with a tree-based sequential description of an experiment. In particular:
- We set up the tree so that an event of interest is associated with a leaf. We view the occurrence of the event as a sequence of steps, namely, the traversals of the branches along the path fron1 the root to the leaf.
- We record the conditional probabilities associated with the branches of the tree.
- We obtain the probability of a leaf by multiplying the probabilities recorded along the corresponding path of the tree.
In mathematical terms, we are dealing with an event A A A which occurs if and only if each one of several events A 1 , ⋯ , A n A_1, \cdots, A_n A1,⋯,An has occurred, i.e., A = A 1 ∩ A 2 ∩ ⋅ ⋅ ⋅ ∩ A n A = A_1 \cap A_2 \cap · · ·\cap A_n A=A1∩A2∩⋅⋅⋅∩An. The occurrence of A A A is viewed as an occurrence of A 1 A_1 A1 , followed by the occurrence of A 2 A_2 A2, then of A 3 A_3 A3, etc., and it is visualized as a path with n branches, corresponding to the events A 1 , ⋯ , A n A_1, \cdots , A_n A1,⋯,An. The probability of A A A is given by the following rule:
Multiplication Rule: Assuming that all of the conditioning events have positive probability, we have P ( ⋂ i = 1 n A i = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 ∩ A 2 ) ⋯ P ( A n ∣ ⋂ i = 1 n − 1 A i ) P(\bigcap_{i=1}^n A_i = P(A_1) P(A_2 \vert A_1) P(A_3 \vert A_1 \cap A_2) \cdots P(A_n \vert \bigcap_{i=1}^{n-1} A_i) P(i=1⋂nAi=P(A1)P(A2∣A1)P(A3∣A1∩A2)⋯P(An∣i=1⋂n−1Ai)
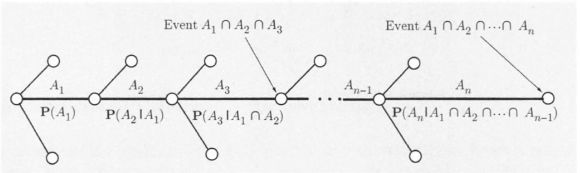
Visualization of the multiplication rule. The intersection event
A = A 1 ∩ A 2 ∩ ⋯ ∩ A n A = A_1 \cap A_2 \cap \cdots \cap A_n A=A1∩A2∩⋯∩An is associated with a particular path on a tree that describes the experiment. We associate the branches of this path with the events A 1 ⋯ A n A_1 \cdots A_n A1⋯An. and we record next to the branches the corresponding conditional probabilities.
The final node of the path corresponds to the intersection event A, and its probability is obtained by multiplying the conditional probabilities recorded along the branches of the path
1.4 全概率定理与贝叶斯准则(total probability theorem and Bayes’ rule)
【全概率定理(Total Probability Theorem)】Let A 1 , ⋯ , A n A_1, \cdots, A_n A1,⋯,An be disjoint events that form a partition of the sample space (each possible outcome is included in exactly one of the events A 1 , ⋯ , A n A_1, \cdots, A_n A1,⋯,An) and assume that P ( A i ) > 0 P(A_i) > 0 P(Ai)>0, for all i i i. Then, for any event B B B, we have P ( B ) = P ( A 1 ∩ B ) + P ( A 2 ∩ B ) + ⋯ + P ( A n ∩ B ) P(B) = P(A_1 \cap B) + P(A_2 \cap B) + \cdots + P(A_n \cap B) P(B)=P(A1∩B)+P(A2∩B)+⋯+P(An∩B) = P ( A 1 ) P ( B ∣ A 1 ) + ⋯ + P ( A n ) P ( B ∣ A n ) =P(A_1)P(B \vert A_1) + \cdots + P(A_n)P(B \vert A_n) =P(A1)P(B∣A1)+⋯+P(An)P(B∣An) 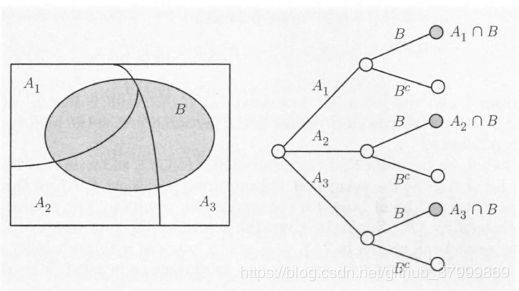
【贝叶斯准则】The total probability theorem is often used in conjunction with the following celebrated theorem, which relates conditional probabilities of the form P ( A ∣ B ) P(A \vert B) P(A∣B) with conditional probabilities of the form P ( B ∣ A ) P(B \vert A) P(B∣A), in which the order of the conditioning is reversed.
