Window环境下运行YOLO v4目标检测算法
YOLO v4是一种最新提出的目标检测算法,由Alexey Bochkovskiy提出,性能较原有算法基础上有较大幅度提高。
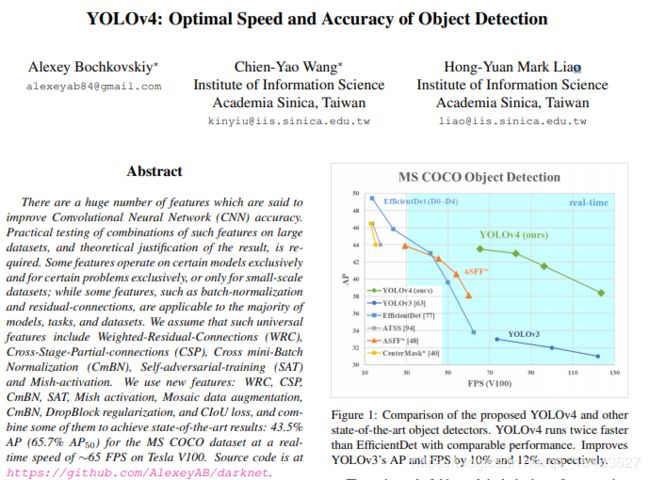
- 论文地址:https://arxiv.org/abs/2004.10934
- GitHub源码地址:https://github.com/AlexeyAB/darknet
- 运行环境:WIn7+CUDA10.0+Python3.6+VS2015(社区版)
作者提供了三种编译方式,我们选择第三种,同时也是YOLO v3和YOLO v2等使用的传统方式。
首先确定你的CUDA10已经正确安装,在cmd中运行:
nvcc -V如果正确显示,进行接下来的步骤。

下载Opencv3.4,地址https://opencv.org/opencv-3-4.html,需要注意的是这不是Python-OpenCV。把以下路径加入到环境变量path中(需要修改为你自己安装的路径)

D:\Program Files\opencv\build\x64\vc14\bin
D:\Program Files\opencv\build\include\opencv2
D:\Program Files\opencv\build\include\opencv去GitHub上下载原代码 https://github.com/AlexeyAB/darknet,文件组织如下所示

进入OpenCV安装目录 D:\Program Files\opencv\build\x64\vc14\bin下(需要修改为你自己安装的路径),复制opencv_ffmpeg340_64.dll和opencv_world340.dll到build\darknet\x64文件夹下。使用visual studio2015打开darknet.sln,最上面的两个值修改为Release和x64
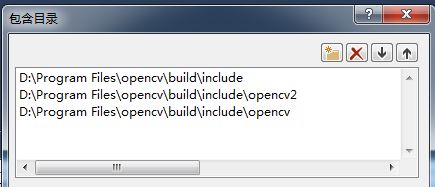
然后在项目darknet上点开属性,修改包含目录、库目录和附加依赖项
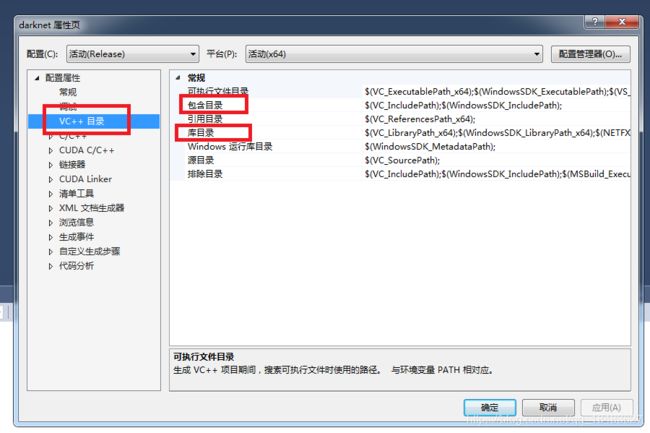
其中包含目录修改为:
库目录修改为:

附加依赖项修改为:

