pytorch搭建神经网络分类Fashion-MNIST数据集
使用Fashion-MNIST数据集训练神经网络对数据集中的图片进行分类
pytorch: 1.4.0
Fashion-MNIST 是一个替代原始的MNIST手写数字数据集的另一个图像数据集。 它是由Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自10种类别的共7万个不同商品的正面图片(口红、包包、鞋子、裤子、衬衫、T恤、衬衣、靴子)。
Fashion-MNIST的大小、格式和训练集/测试集划分与原始的MNIST完全一致。60000/10000的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码
下载Fasion-MNIST数据集,显示图片
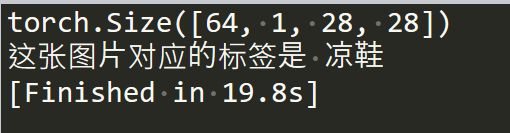
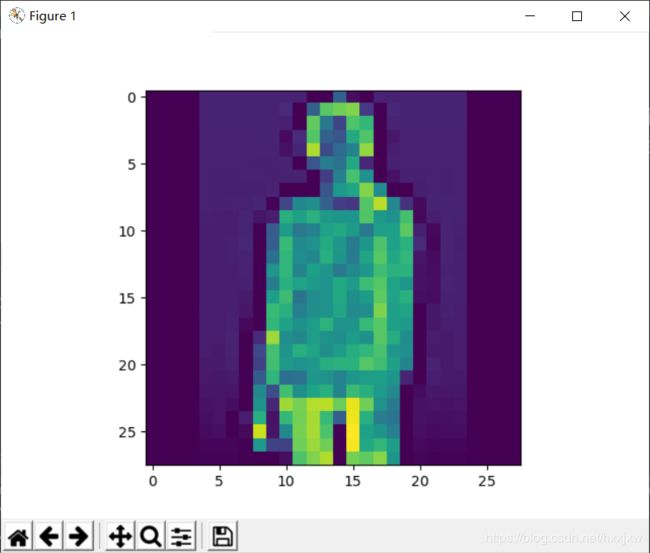
import torch # 导入pytorch from torch import nn, optim # 导入神经网络与优化器对应的类 import torch.nn.functional as F from torchvision import datasets, transforms ## 导入数据集与数据预处理的方法 import matplotlib.pyplot as plt # 数据预处理:标准化图像数据,使得灰度数据在-1到+1之间 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]) #1、下载Fasion-MNIST数据集 # 下载Fashion-MNIST训练集数据,并构建训练集数据载入器trainloader,每次从训练集中载入64张图片,每次载入都打乱顺序 trainset = datasets.FashionMNIST('dataset/', download=True, train=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # 下载Fashion-MNIST测试集数据,并构建测试集数据载入器trainloader,每次从测试集中载入64张图片,每次载入都打乱顺序 testset = datasets.FashionMNIST('dataset/', download=True, train=False, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True) #2、打开数据集中的图片 image, label = next(iter(trainloader)) print(image.shape) #image包含了64张28 * 28的灰度图片,1代表单通道,也就是灰度 #我们查看索引为2的图片 imagedemo = image[3] imagedemolabel = label[3] imagedemo = imagedemo.reshape((28,28)) plt.imshow(imagedemo) plt.show() labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] print(f'这张图片对应的标签是 {labellist[imagedemolabel]}')
image包含了64张28 * 28的灰度图片,1代表单通道,也就是灰度
label包含了image里面64张图片对应的标签
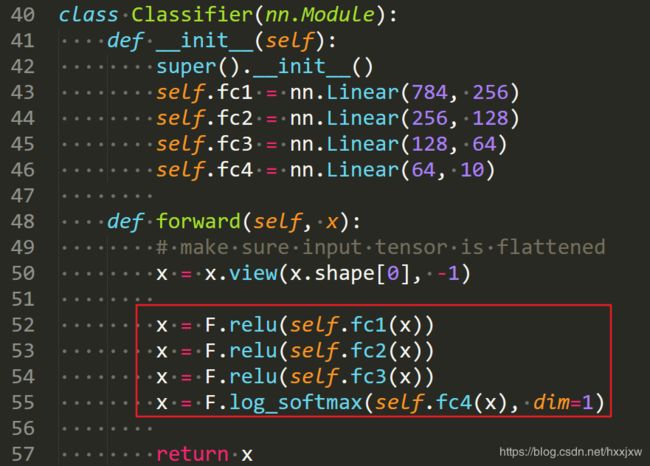
搭建并训练四层全连接神经网络
神经网络的输入为28 * 28 = 784 个像素
第一个隐含层包含256个神经元
第二个隐含层包含128个神经元
第三个隐含层包含64个神经元
输出层输出10个结果,对应图片的10种分类
输出10个分类结果,就对应着刚才10种image的标签
相加多少个隐含层,每一层还有多少个神经元,我们都是可以自己调的
通过pytorch的接口,非常简单
最后通过softmax函数来进行十个种类的分类
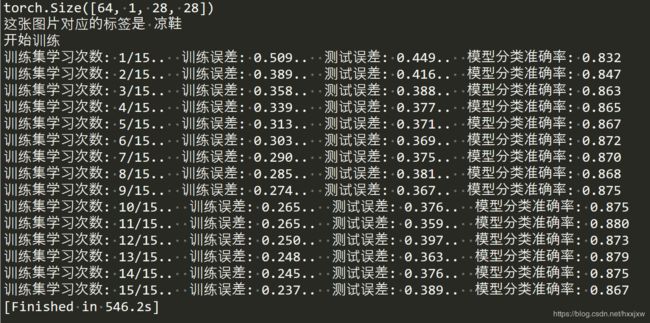
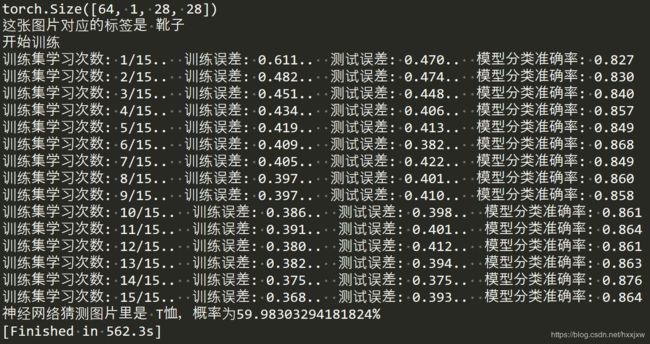
