触类旁通Elasticsearch:操作
一、索引数据
1. 使用映射定义文档
映射里包含了一个索引的文档中所有字段的定义,并告诉ES如何索引一篇文档的多个字段。例如,如果一个字段包含日期,可以定义哪种日期格式是可以接受的。映射的概念类似于DB中的表字段定义。
ES会自动识别字段,并根据数据相应地调整映射。但是在生产应用中,通常需要预先定义自己的映射,而不依赖于自动的字段识别。向类型的_mapping接口发送HTTP GET请求可以获得字段当前的映射:
curl '172.16.1.127:9200/get-together/_doc/_mapping?pretty'(1)自动映射
索引新文档时ES可以自动创建映射,例如下面的命令会自动创建my_index索引,在其中索引一个ID为1的文档,该文档有name和date两个字段:
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Late Night with Elasticsearch",
"date": "2013-10-25T19:00"
}'查看自动生成的映射:
curl '172.16.1.127:9200/my_index/_doc/_mapping?pretty'结果如下:
{
"my_index" : {
"mappings" : {
"_doc" : {
"properties" : {
"date" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
} 为不同目的以不同方式索引相同字段通常很有用。这是多领域的目的。例如,字符串字段可以映射为全文搜索的文本字段,也可以映射为排序或聚合的keyword字段。如上例中的fields允许对同一索引中的同名字段具有不同的设置。对于字符串数据,ES缺省映射为text和keyword两种类型。(2)手工定义新映射
可以在创建索引后,插入文当前定义映射,就像建表一样:
curl -XPUT '172.16.1.127:9200/my_index?pretty'
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"_doc": {
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}'索引创建后,可以修改映射,例如在my_index中增加host字段:
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"_doc": {
"properties": {
"host": {
"type": "text"
}
}
}
}'如果在现有基础上再设置一个映射,ES会将两者合并,例如上面的命令执行后,得到的映射如下:
{
"my_index" : {
"mappings" : {
"_doc" : {
"properties" : {
"date" : {
"type" : "date"
},
"host" : {
"type" : "text"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}正如所见,这个映射目前含有两个来自初始映射的字段,外加定义的一个新字段。随着新字段的加入,初始的映射被扩展了,在任何时候都可以进行这样的操作。ES将此称为映射合并。但是,不能改变现有字段的数据类型:
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"_doc": {
"properties": {
"host": {
"type": "long"
}
}
}
}'将返回以下错误:
{
"error" : {
"root_cause" : [
{
"type" : "remote_transport_exception",
"reason" : "[node126][172.16.1.126:9300][indices:admin/mapping/put]"
}
],
"type" : "illegal_argument_exception",
"reason" : "mapper [host] of different type, current_type [text], merged_type [long]"
},
"status" : 400
}修改字段类型意味着ES必须重新索引数据。正确的映射,理想情况下只需要增加,而无需修改。为了定义这样的映射,来看看ES中可为字段选择的数据类型。
2. 基本数据类型
(1)字符串
如果在索引字符,字段就应该是text类型,在索引中有很多选项来分析它们。解析文本、转变文本、将其分解为基本元素使得搜索更为相关。这个过程在ES中叫做“analysis”。先看看分析的基本原理,下面的命令在my_index中索引一篇文档:
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Late Night with Elasticsearch",
"date": "2013-10-25T19:00"
}'当这篇文档索引后,在name字段里搜索单词late:
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"query_string": {
"query": "late"
}
}
}'搜索发现了索引中的“Late Night with Elasticsearch”文档。ES通过分析连接了字符串“late”和“Late Night with Elasticsearch”。如图1所示,当索引“Late Night with Elasticsearch”时,默认的分析器将所有字符串转化为小写,然后将字符串分解为单词。
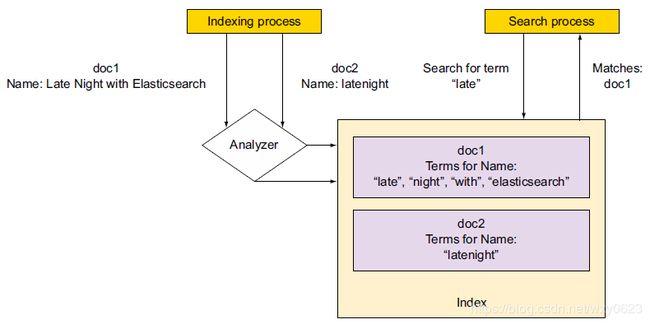 图1 在默认的分析器将字符串分解为词条后,随后的搜索匹配了那些词条
图1 在默认的分析器将字符串分解为词条后,随后的搜索匹配了那些词条
分析过程生成了4个词条,即late、night、with和elasticsearch。查询的字符串经过同样的处理。因为查询生成的late词条和文档生成的late词条匹配了,所以文档1匹配上了搜索。这种匹配有点像SQL中的where lower(name) like concat('%',lower('late'),'%')。
一个词条是文本中的一个单词,是搜索的基本单位。如果只想严格匹配某个字段,就像SQL中的where name = 'late',应该将整个字段作为一个单词对待。ES对文本类型的keyword字段不做分析,而是将整个字符串当做单独的词条进行索引。下面的查询不会返回文档:
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"term": {
"name.keyword": "late"
}
}
}'但严格匹配时将返回文档1:
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"term": {
"name.keyword": "Late Night with Elasticsearch"
}
}
