openCL缓存对象的传输与映射
用GPU进行加速运行运算时,通常首先将数据copy(clEnqueueWriteBuffer)到GPU缓存对象,运算结束后,再将数据copy(clEnqueueReadBuffer)到内存;OpenCL提供了内存映射机制,无需读写操作,将设备上的内存映射到主机上,便可以通过指针方式直接修改主机上的内存对象,内存映射的运行性能远远高于普通的读写函数。
用OpenCL来操作映射内存中的数据通常分为三步:
Step1:调用函数clEnqueueMapBuffer或函数clEnqueueMapImage,将内存映射命令人列;
Step2:使用诸如memcpy之类的函数,对内存中的数据进行传输操作。
Step3:调用clEnqueueUnmapMemObject函数解映射。
5.clCreateBuffer(cl_context, //上下文
cl_mem_flags, //内存对象的性质,见下表
size_t, //内存对象数据块大小
void *, //host_ptr主机数据内存地址(可以为空)
cl_int *) // err错误码| cl_mem_flags: |
|
| CL_MEM_READ_WRITE(默认) |
这三个是很好理解的,指明的是在kernel中对该缓冲区的访问权限:读写,只写,只读。限制设备的读写权限的,而不是主机端读写权限。 |
| CL_MEM_WRITE_ONLY |
|
| CL_MEM_READ_ONLY |
|
| CL_MEM_COPY_HOST_PTR |
|
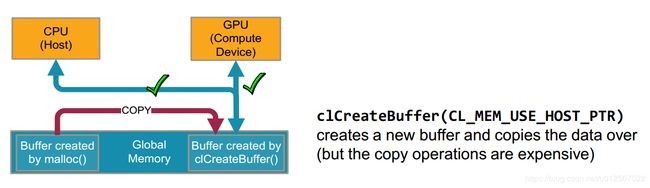
| CL_MEM_USE_HOST_PTR |
|
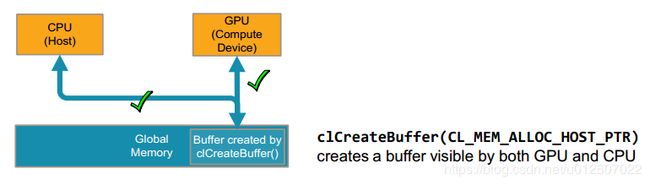
| CL_MEM_ALLOC_HOST_PTR |
|
| 后三个参数中,如果主机端的数据直接传输后不需要再读取结果,就使用CL_MEM_COPY_HOST_PTR, 如果数据需要再读取回来,则可以使用CL_MEM_ALLOC_HOST_PTR和CL_MEM_COPY_HOST_PTR一起或者CL_MEM_USE_HOST_PTR |
|
demo:
#include
#include
#include
#include
#include
#include
#ifdef MAC
#include
#else
#include
#endif
#ifdef WIN32
#include
#include
#include
#include
#else
#include
#include
#endif
#define MAX_SOURCE_SIZE (0x100000)
#define LENGTH 10
#define KERNEL_FUNC "addVec"
//#define MEM_MAP //映射内存对象
int main(void)
{
cl_platform_id *platformALL = NULL;
cl_uint ret_num_platforms;
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_context context = NULL;
cl_command_queue command_queue = NULL;
cl_program program = NULL;
cl_kernel kernel = NULL;
cl_int ret, err;
const char *kernel_src_str = "\n" \
"__kernel void addVec(__global int *dataSrc){"\
"float16 aa; int idx = get_global_id(0);"\
"if (idx<10){"\
" dataSrc[idx] += 10;"\
"}}";
//Step1:获取平台列表
err = clGetPlatformIDs(0, NULL, &ret_num_platforms);
if (ret_num_platforms<1)
{
printf("Error: Getting Platforms; err = %d,numPlatforms = %d !", err, ret_num_platforms);
}
printf("Num of Getting Platforms = %d!\n", ret_num_platforms);
platformALL = (cl_platform_id *)alloca(sizeof(cl_platform_id) * ret_num_platforms);
ret = clGetPlatformIDs(ret_num_platforms, platformALL, &ret_num_platforms);
//Step2:获取指定设备,platformALL[0],platformALL[1]...