import torch # 导入pytorch from torch import nn, optim # 导入神经网络与优化器对应的类 import torch.nn.functional as F from torchvision import datasets, transforms ## 导入数据集与数据预处理的方法 import matplotlib.pyplot as plt # 数据预处理:标准化图像数据,使得灰度数据在-1到+1之间 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]) #------------------1、下载Fasion-MNIST数据集-------------------------------- # 下载Fashion-MNIST训练集数据,并构建训练集数据载入器trainloader,每次从训练集中载入64张图片,每次载入都打乱顺序 trainset = datasets.FashionMNIST('dataset/', download=True, train=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # 下载Fashion-MNIST测试集数据,并构建测试集数据载入器trainloader,每次从测试集中载入64张图片,每次载入都打乱顺序 testset = datasets.FashionMNIST('dataset/', download=True, train=False, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True) #----------------------------2、打开数据集中的图片--------------------------------- image, label = next(iter(trainloader)) print(image.shape) #image包含了64张28 * 28的灰度图片,1代表单通道,也就是灰度 #我们查看索引为2的图片 imagedemo = image[3] imagedemolabel = label[3] imagedemo = imagedemo.reshape((28,28)) plt.imshow(imagedemo) plt.show() labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] print(f'这张图片对应的标签是 {labellist[imagedemolabel]}') #------------------3、搭建并训练四层全连接神经网络--------------------------------- class Classifier(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, 64) self.fc4 = nn.Linear(64, 10) def forward(self, x): # make sure input tensor is flattened x = x.view(x.shape[0], -1) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = F.relu(self.fc3(x)) x = F.log_softmax(self.fc4(x), dim=1) return x # 对上面定义的Classifier类进行实例化 model = Classifier() # 定义损失函数为负对数损失函数 criterion = nn.NLLLoss() # 优化方法为Adam梯度下降方法,学习率为0.003 optimizer = optim.Adam(model.parameters(), lr=0.003) # 对训练集的全部数据学习15遍,这个数字越大,训练时间越长 epochs = 15 # 将每次训练的训练误差和测试误差存储在这两个列表里,后面绘制误差变化折线图用 train_losses, test_losses = [], [] print('开始训练') for e in range(epochs): running_loss = 0 # 对训练集中的所有图片都过一遍 for images, labels in trainloader: # 将优化器中的求导结果都设为0,否则会在每次反向传播之后叠加之前的 optimizer.zero_grad() # 对64张图片进行推断,计算损失函数,反向传播优化权重,将损失求和 log_ps = model(images) loss = criterion(log_ps, labels) loss.backward() optimizer.step() running_loss += loss.item() # 每次学完一遍数据集,都进行以下测试操作 else: test_loss = 0 accuracy = 0 # 测试的时候不需要开自动求导和反向传播 with torch.no_grad(): # 关闭Dropout model.eval() # 对测试集中的所有图片都过一遍 for images, labels in testloader: # 对传入的测试集图片进行正向推断、计算损失,accuracy为测试集一万张图片中模型预测正确率 log_ps = model(images) test_loss += criterion(log_ps, labels) ps = torch.exp(log_ps) top_p, top_class = ps.topk(1, dim=1) equals = top_class == labels.view(*top_class.shape) # 等号右边为每一批64张测试图片中预测正确的占比 accuracy += torch.mean(equals.type(torch.FloatTensor)) # 恢复Dropout model.train() # 将训练误差和测试误差存在两个列表里,后面绘制误差变化折线图用 train_losses.append(running_loss/len(trainloader)) test_losses.append(test_loss/len(testloader)) print("训练集学习次数: {}/{}.. ".format(e+1, epochs), "训练误差: {:.3f}.. ".format(running_loss/len(trainloader)), "测试误差: {:.3f}.. ".format(test_loss/len(testloader)), "模型分类准确率: {:.3f}".format(accuracy/len(testloader)))
验证模型效果
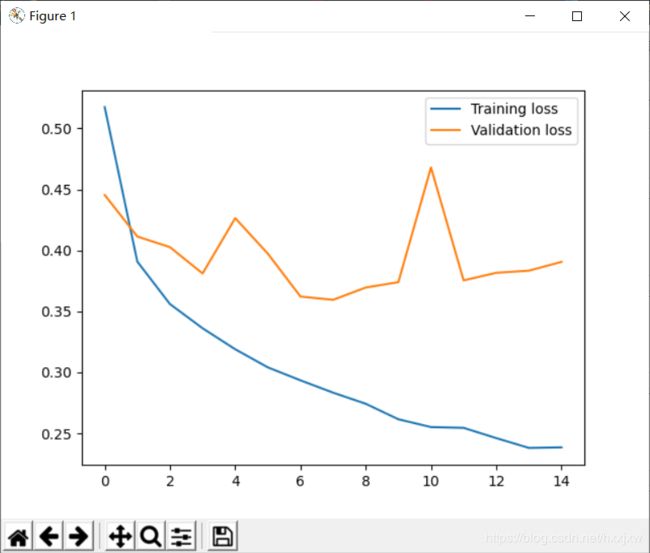
import torch # 导入pytorch from torch import nn, optim # 导入神经网络与优化器对应的类 import torch.nn.functional as F from torchvision import datasets, transforms ## 导入数据集与数据预处理的方法 import matplotlib.pyplot as plt # 数据预处理:标准化图像数据,使得灰度数据在-1到+1之间 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]) #------------------1、下载Fasion-MNIST数据集-------------------------------- # 下载Fashion-MNIST训练集数据,并构建训练集数据载入器trainloader,每次从训练集中载入64张图片,每次载入都打乱顺序 trainset = datasets.FashionMNIST('dataset/', download=True, train=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # 下载Fashion-MNIST测试集数据,并构建测试集数据载入器trainloader,每次从测试集中载入64张图片,每次载入都打乱顺序 testset = datasets.FashionMNIST('dataset/', download=True, train=False, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True) #----------------------------2、打开数据集中的图片--------------------------------- image, label = next(iter(trainloader)) print(image.shape) #image包含了64张28 * 28的灰度图片,1代表单通道,也就是灰度 #我们查看索引为2的图片 imagedemo = image[3] imagedemolabel = label[3] imagedemo = imagedemo.reshape((28,28)) plt.imshow(imagedemo) plt.show() labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] print(f'这张图片对应的标签是 {labellist[imagedemolabel]}') #------------------3、搭建并训练四层全连接神经网络--------------------------------- class Classifier(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, 64) self.fc4 = nn.Linear(64, 10) def forward(self, x): # make sure input tensor is flattened x = x.view(x.shape[0], -1) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = F.relu(self.fc3(x)) x = F.log_softmax(self.fc4(x), dim=1) return x # 对上面定义的Classifier类进行实例化 