机器学习专题
1、KNN之k近邻python版本实现:
np.argsort函数返回的是数组值从小到大的索引值
One dimensional array:一维数组
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])
import numpy as np
def calculate(a,b):
return np.sqrt(np.sum((a-b)**2))
def getcloest(traindata,trainlabel,x,topK):
datalist = [0]*len(trainlabel)
for i in len(traindata):
x1=traindata[i]
curlist = calculate(x1,x)
datalist[i]= curlist
topKList = np.argsort(np.array(datalist))[:topK]
labellist=[0]*10
for index in topKList:
labellist[int(trainlabel[index])] +=1
return labellist.index(max(labellist))
''
定义K近邻函数,计算并取出与x相近的topk个数的索引 np.argsort()
然后对应索引在trainlabel中找到对用标签并存储
其中labellist中存储的是 下标是标签值,位置存储的是对应个数,返回最大值对应的下标就是最近的label
'''2、K-Means伪代码实现
基本的k-means算法流程如下:
shape[0]是n行,是样本数,shape[1]是m列,是特征向量的维度,numpy数组从外到内
选取k个初始质心(作为初始cluster,每个初始cluster只包含一个点);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluster对应的质心(质心是cluster中样本点的均值);
until 质心不再发生变化
'''
创建k个点作为起始支点(随机选择)
当任意一个簇的分配结果发生改变的时候
对数据集的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据分配到距离其最近的簇
对每一簇,计算簇中所有点的均值并将其均值作为质心
'''
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
data = X[:,[1,3]] # 为了便于可视化,只取两个维度
plt.scatter(data[:,0],data[:,1]);
def rand_center(data,k):
"""Generate k center within the range of data set."""
n = data.shape[1] # features
centroids = np.zeros((k,n)) # init with (0,0)....
for i in range(n):
dmin, dmax = np.min(data[:,i]), np.max(data[:,i])
centroids[:,i] = dmin + (dmax - dmin) * np.random.rand(k)
return centroids
'''
centroids = randCent(data,2)
centroids
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
m= np.mat([1,2,3]) #创建矩阵
>>> m
matrix([[1, 2, 3]])
'''
def distance(k1,k2):
return np.sqrt(np.sum((k1-k2)**2))
def _converged(centroids1, centroids2):
# if centroids not changed, we say 'converged'
set1 = set([tuple(c) for c in centroids1])
set2 = set([tuple(c) for c in centroids2])
return (set1 == set2)
def Kmeans(dataset,k):
n = data.shape[0] # number of entries
centroids = randCent(data,k)
label = np.zeros(n,dtype=np.int) # track the nearest centroid
assement = np.zeros(n) # for the assement of our model
converged = False
itera =0
while not converged:
old_centroids = np.copy(centroids)
for i in range(n):
# determine the nearest centroid and track it with label
min_dist, min_index = np.inf, -1
for j in range(k):
dist = distance(data[i],centroids[j])
