论文笔记09 Google's Neural Machine Translation System:Bridging the Gap Between Human and ML
Google’s Neural Machine Translation System:Bridging the Gap Between Human and Machine Translation
NMT的缺点
(1)在训练和翻译推理方面都是计算昂贵的。---->论文中解决方法:低精度算法
(2)当输入句子包含罕见词时缺乏稳健性。---->论文中解决方法:将词分成输入和输出的一组有限的公共子词单元(“wordpieces”)。
(3)有时无法翻译源中的所有单词句子。
GNMT
模型结构
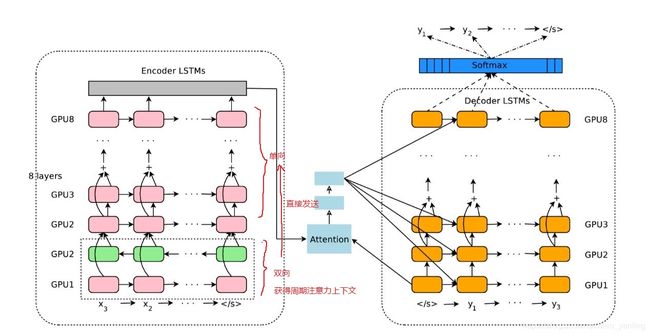
它有三个组件:编码器网络,解码器网络和注意网络。 编码器将源句子变换为矢量列表,每个输入符号一个矢量。 给定这个向量列表,解码器一次产生一个符号,直到产生特殊的句末符号(EOS)。编码器和解码器通过注意模块连接,该注意模块允许解码器在解码过程中聚焦在源句子的不同区域上。
编码器端:
x 1 , x 2 , . . . , x M = E n c o d e r R N N ( x 1 , x 2 , . . . , x M ) \mathrm{x}_1,\mathrm{x}_2,...,\mathrm{x}_M=EncoderRNN(x_1,x_2,...,x_M) x1,x2,...,xM=EncoderRNN(x1,x2,...,xM)
x \mathrm{x} x:向量
解码器端:RNN+softmax:解码器RNN网络产生一个隐藏状态,即下一个要预测的符号,然后通过softmax层产生候选输出符号的概率分布。
在推理期间,计算到目前为止给定源句编码和解码目标序列的下一个符号的概率:
P ( y i ∣ y 0 , y 1 , . . . , y i − 1 , x 1 , x 2 , . . . , x M ) P(y_i|y_0,y_1,...,y_{i-1},\mathrm{x}_1,\mathrm{x}_2,...,\mathrm{x}_M) P(yi∣y0,y1,...,yi−1,x1,x2,...,xM)
则序列的条件概率为:
P ( Y ∣ X ) = P ( Y ∣ x 1 , x 2 , . . . , x M ) P(Y|X)=P(Y|\mathrm{x}_1,\mathrm{x}_2,...,\mathrm{x}_M) P(Y∣X)=P(Y∣x1,x2,...,xM)
= ∏ i = 1 N P ( y i ∣ y 0 , y 1 , . . . , y i − 1 , x 1 , x 2 , . . . , x M ) =\prod^N_{i=1}P(y_i|y_0,y_1,...,y_{i-1},\mathrm{x}_1,\mathrm{x}_2,...,\mathrm{x}_M) =i=1∏NP(yi∣y0,y1,...,yi−1,x1,x2,...,xM)
其中 y 0 y_0 y0是一个特殊的“句子开头”符号,它被添加到每个目标句子之前。
为了使NMT系统达到良好的准确性,编码器和解码器RNN必须足够深,以捕获源语言和目标语言中的细微不规则性。
注意力模块
将来自解码器网络底层的注意力连接到编码器网络的顶层。
s t = A t t e n t i o n F u n c t i o n ( y i − 1 , x t ) s_t=AttentionFunction(y_{i-1},\mathrm{x}_t) st=AttentionFunction(yi−1,xt)
p t = e x p ( s t ) / ∑ t − 1 M e x p ( s t ) p_t=exp(s_t)/\sum^M_{t-1}exp(s_t) pt=exp(st)/t−1∑Mexp(st)
a i = ∑ t − 1 M p t ⋅ x t a_i=\sum^M_{t-1}p_t\cdot{\mathrm{x}_t} ai=t−1∑Mpt⋅xt
其中 y i − 1 y_{i-1} yi−1为解码器RNN在过去的解码时间步骤的输出。
剩余连接
简单地堆叠更多层LSTM仅对一定数量的层起作用,超过该层,网络会变得过于缓慢且难以训练,可能原因是由于爆炸和消失的梯度问题。
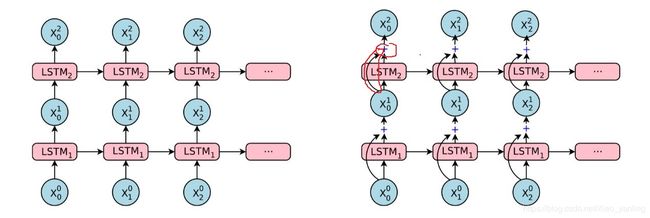
利用上一层的输入与结果相加来使深层网络效果更好。?