Let A 1 , A 2 , ⋯ , A n A_1, A_2, \cdots, A_n A1,A2,⋯,An be disjoint events that form a partition of the sample space, and assume that P ( A i ) > 0 P(A_i) > 0 P(Ai)>0, for all i i i. Then, for any event B B B such that P ( B ) > 0 P(B) > 0 P(B)>0, we have P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) P ( B ) P(A_i \vert B) = \frac{P(A_i)P(B \vert A_i)}{P(B)} P(Ai∣B)=P(B)P(Ai)P(B∣Ai) = P ( A i ) P ( B ∣ A i ) P ( A 1 ) P ( B ∣ A 1 ) + ⋯ + P ( A n ) P ( B ∣ A n ) =\frac{P(A_i)P(B \vert A_i)}{P(A_1)P(B \vert A_1) + \cdots + P(A_n)P(B \vert A_n)} =P(A1)P(B∣A1)+⋯+P(An)P(B∣An)P(Ai)P(B∣Ai)
To verify Bayes’rule. note that by the definition of conditional probability, we have P ( A i ∩ B ) = P ( A i ) P ( B ∣ A i ) = P ( B ) P ( A i ∣ B ) P(A_i \cap B) = P(A_i)P(B \vert A_i) = P(B) P(A_i \vert B) P(Ai∩B)=P(Ai)P(B∣Ai)=P(B)P(Ai∣B) This yields the first equality. The second equality follows from the first by using the total probability theorem to rewrite P ( B ) P(B) P(B).
Bayes’rule is often used for inference. There are a number of “causes” that may result in a certain “effect.” We observe the effect, and we wish to infer the cause. The events A 1 , ⋯ , A n A_1, \cdots, A_n A1,⋯,An are associated with the causes and the event B B B represents the effect. The probability P ( B ∣ A i ) P(B \vert A_i) P(B∣Ai) that the effect will be observed when the cause A i A_i Ai is present amounts to a probabilistic model of the cause-effect relation. Given that the effect B B B has been observed, we wish to evaluate the probability P ( A i ∣ B ) P(A_i \vert B) P(Ai∣B) that the cause A i A_i Ai is present. We refer to P ( A i ∣ B ) P(A_i \vert B) P(Ai∣B) as the posterior probability of event A i A_i Ai given the information, to be distinguished from P ( A i ) P(A_i) P(Ai), which we call the prior probability
1.5 独立性
We have introduced the conditional probability P ( A ∣ B ) P(A \vert B) P(A∣B) to capture the partial information that event B B B provides about event A A A. An interesting and important special case arises when the occurrence of B B B provides no such information and does not alter the probability that A A A has occurred, i.e., P ( A ∣ B ) = P ( A ) P(A \vert B) = P(A) P(A∣B)=P(A).
When the above equality holds. we say that A A A is independent of B B B. Note that P ( A ∩ B ) = P ( A ) P ( B ) P(A \cap B) = P(A)P(B) P(A∩B)=P(A)P(B)We adopt this latter relation as the definition of independence because it can be used even when P ( B ) = 0 P(B) = 0 P(B)=0, in which case P ( A ∣ B ) P(A \vert B) P(A∣B) is undefined. The symmetry of this relation also implies that independence is a symmetric property; that is, if A A A is independent of B B B, then B B B is independent of A A A, and we can unambiguously say that A A A and B B B are independent events.
If A A A and B B B are independent, the occurrence of B B B does not provide any new information on the probability of A A A occurring. It is then intuitive that the non-occurrence of B B B should also provide no information on the probability of A A A. Indeed. it can be verified that if A A A and B B B are independent, the same holds true for A A A and B c B^c Bc.