if dist < min_dist:
min_dist, min_index = dist, j
label[i] = j
assement[i] = distance(data[i],centroids[label[i]])**2
itera+=1
# update centroid
for m in range(k):
centroids[m] = np.mean(data[label==m],axis=0)
return centroids, label, np.sum(assement)
3、HMM伪代码实现
4、计算AUC,ROC曲线,F1值等代码
优秀博客:https://blog.csdn.net/hesongzefairy/article/details/104295431
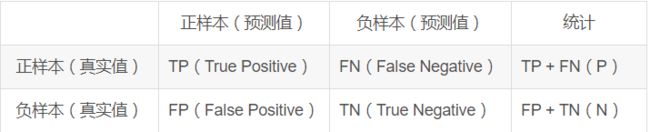
其中TP,FP,TN,FN都是相对与预测结果而言,TP,TN表示预测正确,且预测结果分别为正负样本,FN,FP表示预测结果错误,预测结果分别为负样本,正样本
其中准确率为
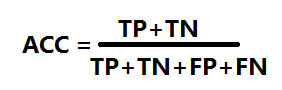
精确率precison相对于正样本而言,正样本中划分正确的比例
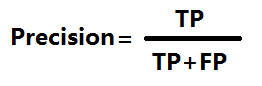
召回率recall,抓回的人中有多少人是小偷,有多少小偷被抓回来

ROC曲线的横坐标为FPR(假正率),纵坐标为TPR(真正率)
FPR(False Positive Rate):预测错误的负样本/负样本总数
TPR(True Positive Rate)又称灵敏度(Sensitivity):预测正确的正样本/正样本总数 
当我们改变模型的阈值,预测结果中的TP FN TN FP都会相应的改变,即每一个阈值都会有一组(TPR, FPR)对应,ROC曲线就是不断的移动分类器的阈值来产生曲线上的关键点,其中围成的面积就是AUC精度
5、LR逻辑回归代码
def LR(data,label,iter=200):
for i in range(len(data):
data[i].appebd(1)
data = np.array(data)
w=np.zeros(data.shape[1])
h=0.001
for i in range(iter):
for j in range(data.shape[0]):
wx=np.dot(w,data[j])
yi = label[j]
xi = data[j]
w+=h *(xi *yi-(np.exp(wx)*xi)/(1+np.exp(wx)))
return w
def predict(w, x):
wx = np.dot(w, x)
P1 = np.exp(wx) / (1 + np.exp(wx))
if P1 >= 0.5:
return 1
return 06、面试题目总结
1、ID3为什么可以处理离散值,C4.5可以处理连续值嘛?为什么还要提出C4.5这种方案呢?
ID3通过计算信息增益来选择最优特征,其中信息增益的计算公式如下:

信息增益描述了引入特征A后对数据集分类的熵的不确定度的影响,信息增益越大,具有越强的分类能力,但是它存在一个缺点,ID3的分类结果广而不深,,偏向于取值多的特征划分,因此才引入信息增益比的物理量进行描述:
同时ID3在进行划分时必须是离散值,比如它只针对密度=4.5的这个值进行特征赋值,但是这个特征可能有无穷多种取值,所以并不适用,引入C4.5进行连续特征划分,预排序后选择相邻特征的平均值作为区分二分类问题,依次计算信息增益比,取最大值即可。
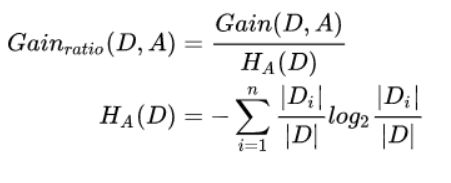
C4.5模型分母表示特征熵,对每一个特征求熵的结果,用信息增益比不仅解决了上述问题,同样适用于连续值的问题,对m个连续特征进行预排序,然后分别计算m-1个划分点前面是类别1.后边是类别2的信息增益比,实现了连续特征的离散化。
同时C4.5也处理了缺省值的情况,缺省值的样本分类和信息增益比计算参考无缺省值的数据,按照无缺省值的样本分类比例乘以权重系数进行划分和计算。C4.5也可以进行预剪枝和后剪枝操作。
c4.5的缺点:
C4.5 用的是多叉树,用二叉树效率更高;
C4.5 只能用于分类;
C4.5 使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;
C4.5 在构造树的过程中,对数值属性值需要按照其大小进行排序,从中选择一个分割点,所以只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行。
算法、支持模型 树结构 特征选择 连续值处理 缺失值处理 剪枝
ID3 分类 多叉树 信息增益 不支持 不支持 不支持
C4.5 分类 多叉树 信息增益比 支持 支持 支持
CART分类回归 二叉树 基尼系数,均方差 支持 支持 支持
2、SVM同样可以用于回归问题,支持向量机回归可以写作SVR,相当于使得回归曲线与原函数在一定误差范围内进行拟合。
从分类到回归也可以看做是从离散到连续的过渡,但是不能直接拿过来用。
同时在推导过程中,要求a>0的那些向量才可以看做判别函数,只是与他的边界支持向量有关的。
3、XGBoost是如何实现并行化计算的?