c t i , m t i = L S T M i ( c t − 1 i , m t − 1 i , x t i − 1 ; W i ) c_t^i,m_t^i=LSTM_i(c_{t-1}^i,m_{t-1}^i,\mathrm{x}_t^{i-1};W^i) cti,mti=LSTMi(ct−1i,mt−1i,xti−1;Wi)
x t i = m t i + x t i − 1 \mathrm{x}_t^i=m_t^i+x_t^{i-1} xti=mti+xti−1
c t i + 1 , m t i + 1 = L S T M i + 1 ( c t − 1 i + 1 , m t − 1 i + 1 , x t i ; W i ) c_t^{i+1},m_t^{i+1}=LSTM_{i+1}(c_{t-1}^{i+1},m_{t-1}^{i+1},\mathrm{x}_t^{i};W^i) cti+1,mti+1=LSTMi+1(ct−1i+1,mt−1i+1,xti;Wi)
其中 x t i \mathrm{x}^i_t xti是 L S T M i LSTM_i LSTMi在时间步长t的输入,并且 m t i m_t^i mti 和 c t i c_t^i cti分别表示 L S T M i LSTM_i LSTMi 在时间步长t的隐藏状态和存储状态。
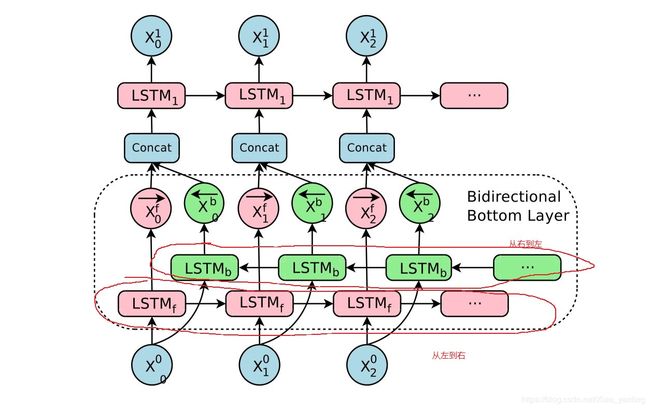
第一层的双向编码器
翻译输出侧某些单词所需的信息可以出现在源侧的任何位置。
双向:从左到右+从右到左
Wordpeice模型?
首先将单词分解为单词片,给出训练有素的单词模型。在训练模型之前添加特殊单词边界符号,使得可以从单词序列中恢复原始单词序列而没有模糊。在解码时,模型首先产生一个字组序列,然后将其转换成相应的字序列。
例:
• Word: Jet makers feud over seat width with big orders at stake
• wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
训练标准
O M L ( θ ) = ∑ i = 1 N l o g P θ ( Y ∗ ( i ) ∣ X i ) O_{ML}(\theta)=\sum^N_{i=1}logP_{\theta}(Y^{*(i)}|X^{i}) OML(θ)=i=1∑NlogPθ(Y∗(i)∣Xi)
此目标不反映任务奖励函数,仅使用最大似然训练,模型将不会学习对解码期间产生的错误的鲁棒性,因为它们从未被观察到,这在训练和测试过程之间是非常不匹配的。
O R L ( θ ) = ∑ i = 1 N ∑ Y ∈ y P θ ( Y ∣ X ( i ) ) r ( Y , Y ∗ ( i ) ) O_{RL}(\theta)=\sum^N_{i=1}\sum_{Y\in{\mathcal{y}}}P_\theta(Y|X^{(i)})r(Y,Y^{*(i)}) ORL(θ)=i=1∑NY∈y∑Pθ(Y∣X(i))r(Y,Y∗(i))
其中, r ( Y , Y ∗ ( i ) ) r(Y,Y^{*(i)}) r(Y,Y∗(i))表示每句话得分。
论文中目标函数为:
O m i x e d ( θ ) = α ∗ O M L ( θ ) + O R L ( θ ) O_{mixed}(\theta)=\alpha*O_{ML}(\theta)+O_{RL}(\theta) Omixed(θ)=α∗OML(θ)+ORL(θ)