文本相似度:Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, NLI and QA
文章地址:https://arxiv.org/pdf/1806.04330.pdf
文章标题:Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering(用于意译识别、语义文本相似性、自然语言推理和问题回答的神经网络模型)CLOLING2018
源码地址:https://github.com/lanwuwei/SPM_toolkit
Abstract
在本文中,我们分析了几种用于句子对建模的神经网络设计(及其变体),并广泛比较了它们在八个数据集上的性能,包括释义识别、语义文本相似性、自然语言推理和问题回答任务。尽管这些模型中的大多数都声称拥有最先进的性能,但原始论文通常只对一两个选定的数据集进行了报告。我们提供一个系统的研究和证明:(i)编码上下文信息LSTM 句子内部交互至关重要。(ii) Tree-LSTM无助于此前声称一样但令人惊讶的是在Twitter上提高了性能数据集。(iii)增强的顺序推理模型(陈et al ., 2017)是最好的到目前为止对于更大的数据集,而两两字交互模型(他和林,2016)更少的数据可用时达到最佳的性能。我们将实现作为一个开源工具包发布。
一、Introduction
句子对建模是许多NLP任务的基础技术,包括以下内容:
- STS:语义文本相似度(STS),衡量成对文本片段的潜在语义的等价程度(Agirre et al., 2016)。
- PI:意译识别(PI),它识别两个句子是否表达相同的意思(多兰和布拉克特,2005;Xu et al., 2015)。
- NLI:自然语言推理(NLI),也被称为识别文本蕴涵(RTE),它关注一个假设是否可以从一个前提中推断出来,需要理解假设和前提之间的语义相似性(Dagan et al., 2006;Bowman等人,2015)。
- QA:问答(Question answer, QA),它可以近似为排名候选答案的句子或短语,基于其相似性的原始问题(Yang et al., 2015)。
- MC:机器理解(MC),它要求文章和问题之间的句子匹配,指出包含答案的文本区域(Rajpurkar等,2016)。
传统上,研究人员必须针对每个任务开发不同的方法。现在,神经网络可以通过端到端的训练,在相同的架构下完成上述所有任务。各种神经模型(He and Lin, 2016;陈等,2017;Parikh等人,2016;Wieting等人,2016;Tomar等,2017;Wang et al., 2017;沈等,2017a;Yin等人,2016)已经宣布了句子对建模任务的最新成果;然而,它们是经过精心设计的,并在选定的(通常是一两个)数据集上进行评估,这些数据集可以证明模型的优越性。研究问题如下:他们在其他任务和数据集上表现良好吗?某些系统设计选择和超参数优化带来了多少性能提升?
为了回答这些问题并更好地理解不同的网络设计,我们系统地分析和比较了不同任务和不同领域的最先进的神经模型。即我们实现5个模型及其变化在同一PyTorch平台:InferSent模型(Conneau et al ., 2017),Shortcut-stacked句子编码器模型(聂和邦萨尔,2017),两两字交互模型(他和林,2016),可分解的注意模型(帕里克说et al ., 2016)和增强的顺序推理模型(陈et al ., 2017)。他们代表两种最常见的方法:句子编码模型,学习向量表示个人的句子,然后计算句子之间的语义关系基于向量距离。句子对交互模型,使用某些词对齐机制(例如,注意力),并且inter-sentence交互。我们专注于识别重要的网络设计,并通过定量测量和深入分析提出了一系列发现,包括(1)整合句子间的相互作用至关重要;(2)Tree-Lstm的帮助并不像之前声称的那么多,但令人惊讶地提高了Twitter数据的性能;(3)增强型顺序推理模型在大数据集上的表现最为一致,两两字交互模型在小数据集上表现较好,而Shortcut-Stacked式句子编码器模型在Quora语料库上表现最好。我们将我们的实现作为工具包发布给研究团体。
