前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Python进阶者
现在在疫情阶段,想找一份不错的工作变得更为困难,很多人会选择去网上看招聘信息。可是招聘信息有一些是错综复杂的。而且不能把全部的信息全部罗列出来,以外卖的58招聘网站来看,资料整理的不清晰。
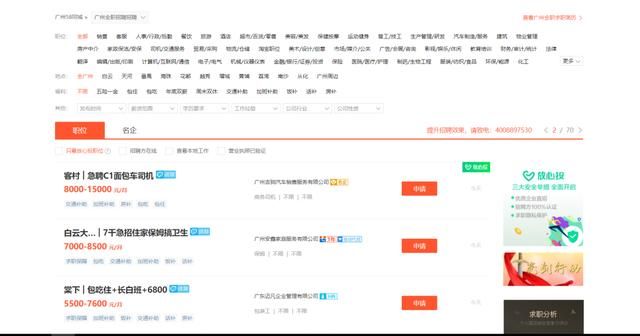
项目目标
获取招聘信息,并批量把地点、 公司名、工资 、下载保存在txt文档。
项目准备
软件:PyCharm
需要的库:requests、lxml、fake_useragent
网站如下:
https://gz.58.com/job/pn2/?param7503=1&from=yjz2_zhaopin&PGTID=0d302408-0000-3efd-48f6-ff64d26b4b1c&ClickID={}点击下一页时,ClickID={}每增加一页自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
反爬措施
该网站上的反爬主要有两点:
1、 直接使用requests库,在不设置任何header的情况下,网站直接不返回数据
2、同一个ip连续访问多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
1、获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2、使用 fake_useragent ,产生随机的UserAgent进行访问。
项目实现
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,代码如下所示。
import requests
from lxml import etree
from fake_useragent import UserAgent
class Zhaopin(object):
def __init__(self):
self.url = "https://gz.58.com/job/pn2/?param7503=1&from=yjz2_zhaopin&PGTID=0d302408-0000-3efd-48f6-ff64d26b4b1c&ClickID={}" # /zhuanchang/:搜索的名字的拼音缩写
def main(self):
pass
if __name__ == '__main__':
Spider = Zhaopin()
Spider.main()
2、随机产生UserAgent。
for l in one:
o = l.xpath('.//a/span[1]/text()')[0].strip()
t = l.xpath('.//a//span[@class="name"]/text()')[0].strip()
f = l.xpath('.//p[@class="job_salary"]/text()')
thr = l.xpath('.//div[@class="comp_name"]//a/text()')[0].strip()
for e in f:
boss = '''
%s:||%s:
公司:%s,
工资:%s元/月
=========================================================
''' % (o, t, thr, e)
print(str(boss)
3、发送请求,获取响应, 页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、xpath解析找到对应的父节点。
def page_page(self, html):
parse_html = etree.HTML(html)
one = parse_html.xpath('//div[@class="main clearfix"]//div[@class="leftCon"]/ul/li')5、for遍历,定义一个变量food_info保存,获取到二级页面对应的菜 名、 原料 、下载链接。
for l in one:
o = l.xpath('.//a/span[1]/text()')[0].strip()
t = l.xpath('.//a//span[@class="name"]/text()')[0].strip()
f = l.xpath('.//p[@class="job_salary"]/text()')
thr = l.xpath('.//div[@class="comp_name"]//a/text()')[0].strip()
for e in f:
boss = '''
%s:||%s:
公司:%s,
工资:%s元/月
=========================================================
''' % (o, t, thr, e)
print(str(boss)6、将结果保存在txt文档中,如下所示。
f = open('g.txt', 'a', encoding='utf-8') # 以'w'方式打开文件
f.write(str(boss))
# print(house_dict)
f.write("\n") # 键和值分行放,键在单数行,值在双数行
f.close()7、调用方法,实现功能。
html = self.get_page(url)
self.page_page(html)
效果展示
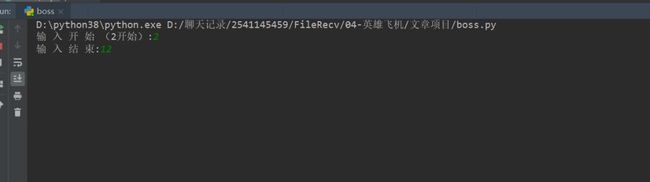
1、点击绿色小三角运行输入起始页,终止页。
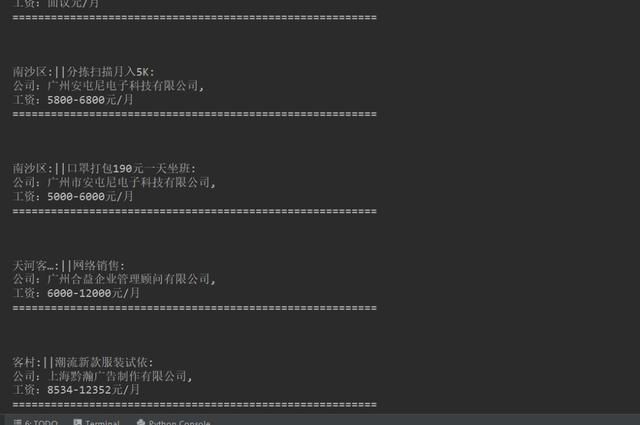
2、运行程序后,结果显示在控制台,如下图所示。
3、保存txt文档到本地,如下图所示。
4、双击文件,内容如下图所示。