【条件独立】In particular, given an event C. the events A and B are called conditionally independent if P ( A ∩ B ∣ C ) = P ( A ∣ C ) P ( B ∣ C ) P(A \cap B \vert C) = P(A \vert C)P(B \vert C) P(A∩B∣C)=P(A∣C)P(B∣C)
To derive an alternative characterization of conditional independence, we use the definition of the conditional probability and the multiplication rule, to write P ( A ∩ B ∣ C ) = P ( A ∩ B ∩ C ) P ( C ) P(A \cap B \vert C) = \frac{P(A \cap B \cap C)}{P(C)} P(A∩B∣C)=P(C)P(A∩B∩C) = P ( C ) P ( B ∣ C ) P ( A ∣ B ∩ C ) P ( C ) =\frac{P(C) P(B \vert C) P(A \vert B \cap C)}{P(C)} =P(C)P(C)P(B∣C)P(A∣B∩C) = P ( B ∣ C ) P ( A ∣ B ∩ C ) =P(B \vert C) P(A \vert B \cap C) =P(B∣C)P(A∣B∩C) We now compare the preceding two expressions. and after eliminating the common factor P ( B ∣ C ) P(B \vert C) P(B∣C), assumed nonzero. we see that conditional independence is the same as the condition P ( A ∣ B ∩ C ) = P ( A ∣ C ) P(A \vert B \cap C) = P(A \vert C ) P(A∣B∩C)=P(A∣C) In words, this relation states that if C C C is known to have occurred, the additional knowledge that B B B also occurred does not change the probability of A A A.
【多个事件相互独立】We say that the events A 1 , A 2 , ⋯ , A n A_1, A_2,\cdots, A_n A1,A2,⋯,An are independent if P ( ⋂ i ∈ S A i ) = ∏ i ∈ S P ( A i ) P(\bigcap_{i \in S}A_i) = \prod_{i \in S} P(A_i) P(i∈S⋂Ai)=i∈S∏P(Ai) for every subset S S S of { 1 , 2 , ⋯ , n } \{1,2,\cdots, n\} {1,2,⋯,n}
【独立实验和二项概率】If an experiment involves a sequence of independent but identical stages, we say that we have a sequence of independent trials. In the special case where there are only two possible results at each stage, we say that we have a sequence of independent Bernoulli trials. The two possible results can be anything, e.g., “it rains” or “it doesn’t rain,” but we will often think in terms of coin tosses and refer to the two results as’“heads” ( H H H) and "tails·’( T T T).
Consider an experiment that consists of n independent tosses of a coin, in which the probability of heads is p p p, where p p p is some number between 0 and 1. In this context, independence means that the events A 1 , A 2 , ⋯ , A n A_1, A_2, \cdots ,A_n A1,A2,⋯,An are independent, where A i A_i Ai = { i i ith toss is a head}.
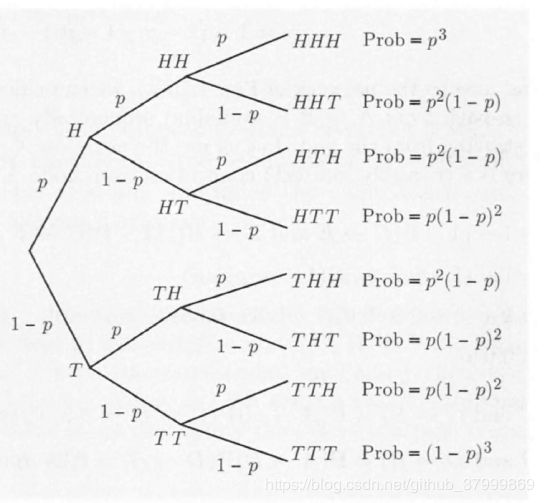
p ( k ) = P ( k p(k)=P(k p(k)=P(k heads come up in an n-toss sequence ) ) ),which will play an important role later. We showed above that the probability of any given sequence that contains k heads is p k ( I − p ) n − k p^k(I - p)^{n-k} pk(I−p)n−k, so we have p ( k ) = ( n k ) p k ( 1 − p ) n − k p(k) = {n \choose k}p^k(1-p)^{n-k} p(k)=(kn)pk(1−p)n−kwhere we use the notation ( n k ) { n \choose k} (kn) means number of distinct n n n-toss sequences that contain k k k heads. ( n k ) = n ! k ! ( n − k ) ! {n \choose k} = \frac{n!}{k!(n-k)!} (kn)=k!(n−k)!n!An alternative verification is sketched in the end-ofchapter problems. Note that the binomial probabilities p ( k ) p(k) p(k) must add to 1, thus showing the binomial formula ∑ k = 0 n ( n k ) p k ( 1 − p ) n − k = 1 \sum_{k=0}^n {n \choose k}p^k(1-p)^{n-k}=1 k=0∑n(kn)pk(1−p)n−k=1