model = Classifier() # 定义损失函数为负对数损失函数 criterion = nn.NLLLoss() # 优化方法为Adam梯度下降方法,学习率为0.003 optimizer = optim.Adam(model.parameters(), lr=0.003) # 对训练集的全部数据学习15遍,这个数字越大,训练时间越长 epochs = 15 # 将每次训练的训练误差和测试误差存储在这两个列表里,后面绘制误差变化折线图用 train_losses, test_losses = [], [] print('开始训练') for e in range(epochs): running_loss = 0 # 对训练集中的所有图片都过一遍 for images, labels in trainloader: # 将优化器中的求导结果都设为0,否则会在每次反向传播之后叠加之前的 optimizer.zero_grad() # 对64张图片进行推断,计算损失函数,反向传播优化权重,将损失求和 log_ps = model(images) loss = criterion(log_ps, labels) loss.backward() optimizer.step() running_loss += loss.item() # 每次学完一遍数据集,都进行以下测试操作 else: test_loss = 0 accuracy = 0 # 测试的时候不需要开自动求导和反向传播 with torch.no_grad(): # 关闭Dropout model.eval() # 对测试集中的所有图片都过一遍 for images, labels in testloader: # 对传入的测试集图片进行正向推断、计算损失,accuracy为测试集一万张图片中模型预测正确率 log_ps = model(images) test_loss += criterion(log_ps, labels) ps = torch.exp(log_ps) top_p, top_class = ps.topk(1, dim=1) equals = top_class == labels.view(*top_class.shape) # 等号右边为每一批64张测试图片中预测正确的占比 accuracy += torch.mean(equals.type(torch.FloatTensor)) # 恢复Dropout model.train() # 将训练误差和测试误差存在两个列表里,后面绘制误差变化折线图用 train_losses.append(running_loss/len(trainloader)) test_losses.append(test_loss/len(testloader)) print("训练集学习次数: {}/{}.. ".format(e+1, epochs), "训练误差: {:.3f}.. ".format(running_loss/len(trainloader)), "测试误差: {:.3f}.. ".format(test_loss/len(testloader)), "模型分类准确率: {:.3f}".format(accuracy/len(testloader))) #绘制训练误差和测试误差随学习次数增加的变化图 plt.plot(train_losses, label='Training loss') plt.plot(test_losses, label='Validation loss') plt.legend() plt.show() dataiter = iter(testloader) images, labels = dataiter.next() img = images[0] img = img.reshape((28,28)).numpy() plt.imshow(img) # 将测试图片转为一维的列向量 img = torch.from_numpy(img) img = img.view(1, 784) # 进行正向推断,预测图片所在的类别 with torch.no_grad(): output = model.forward(img) ps = torch.exp(output) top_p, top_class = ps.topk(1, dim=1) labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] prediction = labellist[top_class] probability = float(top_p) print(f'神经网络猜测图片里是 {prediction},概率为{probability*100}%')可以看到,虽然训练误差一直在下降,但测试误差居高不下,这就出现了过拟合现象,我们的神经网络仿佛一个高分低能的同学,平时把所有课后题答案都死记硬背下来,一到考试见到新题的时候就不会做了。