二、General Framework for Sentence Pair Modeling(句子对建模的一般框架)
各种各样的神经网络被提出用于句子对建模,它们都属于两种类型的方法。句子编码方法将每个句子编码成一个固定长度的向量,然后直接计算句子的相似度。该模型具有网络设计简单、易于推广等优点。句子对交互方法将单词对齐和句子对之间的交互考虑在内,并且通常在域内数据上训练时表现得更好。在这里,我们概述了在相同的一般框架下的两种类型的神经网络:
- The Input Embedding Layer:输入嵌入层以单词的向量表示作为输入,其中预先训练好的单词嵌入是最常用的,例如GloVe (Pennington et al., 2014)或Word2vec (Mikolov et al., 2013)。有些作品使用了经过特殊训练的短语或句子对的嵌入 (Wieting and Gimpel, 2017; Tomar et al., 2017);一些人使用了子词嵌入,这显示了社交媒体数据的改善 (Lan and Xu, 2018)。
- The Context Encoding Layer:上下文编码层将单词上下文和序列顺序合并到建模中,以获得更好的向量表示。这一层通常使用CNN (He et al., 2015)、LSTM (Chen et al., 2017)、recursive neural network (Socher et al., 2011)或highway network (Gong et al., 2017)。模型的句子编码类型将在这一步停止,直接使用编码后的向量通过向量距离和/或输出分类层计算语义相似度。
- The Interaction and Attention Layer:交互和注意层使用编码层的输出来计算词对(或n-gram对)交互。这是模型的交互-聚合类型的关键组件。在PWIM模型中(He and Lin, 2016),通过余弦相似度、欧氏距离和向量的点积来计算相互作用。不同的模型对不同的交互作用赋予不同的权重,主要是模拟两个句子之间的单词对齐。对齐信息对于句子对建模是有用的,因为两个句子之间的语义关系很大程度上取决于对齐块的关系,如可解释语义文本相似性SemEval-2016任务(Agirre et al., 2016)所示。
- The Output Classification Layer:输出分类层采用CNN或MLP提取语义级特征,并应用softmax函数对每个类进行概率预测。
三、Representative Models for Sentence Pair Modeling(典型的句子对建模模型)
表1总结了近年来句子对建模的典型模型。特别地,我们深入研究了五个模型:两个代表句子编码类型的模型,三个代表交互聚合类型的模型。这些模型报告了具有不同体系结构设计(本节)和实现细节(第4.2节)的“最新技术”结果。
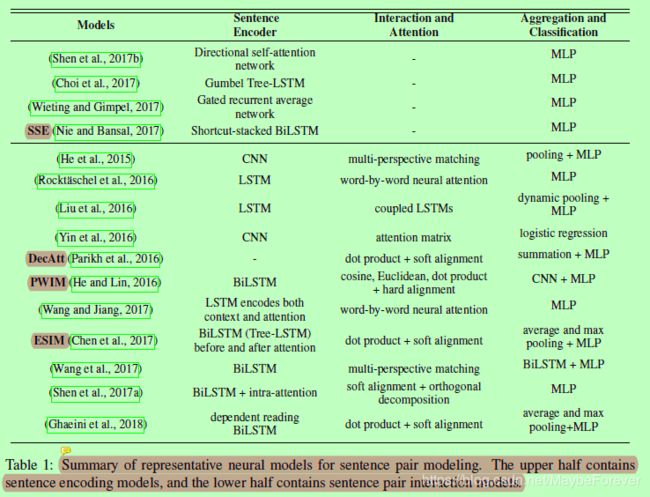
表一:典型的句子对建模神经模型综述。上半部分包含句子编码模型,下半部分包含句子对交互模型。
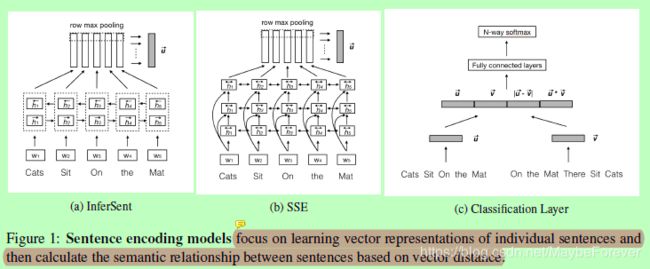
图一:句子编码模型侧重于单个句子的学习向量表示,然后基于向量距离计算句子之间的语义关系。
3.1 The Bi-LSTM Max-pooling Network (InferSent)
我们从InferSent中选择简单的Bi-LSTM最大池化网络:
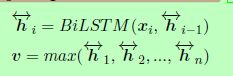
在自然语言推理数据集上训练时,它显示出比其他几种句子嵌入模型更好的迁移学习能力。