点击生成或重新生成,会经过漫长的等待,不出意外的话会编译成功
 编译成功后,在F:\code\YOLO\darknet\build\darknet\x64文件夹下会出现一个名为darknet.exe的可执行程序,至此已经成功90%了~
编译成功后,在F:\code\YOLO\darknet\build\darknet\x64文件夹下会出现一个名为darknet.exe的可执行程序,至此已经成功90%了~

使用MS COCO训练好的模型进行检测
下载已经训练好的权重文件yolov4.weights,地址:yolov4.weights(可能会比较慢,博客最后提供这个文件)
在darknet.exe文件夹下新建一个名为weights的文件夹,用于存放权重文件,然后将yolov4.weights复制进去。在darknet.exe所在的文件夹下打开命令行(其中dog.jpg可以换成自己的图片),输入:
darknet.exe detector test cfg\coco.data cfg\yolov4.cfg .\weights\yolov4.weights .\data\dog.jpg
结果如图所示:


另外提供一下YOLO v3的版本,下载权重文件 yolov3.weights 到 weights文件夹下,同样可以生产目标检测结果。
darknet.exe detector test data\coco.data yolov3.cfg .\weights\yolov3.weights .\data\dog.jpg
使用自己的模型训练YOLO v4

(上图标签是我自己加的,好像颠倒了,懒得改了,无视掉吧~)
所用数据集为口罩检测数据集,包括两类:普通人脸+戴口罩的人脸(博客最后提供图像+标签文档)
(1)下载预训练文件 yolov4.conv.137,放到build\darknet\x64文件夹下
(2)在darknet\build\darknet\x64\cfg文件夹下有一个名为yolov4-custom.cfg的文件,复制一份并改名为yolo-obj.cfg,复制到build\darknet\x64下。对其内容进行修改,修改规则如下:
batch=64
subdivisions=64 显存不足时,需要调高
max_batches 一般可以设置为classes*2000,但是不要低于4000, 比如如果你有三个类,那么设置 max_batches=6000
steps 两个值,一般为80%和90%的max_batches
width和height 必须能够整除32,比如416
classes 自己数据集类别的个数,在三个yolo层,共计三处
filters 修改为(classes+5)×3,在每个yolo layer前的卷积层,共计三处例如,本实验中有两类,则max_batches=4000,steps=3200和3600,filters 改为(2+5)x3=21


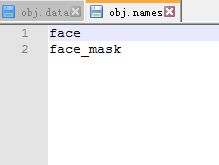
(3)在build\darknet\x64\data\创建文件 obj.names , 每行一个类别的名称(可以参考已存在的openimages.names等)
(4)在build\darknet\x64\data\ 创建obj.data,(可以参考voc.data)

(5)将你自己的图片数据放在 build\darknet\x64\data\obj\文件夹下(obj需要自己创建)

里面的图像应该是这种成对的图像+txt标签,可以通过这个软件进行生成https://github.com/AlexeyAB/Yolo_mark
如果你有了xml标签,想要获得txt标签,可以参考训练YOLO v4模型时,xml格式转txt格式(博客最后提供了实验的txt标签)