xgb在选择最佳分裂点,进行枚举的时候并行!(据说恰好这个也是树形成最耗时的阶段)。同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。
“月收入”这种feature,取值很多,从5k~50k都有,不可能每个分割点都来计算分裂增益,因此用加权分桶,直方图统计的方式来进行分类增益的计算
xgboost并不是树尺度的并行,而是特征尺度上的并行,在进行分裂时对特征值进行排列,这一般是最耗时的,利用列采样和block进行数据存储,在计算多个特征的增益计算时开多线程并行计算。就像拟合过程中的随机梯度下降和GBDT上的梯度提升其实是一致的,一个是在参数空间求导,一个是在函数空间迭代。
4、最大池化maxpooling和平均池化avepooling的适用场景:
最大池化用于降低特征维度,可以保留图像的纹理特征,一般在浅层网络中用的比较多
平均池化保留了整体的数据特征,因此在图片的深层次时进一步考虑图像的全部特征、
7、常见的各种激活函数的区别和应用场景:
sigmod函数一般用于二分类问题的输出层,其中中间隐藏层部分一般是接Relu函数,在损失函数的搭配过程中,当采用MSE作为损失函数时,在梯度更新的过程中会出现sigmid的导数情况,因此会出现梯度更新慢的情况,因为sigmod本身函数在趋向于正负无穷时,导数为0,因此一般选用交叉熵损失函数和sigmod函数搭配的情况改进DNN中的收敛速度、
tanh函数和sigmod函数在数学表达式和图像表述上相似,其中tanh函数属于【-1,1】,相当于以零值为中心,是它的最大优点,tanh函数可以看做时sigmod在x轴方向上缩小,y轴方向扩张,向下平移所得到的。像sigmod函数取值总是正数,因此w1和w2的取值总是同乡,只会在1,3象限进行更新,因此tanh函数时优于sigmod函数的,同时sigmod和tanh也一般用于LSTM中用于门控和概率输出。
Relu函数的话存在单边抑制,同时在大于0的时候为线性,会引入一定的稀疏性,同时大于0为线性的性质可以一定程度上解决梯度消失的问题,包括RNN,LSTM,弱Relu函数的话可以引入有正有负
一般在CNN的结构中conv后一般接relu再接pooling 层,接Relu的原因就是为了将卷积产生的结果中的负数调整为0,实现非线性映射。
8、梯度消失和梯度爆炸问题:
在RNN网络中在梯度更新的过程中,同样要乘以sigmod和tanh的导数,其中sigmod导数在[0,0.25]之间,tanh导数在[0,1]之间,因此一直累乘会出现梯度消失的情况。
如果选择Relu函数的话梯度在大于0的部分大于1,又会出现梯度爆炸的情形。
选择合适的激活函数,并且设置合理阈值可以有效解决这个问题,加入BN层,改变传播结构,选用LSTM
LSTM结构在推导过程中细胞单元的求导过程中没有sigmod的导数部分,是多个因子累加的形式,所以解决梯度消失的问题,同时引入的遗忘门是sigama的逐点累加,可以在其关闭的情况下memoryC值不进行更新。同时在更新memoryC值的时候还要将memory和input值进行累加的,来解决梯度消失的问题
GRU的话是用两个单元来代替LSTM,更新门代替遗忘门和输入门,同时参数更少,更好调参,更适合于数据较少的情况
9、BN的公式推导及作用
10、梯度更新过程中的Adam方法的作用和原理
11、Res-Net用于解决梯度消失和网络层次问题
12、softmax函数的分类公式以及如何解决数值溢出的问题

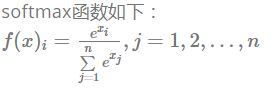
softmax函数的计算公式如上,在计算时候因为分子分母涉及到求e的指数项,当xi过大时,会发生上溢出或者下溢出,采用的解决方法是减去它的最大值后再求指数,