3.2 The Shortcut-Stacked Sentence Encoder Model (SSE)(简化叠加式句子编码器模型(SSE))
Shortcut-Stacked Sentence Encoder model (Nie and Bansal, 2017)是一个基于句子的嵌入模型,它增强了具有跳跃连接的多层Bi-LSTM,以避免训练错误的积累,每一层的计算如下:
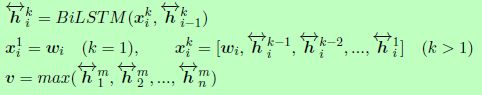
3.3 The PairwiseWord Interaction Model (PWIM)(成对词交互模型(PWIM))
在两两词交互模型中(He and Lin, 2016),每个词向量wi通过前后LSTMs进行上下文编码。对于句子之间的每个词对(wa,wb),该模型直接使用余弦相似性、欧几里德距离和编码层输出上的点积计算词对交互:
![]()
一个“硬”的注意力被应用到交互张量来建立单词对齐:选择最相关的单词对并增加相应的权重10倍。然后使用19层深度的CNN对单词的交互特征进行汇总,最终进行分类。
3.4 The Decomposable Attention Model (DecAtt)(可分解注意力模型(DecAtt))
可分解的注意模型(Parikh et al., 2016)是最早的模型引入基于注意力对齐句子对建模,在不依赖词序的信息的情况下,在SNLI数据集实现了先进的结果,并且比其他模型参数少一个数量级(表5中看到更多)

3.5 The Enhanced Sequential Inference Model (ESIM)(增强的顺序推理模型(ESIM))
增强顺序推理模型(Chen et al., 2017)与DecAtt模型密切相关,但在几个方面有所不同。首先,Chen等人(2017)证明了使用Bi-LSTM对顺序上下文进行编码对于性能改进非常重要。其次,它们展示了递归架构与顺序LSTM互补的选区解析的竞争性能。将DecAtt中的前馈函数G替换为Tree-LSTM:
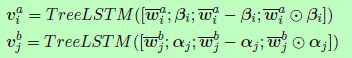
第三,ESIM在经过多层感知器(multi-layer perceptron, MLP)进行分类之前,采用平均池和最大连接v,而不是使用累加求和:
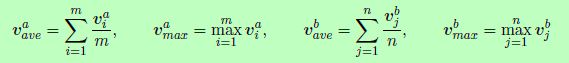
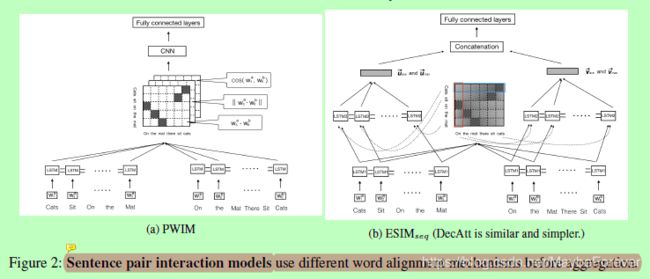
图二:句子对交互模型在聚合之前使用不同的词对齐机制。
四、Experiments and Analysis
4.1 Datasets
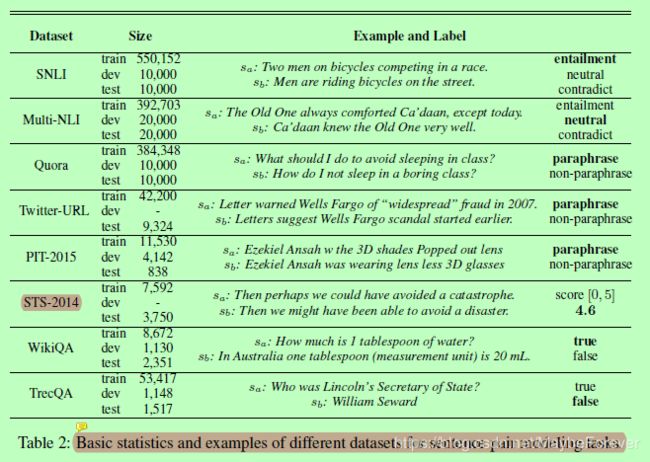
表二:句子对建模任务的基本统计信息和不同数据集的示例。
4.2 Implementation Details
我们使用相同的PyTorch框架实现所有的模型。下面,我们总结了对每个模型重现结果很关键的实现细节:
- SSE
- DecAtt
- ESIM
- PWIM
4.3 Analysis
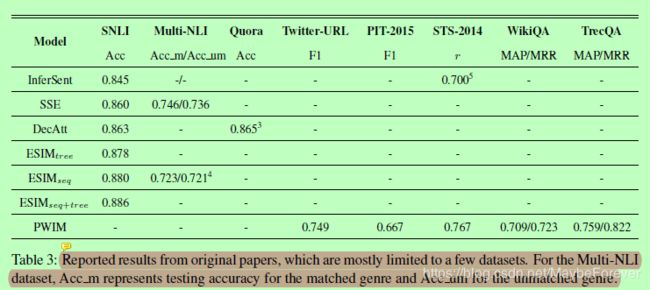
表三:报告的结果来自原始论文,其中大部分是有限的几个数据集。对于Multi-NLI数据集,Acc_m表示匹配类型的测试准确性,Acc_um表示不匹配类型的测试准确性。

表四:我们在PyTorch中的重新实现在多个任务和数据集中复制了结果。每个数据集中的最佳结果用粗体表示,次佳结果用下划线表示。
五、Conclusion
我们分析了五种不同的用于句子对建模的神经模型(及其变体),并针对不同的NLP任务,使用八个代表性数据集进行了一系列的实验。我们量化了LSTM编码器和注意对齐对句子间交互的重要性,以及基于句子编码的模型的转移学习能力。我们发现,超过550k个句子对的SNLI语料库不能满足学习曲线。我们系统地比较了不同网络设计的优缺点,为今后的工作提供了见解。