//带有独显的PC,选择intel核显或独显
ret = clGetDeviceIDs(platformALL[0], CL_DEVICE_TYPE_DEFAULT, 1, &device_id, &ret_num_devices);
char nameDevice[64];
clGetDeviceInfo(device_id, CL_DEVICE_NAME, sizeof(nameDevice), &nameDevice, NULL);
printf("Device Name: %s\n", nameDevice);
//Step3:创建上下文
context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
if (ret < 0)
{
printf("clCreateContext Fail,ret =%d\n", ret);
exit(1);
}
//Step4:创建命令队列
command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
if (ret < 0)
{
printf("clCreateCommandQueue Fail,ret =%d\n", ret);
exit(1);
}
//Step5:创建程序
program = clCreateProgramWithSource(context, 1, (const char **)&kernel_src_str, NULL, &ret);
if (ret < 0)
{
perror("clCreateProgramWithSource Fail\n");
exit(1);
}
//Step6:编译程序
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
if (ret < 0)
{
perror("clBuildProgram Fail\n");
exit(1);
}
//Step7:创建内核
kernel = clCreateKernel(program, KERNEL_FUNC, &ret);
if (ret < 0)
{
perror("clCreateKernel Fail\n");
exit(1);
}
printf("GPU openCL init Finish\n");
cl_mem clDataSrcBuf;
int dataSrcHost[LENGTH] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
//创建缓存对象
#ifdef MEM_MAP
clDataSrcBuf = clCreateBuffer(context, CL_MEM_READ_WRITE, 4 * LENGTH, NULL, &err);
#else
clDataSrcBuf = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR, 4 * LENGTH, dataSrcHost, &err);
#endif
if (err < 0)
{
printf("clCreateBuffer imgSrcBuf Fail,err=%d\n", err);
exit(1);
}
#ifdef MEM_MAP
cl_int * bufferMap = (cl_int *)clEnqueueMapBuffer(command_queue, clDataSrcBuf, CL_TRUE, CL_MAP_WRITE,
0, LENGTH * sizeof(cl_int), 0, NULL, NULL, NULL);
memcpy(bufferMap, dataSrcHost, 10 * sizeof(int));
#endif
//设置内核参数
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &clDataSrcBuf);
if (err < 0)
{
perror("clSetKernelArg imgDstBuf Fail\n");
exit(1);
}
printf("GPU openCL Create and set Buffter Finish\n");
cl_uint work_dim = 1;
size_t global_item_size = LENGTH;
err = clEnqueueNDRangeKernel(command_queue, kernel, work_dim, NULL, &global_item_size, NULL, 0, NULL, NULL);
clFinish(command_queue);
if (err < 0)
{
printf("err:%d\n", err);
perror("clEnqueueNDRangeKernel Fail\n");
}
#ifndef MEM_MAP
err = clEnqueueReadBuffer(command_queue, clDataSrcBuf, CL_TRUE, 0, (4 * LENGTH), dataSrcHost, 0, NULL, NULL);
if (err < 0)
{
printf("err:%d\n", err);
perror("Read buffer command Fail\n");
}
#endif
//print result
for (int i = 0; i < LENGTH; i++)
{
#ifdef MEM_MAP
printf("dataSrcHost[%d]:%d\n", i, bufferMap[i]);
#else
printf("dataSrcHost[%d]:%d\n", i, dataSrcHost[i]);
#endif
}
#ifdef MEM_MAP
err = clEnqueueUnmapMemObject(command_queue, clDataSrcBuf, bufferMap, 0, NULL, NULL);
#endif
/* OpenCL Object Finalization */
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
return 0;
}
参考:
https://www.cnblogs.com/zenny-chen/p/3640870.html
https://blog.csdn.net/wd1603926823/article/details/78144547