(6)创建两个txt文件,其中train.txt表示训练集,test.txt表示验证集
build\darknet\x64\data\train.txt
build\darknet\x64\data\test.txt
两个txt文件内容应该如下,其中img1.jpg等表示的是在build\darknet\x64\data\obj\下图片
data/obj/img1.jpg
data/obj/img2.jpg
data/obj/img3.jpg
...手动复制太麻烦,我写了一个脚本,其中路径需要根据实际修改,训练集和验证集比例可以自己去调整
import os;
import random
def listname(path,trainpath,testpath):
filelist = os.listdir(path);
filelist.sort()
f1 = open(trainpath, 'w');
f2 = open(testpath, 'w');
for files in filelist:
Olddir = os.path.join(path, files);
if os.path.isdir(Olddir):
continue;
if "xml" not in str(files):
if random.randint(0,9)>2: #2表示一个比例,可以修改
f1.write("data/obj/"+files);
f1.write('\n');
else:
f2.write("data/obj/"+files);
f2.write('\n');
f1.close();
f2.close();
savepath="F:/code/YOLO/darknet/build/darknet/x64/data/" #修改为自己的
trainpath = savepath+"/train.txt"
testpath = savepath+"/test.txt"
listname(savepath + "/obj",trainpath,testpath)
print ("Txt have been created!")
(7)开始训练,输入
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137
我的显卡是RTX2070,运行时提示显存不足,可以适当减少batch参数或者增加subdivisions参数。生成的模型在build\darknet\x64\backup文件夹下
运行一晚上,结果如下
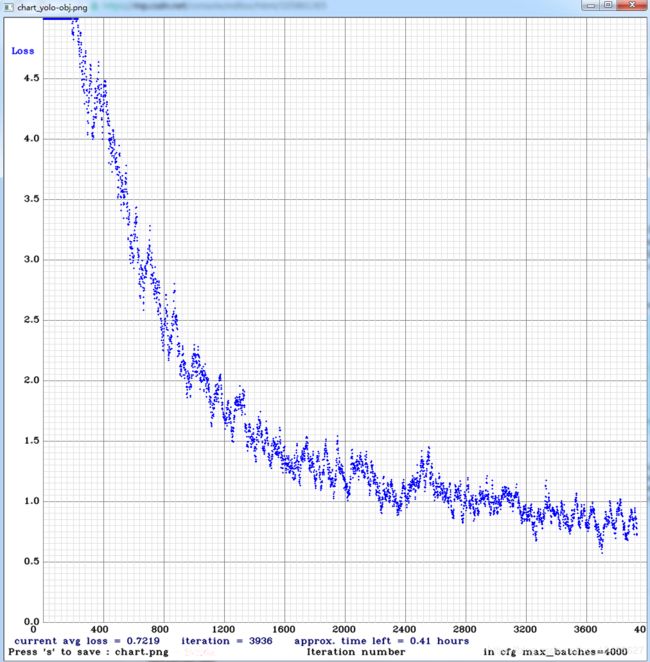


(8)进行测试,输入
darknet.exe detector test data\obj.data yolo-obj.cfg backup\yolo-obj_4000.weights .\data\mask.jpg
并把命令中mask.jpg和yolo-obj_4000.weights 修改为你自己的数值
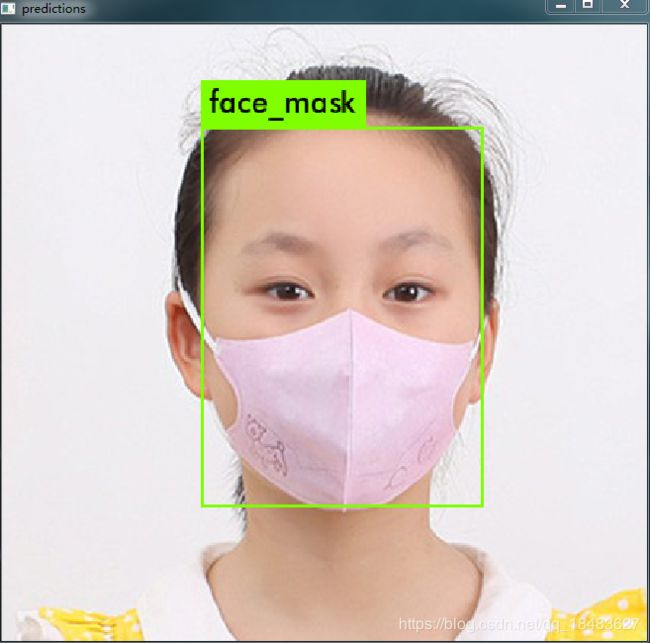
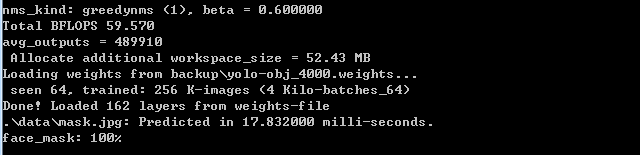
实验用到的数据

实验用到的需要下载的在https://download.csdn.net/download/qq_18483627/12378975