虽然高分低能,但大部分时候依旧能做出正确判断,但是有时候预测概率只有百分之三四十的把握,不能做到十有八九的确定
采用Dropout方法防止过拟合
我们可以采用Dropout的方法,也就是在每次正向推断训练神经元的时候随机“掐死”一部分神经元,阻断其输入输出,这样可以起到正则化的作用。
可以理解为,皇上雨露均沾,今天受宠,明天可能就被打入冷宫,这样就防止了杨贵妃那样的“三千宠爱在一身”,从而防止了某些神经元一家独大,成为话题领袖,只手遮天。
所有神经元处于平等地位,防止过拟合
修改代码
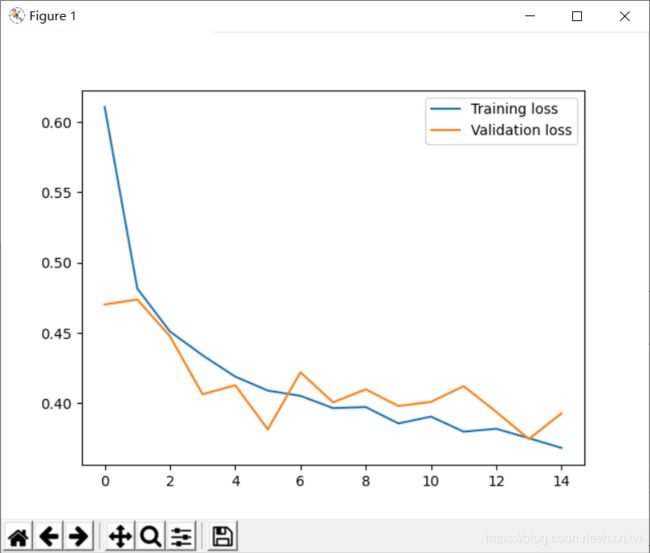
import torch # 导入pytorch from torch import nn, optim # 导入神经网络与优化器对应的类 import torch.nn.functional as F from torchvision import datasets, transforms ## 导入数据集与数据预处理的方法 import matplotlib.pyplot as plt # 数据预处理:标准化图像数据,使得灰度数据在-1到+1之间 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]) #------------------1、下载Fasion-MNIST数据集-------------------------------- # 下载Fashion-MNIST训练集数据,并构建训练集数据载入器trainloader,每次从训练集中载入64张图片,每次载入都打乱顺序 trainset = datasets.FashionMNIST('dataset/', download=True, train=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # 下载Fashion-MNIST测试集数据,并构建测试集数据载入器trainloader,每次从测试集中载入64张图片,每次载入都打乱顺序 testset = datasets.FashionMNIST('dataset/', download=True, train=False, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True) #----------------------------2、打开数据集中的图片--------------------------------- image, label = next(iter(trainloader)) print(image.shape) #image包含了64张28 * 28的灰度图片,1代表单通道,也就是灰度 #我们查看索引为2的图片 imagedemo = image[3] imagedemolabel = label[3] imagedemo = imagedemo.reshape((28,28)) plt.imshow(imagedemo) plt.show() labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] print(f'这张图片对应的标签是 {labellist[imagedemolabel]}') #------------------3、搭建并训练四层全连接神经网络--------------------------------- class Classifier(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, 64) self.fc4 = nn.Linear(64, 10) # 构造Dropout方法,在每次训练过程中都随机“掐死”百分之二十的神经元,防止过拟合。 self.dropout = nn.Dropout(p=0.2) def forward(self, x): # 确保输入的tensor是展开的单列数据,把每张图片的通道、长度、宽度三个维度都压缩为一列 x = x.view(x.shape[0], -1) # 在训练过程中对隐含层神经元的正向推断使用Dropout方法 x = self.dropout(F.relu(self.fc1(x))) x = self.dropout(F.relu(self.fc2(x))) x = self.dropout(F.relu(self.fc3(x))) # 在输出单元不需要使用Dropout方法 x = F.log_softmax(self.fc4(x), dim=1) return x # 对上面定义的Classifier类进行实例化 model = Classifier() # 定义损失函数为负对数损失函数 criterion = nn.NLLLoss() # 优化方法为Adam梯度下降方法,学习率为0.003 optimizer = optim.Adam(model.parameters(), lr=0.003) # 