同时如果后续运算用到它的log的话会出现log的底数部分为0的情况,因此再减去最大值后取log

13、RNN对于变长序列的处理思路,包括lstm的处理思路:
https://blog.csdn.net/zwqjoy/article/details/95050794
对于变长序列,传统在embedding的时候可以选择补零操作。但是会过于稀疏,这种padding方式可以解决问题,但是在实际序列预测中是不合理的,因此才引入mask辅助向量来表征实际的向量长度。
目的是使用一个二维矩阵作为输入数据集,从而达到并行化的同时,还能让RNN模型自行决定真正输入其中的序列的长度
方法是在输入时不仅输入shapesize,还会输入embedding size,在训练时获得真实的向量长度
ask_a的作用就是让RNN跳过所有Mask为0的输入,复制cell中前一次的隐藏状态;对于Mask为1的输入RNN将按常规处理
其中CNN的则是采用补零操作,补零位置对卷积不会产生影响,所以可以直接padding的两种方式
keras中的mask_zero=True会直接剔除对应位置的0,不参与运算。
类目不均衡问题:基本是一个在很多场景都验证过的结论:如果你的loss被一部分类别dominate,对总体而言大多是负向的。建议可以尝试类似 booststrap 方法调整 loss 中样本权重方式解决。
避免训练震荡:默认一定要增加随机采样因素尽可能使得数据分布iid,默认shuffle机制能使得训练结果更稳定。如果训练模型仍然很震荡,可以考虑调整学习率或 mini_batch_size。
14、在医学图像分割中为什么要用U-Net,他的特点是什么,为什么效果好?有了解过其他分割方法嘛?网络结构,里面用的损失函数,优化器,评价指标,论文的创新点在哪里、
U-Net类似于一般的语义分割网络,在医学分割中应用广泛。
最大的特点是U型结构与它的跳变连接结构。一共下采样4次,下采样16倍,同时上采样4次恢复到输入的图像规模,实现语义分割。
它并没有像一般网络一样直接在高层特征上进行监督和loss反传,跳变连接结构将低层不同规模的feature进行融合,所以可以进行多尺度融合和深度监督。
同时在医学图像固有的特点,语义简单,结构固定,一般在固定区域发生病变与明显变化
数据量少,u-net比起一般的深层网络参数少
多模态,可解释性强。UNet结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据),完美适用于医学图像分割。
15、Sobel算子的原理和运算,k-means怎么做的聚类?原理与应用
利用相邻像素点之间的差值来模拟图片像素上的梯度,同时由于边缘检测的敏感性,一般要求先要对图像进行去噪处理
Sobel算子是一个3×3的卷积核,利用局部差分寻找边缘,计算得到梯度的近似值。x和y方向的
Sobel算子分别为:
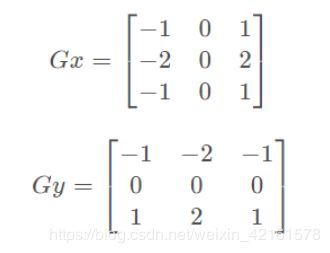
,他们的具体数值不同而已。
而后还有Canny边缘检测,边缘检测的一般标准包括:
1. 以低的错误率检测边缘,也即意味着需要尽可能准确的捕获图像中尽可能多的边缘。
2. 检测到的边缘应精确定位在真实边缘的中心。
3. 图像中给定的边缘应只被标记一次,并且在可能的情况下,图像的噪声不应产生假的边缘
完成一个Canny边缘检测算法可以分为以下四步:
1.利用高斯滤波去噪。噪声会影响边缘检测的准确性,因此要先将噪声过滤掉。
2.计算梯度幅值和方向(sobel算子)
3.非极大值抑制。(保留局部梯度最大点,细化边缘)
4.应用双阈值确定真实的和可能的边缘。(强边缘、虚边缘实现连接)