使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬虫中的登陆、验证码、异步加载等复杂问题。

Web Scraper 官网中的简介:
Web Scraper Extension (Free!)
Using our extension you can create a plan (sitemap) how a web site should be traversed and what should be extracted. Using these sitemaps the Web Scraper will navigate the site accordingly and extract all data. Scraped data later can be exported as CSV.
先看一下,我用 web scaper 爬取到的数据:
1. 知乎轮子哥粉丝
轮子哥有 54 万多粉丝,我只抓取了前 20 页400条记录


2.七日热门数据



Web Scraper 抓取流程及要点:
安装Web Scraper插件后,三步完成爬取操作
1、Create new sitemap(创建爬取项目)
2、选取爬取网页中的内容,点点点,操作
3、开启爬取,下载CSV数据
其中最关键的是第二步,两个要点:
- 先选中数据块 Element,每块数据我们在页面上取,都是重复的,选中 Multiple
- 在数据块中再取需要的数据字段(上图Excel中的列)
爬取大量数据的要点,在于掌握分页的控制。
分页分为3种情况:
- URL 参数分页(比较规整方式)
URL 中带有分页的 page 参数的,如:
https://www.zhihu.com/people/excited-vczh/followers?page=2
直接在创建sitemap时,Start URL中就可以带上分页参数,写成这样:
https://www.zhihu.com/people/excited-vczh/followers?page=[1-27388]
滚动加载,点击“加载更多” 加载页面数据
点击分页数字标签(包括“下一页”标签)
注意,这里第2-3种可以归为一类方式,是异步加载的方式,大部分都可以转为第1种的方式来处理。
这种方式分页不太好控制。一般使用 Link 或 Element click 来实现分页的操作。
图示 Web Scraper 操作步骤:


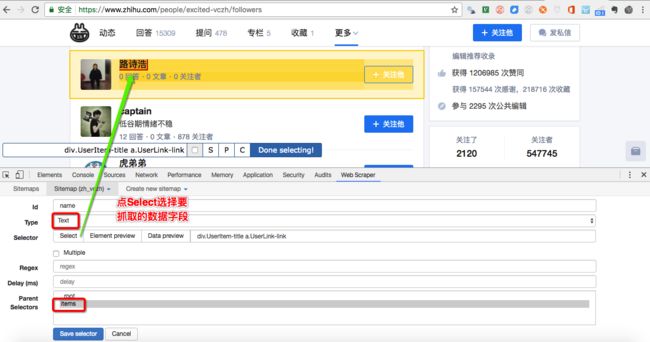

Web Scaper 使用体会:
除了规整的分页方式外,其他分页方式不好控制,不同的网站受页面标签不同,操作也不一样。
因为直接抓取页面显示值,抓取数据规整度不太好,需要 EXCEL 函数处理。
如,七日热门中文章发表时间,格式有好几种。有一点网页代码基础的上手很快,代码才是王道啊。
特别是有点Python爬虫基础的,在选取页面数据中很容易操作、理解,发现操作中出现的问题。比起八爪鱼、火车头等数据采集器,web scraper不需要下载软件,免费,无需注册,还很体会一点点代码的操作。当然 web scraper 也有付费的云爬虫。
Web Scraper 还可以导入sitemap,把下面的这段代码导入,你就可以抓取到知乎轮子哥前20页的粉丝:
{"startUrl":"https://www.zhihu.com/people/excited-vczh/followers?page=[1-20]","selectors":[{"parentSelectors":["_root"],"type":"SelectorElement","multiple":true,"id":"items","selector":"div.List-item","delay":""},{"parentSelectors":["items"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.UserItem-title a.UserLink-link","regex":"","delay":""},{"parentSelectors":["items"],"type":"SelectorText","multiple":false,"id":"desc","selector":"div.RichText","regex":"","delay":""},{"parentSelectors":["items"],"type":"SelectorText","multiple":false,"id":"answers","selector":"span.ContentItem-statusItem:nth-of-type(1)","regex":"","delay":""},{"parentSelectors":["items"],"type":"SelectorText","multiple":false,"id":"articles","selector":"span.ContentItem-statusItem:nth-of-type(2)","regex":"","delay":""},{"parentSelectors":["items"],"type":"SelectorText","multiple":false,"id":"fans","selector":"span.ContentItem-statusItem:nth-of-type(3)","regex":"","delay":""}],"_id":"zh_vczh"}
PS, Web Scraper 资料教程
官网中的视频教程
http://webscraper.io/tutorials知乎@陈大欣 的回答 中写了详细的步骤,并录制了视频教程。
视频教程(1):http://www.bilibili.com/video/av9664397/
视频教程(2):http://www.bilibili.com/video/av9708200/
这个问题来源 零基础如何学爬虫技术? @陈大欣 在文章中把 Excel 爬虫,web scraper,代码爬虫做了比较分析。