Mapreduce二次排序实例
Mapreduce可以简单的分为三个阶段:map阶段、shuffle阶段、reduce阶段。shuffle阶段包括分区、排序、分组三个步骤。
)。
实例:有一张phone表,包含mac、time两个字段,对mac、time进行排序(order by mac,time)。
分区:通过分区函数将满足条件的分在同一个区(相同key值)。
排序:分区后同一个区的数据然后再排序(二次排序)。排序是对key进行操作。
分组:将同一个区内相同key值的value整合成一个集合(实例:有一张phone表,包含mac、time两个字段,对mac、time进行排序(order by mac,time)。
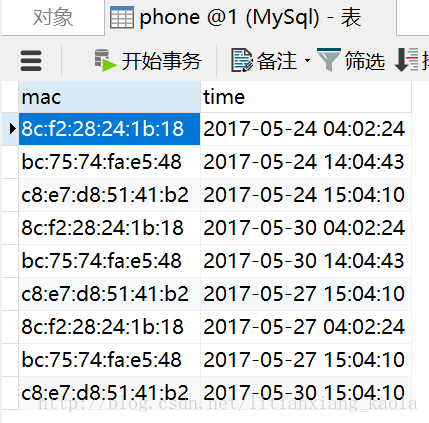
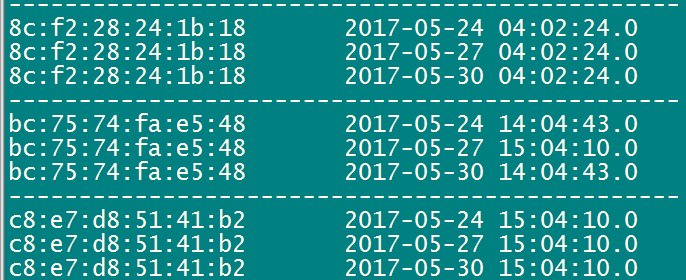
思路:在分区阶段,通过分区函数将相同mac的数据分在同一个区,然后同一个区里的数据根据time排序。
/**
* 自定义分区函数类
*/
public static class FirstPartitioner extends Partitioner{
@Override
public int getPartition(PhonePair key, Text value, int numPartitions) {
return Math.abs(key.getMac().hashCode() * 127) % numPartitions;
}
} /**
* 经过分区函数类分区后,同分区内的数据根据compareTo方法排序
*/
@Override
public int compareTo(PhonePair o) {
if(!mac.equals(o.mac)){
return mac.compareTo(o.mac) < 0 ? -1 : 1;
}else if(time.getTime() != o.time.getTime()){
return time.getTime() < o.time.getTime() ? -1 : 1;
}else{
return 0;
}
}代码:
public class SecondarySort {
/**
*自定义key类
*/
public static class PhonePair implements WritableComparable{
private String mac;
private Timestamp time;
public void set(String mac, Timestamp time){
this.mac = mac;
this.time = time;
}
public String getMac() {
return mac;
}
public void setMac(String mac) {
this.mac = mac;
}
public Timestamp getTime() {
return time;
}
public void setTime(Timestamp time) {
this.time = time;
}
/*
* 反序列化方法:从数据字节流中逐个恢复出各个字段
*/
@Override
public void readFields(DataInput in) throws IOException {
this.mac = in.readUTF();
this.time = Timestamp.valueOf(in.readUTF());
}
/*
* 序列化方法:将我们要传输的数据序列转化成字节流
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(mac);
out.writeUTF(time.toString());
}
/**
* 经过分区函数类分区后,同分区内的数据根据compareTo方法排序
*/
@Override
public int compareTo(PhonePair o) {
if(!mac.equals(o.mac)){
return mac.compareTo(o.mac) < 0 ? -1 : 1;
}else if(time.getTime() != o.time.getTime()){
return time.getTime() < o.time.getTime() ? -1 : 1;
}else{
return 0;
}
}
/**
* 重写hashCode和equals方法
*/
@Override
public int hashCode() {
return mac.hashCode() * 157 + time.hashCode();
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if(obj instanceof PhonePair){
PhonePair o = (PhonePair) obj;
return mac.equals(o.mac) && time.getTime() == o.time.getTime();
}else{
return false;
}
}
}
/**
* 自定义分区函数类
*/
public static class FirstPartitioner extends Partitioner{
@Override
public int getPartition(PhonePair key, Text value, int numPartitions) {
return Math.abs(key.getMac().hashCode() * 127) % numPartitions;
}
}
/**
* 自定义分组函数类
*/
public static class GroupingComparator extends WritableComparator{
protected GroupingComparator() {
super(PhonePair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
PhonePair p1 = (PhonePair) w1;
PhonePair p2 = (PhonePair) w2;
String mac1 = p1.getMac();
String mac2 = p2.getMac();
return mac1.equals(mac2) ? 0 : (mac1.compareTo(mac2) < 0 ? -1 : 1);
}
}
/**
* 自定义map
*/
public static class Map extends Mapper{
private final PhonePair phone = new PhonePair();
private final Text text = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] split = line.split("\t");
phone.setMac(split[0]);
phone.set(split[0], Timestamp.valueOf(split[1]));
text.set(split[1]);
//传递[ , time]
context.write(phone, text);
}
}
/**
* 自定义reduce
*/
public static class Reduce extends Reducer {
private final Text text = new Text();
private static final Text SEPARATOR = new Text("------------------------------------------------");
public void reduce(PhonePair key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(SEPARATOR, null);
text.set(key.getMac());
for (Text value : values) {
//传递[mac , time]
context.write(text, value);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//实例化一道作业
Job job = Job.getInstance(new Configuration());
job.setJarByClass(SecondarySort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置分区函数
job.setPartitionerClass(FirstPartitioner.class);
//设置分组函数
job.setGroupingComparatorClass(GroupingComparator.class);
job.setMapOutputKeyClass(PhonePair.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}