对训练集的全部数据学习15遍,这个数字越大,训练时间越长 epochs = 15 # 将每次训练的训练误差和测试误差存储在这两个列表里,后面绘制误差变化折线图用 train_losses, test_losses = [], [] print('开始训练') for e in range(epochs): running_loss = 0 # 对训练集中的所有图片都过一遍 for images, labels in trainloader: # 将优化器中的求导结果都设为0,否则会在每次反向传播之后叠加之前的 optimizer.zero_grad() # 对64张图片进行推断,计算损失函数,反向传播优化权重,将损失求和 log_ps = model(images) loss = criterion(log_ps, labels) loss.backward() optimizer.step() running_loss += loss.item() # 每次学完一遍数据集,都进行以下测试操作 else: test_loss = 0 accuracy = 0 # 测试的时候不需要开自动求导和反向传播 with torch.no_grad(): # 关闭Dropout model.eval() # 对测试集中的所有图片都过一遍 for images, labels in testloader: # 对传入的测试集图片进行正向推断、计算损失,accuracy为测试集一万张图片中模型预测正确率 log_ps = model(images) test_loss += criterion(log_ps, labels) ps = torch.exp(log_ps) top_p, top_class = ps.topk(1, dim=1) equals = top_class == labels.view(*top_class.shape) # 等号右边为每一批64张测试图片中预测正确的占比 accuracy += torch.mean(equals.type(torch.FloatTensor)) # 恢复Dropout model.train() # 将训练误差和测试误差存在两个列表里,后面绘制误差变化折线图用 train_losses.append(running_loss/len(trainloader)) test_losses.append(test_loss/len(testloader)) print("训练集学习次数: {}/{}.. ".format(e+1, epochs), "训练误差: {:.3f}.. ".format(running_loss/len(trainloader)), "测试误差: {:.3f}.. ".format(test_loss/len(testloader)), "模型分类准确率: {:.3f}".format(accuracy/len(testloader))) #绘制训练误差和测试误差随学习次数增加的变化图 plt.plot(train_losses, label='Training loss') plt.plot(test_losses, label='Validation loss') plt.legend() plt.show() model.eval() #不启用 Dropout dataiter = iter(testloader) images, labels = dataiter.next() img = images[0] img = img.reshape((28,28)).numpy() plt.imshow(img) plt.show() # 将测试图片转为一维的列向量 img = torch.from_numpy(img) img = img.view(1, 784) # 进行正向推断,预测图片所在的类别 with torch.no_grad(): output = model.forward(img) ps = torch.exp(output) top_p, top_class = ps.topk(1, dim=1) labellist = ['T恤','裤子','套衫','裙子','外套','凉鞋','汗衫','运动鞋','包包','靴子'] prediction = labellist[top_class] probability = float(top_p) print(f'神经网络猜测图片里是 {prediction},概率为{probability*100}%')
可以看到,训练误差和测试误差都随学习次数增加逐渐降低,没有出现“高分低能”和“死记硬背”的过拟合现象,这其实是Dropout正则化的功劳。
至于为什么刚才没加dropout优化过拟合是90%多,现在才是60%
那应该是碰巧了,刚才碰巧遇见一个好识别的,这次是一个不好识别的


参考:
https://www.bilibili.com/video/BV1w4411u7ay