}'(2)数字
数值类型可以是浮点数或非浮点数。如果不需要小数,可以选择byte、short、int或long。如果确实需要小数,选择可以是float或double。这些类型对应于Java的原始数据类型,对于它们的选择会影响索引的大小,以及能够索引的取值范围。例如,long需要64位,而short只需要16位,但short只能存储-32768到32767之间的数字。
如果不知道所需要的整型数字取值范围,或者是浮点数字的精度,让ES自动检测映射更为安全:为整数值分配long,为浮点数值分配double。索引可能变得更大更慢,因为这两种类型占据更多的空间,但在索引过程中ES不会发生超出范围的错误。
(3)日期
date类型用于存储日期和时间。它是这样运作的:通常提供一个表示日期的字符串,例如2013-10-25T19:00。然后,ES解析这个字符串,将其作为long的数值存入Lucene的索引。该long型数值是从1970年1月1日 00:00:00 UTC 到所提供时间之间已经过去的毫秒数。
搜索文档时仍然提供date字符串,ES将这些字符串解析并按照数值来处理。这样做的原因是和字符串相比,数值在存储和处理时更快。
date字符串的数据格式是通过format选项来定义的,ES默认解析ISO 8601的时间戳。使用format选项来指定日期格式的时候,有以下两种选择:
- 使用预定义的日期格式。参见https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html#built-in-date-formats
- 设置自己定制的格式。
curl -XPUT '172.16.1.127:9200/my_index/_mapping/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"properties": {
"next_event": {
"type": "date",
"format": "MMM DD YYYY"
}
}
}'next_event字段使用定制的日期格式,其它日期被自动检测,不显式定义。
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Elasticsearch News",
"first_occurence": "2011-04-03",
"next_event": "Oct 25 2013"
}'查看映射:
curl '172.16.1.127:9200/my_index/_doc/_mapping?pretty'结果返回:
{
"my_index" : {
"mappings" : {
"_doc" : {
"properties" : {
"date" : {
"type" : "date"
},
"first_occurence" : {
"type" : "date"
},
"host" : {
"type" : "text"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"next_event" : {
"type" : "date",
"format" : "MMM DD YYYY"
}
}
}
}
}
}(4)布尔
boolean类型用于存储文档中的true/false,例如:
curl -XPUT '172.16.1.127:9200/my_index/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Broadcasted Elasticsearch News",
"downloadable": true
}' downloadable字段被自动地映射为boolean,在Lucene的索引中被存储为T和F。和date一样,ES解析源文档中提供的值,将true和false分别转化为T和F。(5)数组
所有基本类型都支持数组,无须修改映射,既可以使用单一值,也可以使用数组:
curl -XPUT '172.16.1.127:9200/blog/posts/1?pretty' -H 'Content-Type: application/json' -d '
{
"tags": ["first", "initial"]
}'
curl -XPUT '172.16.1.127:9200/blog/posts/2?pretty' -H 'Content-Type: application/json' -d '{"tags": "second"}'
curl 'localhost:9200/blog/_mapping/posts?pretty'结果返回:
{
"blog" : {
"mappings" : {
"posts" : {
"properties" : {
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}可以看到,映射中并不定义数组,而是定义为基本类型。对于Lucene内部而言,单值和数组两者基本是一致的,在同一字段中索引多少词条完全取决于提供了多少值。
3. 多字段
数组允许用一个设置索引多项数据,而多字段允许使用不同的设置,对同一项数据索引多次。例如:
curl -XPUT '172.16.1.127:9200/blog/_mapping/posts?pretty' -H 'Content-Type: application/json' -d '
{
"posts": {
"properties": {
"tags": {
"type": "text",
"index": true,
"fields": {
"verbatim": {
"type": "text",
"index": false
}
}
}
}
}
}'无须重新索引数据,就能将单字段升级到多字段。反之是不行的,一旦字段已经存在,就不能将其抹去:
curl -XPUT '172.16.1.127:9200/blog/_mapping/posts?pretty' -H 'Content-Type: application/json' -d '
{
"posts": {
"properties": {
"tags": {
"type": "text"
}
}
}
}'
curl 'localhost:9200/blog/_mapping/posts?pretty'结果如下:
{
"blog" : {
"mappings" : {
"posts" : {
"properties" : {
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"verbatim" : {
"type" : "text",
"index" : false
}
}
}
}
}
}
}
}因为修改映射时ES只是执行映射合并,所以并不会去掉verbatim字段。
4. 预定义字段
预定义字段与自定义字段在三个方面有所不同:
- 通常不用部署预定义的字段。
- 字段名揭示了相关字段的功能。
- 总是以下划线(_)开头。
(1)_source
_source字段按照原有格式来存储原有文档。搜索的时候会获得_source的JSON:
curl '172.16.1.127:9200/get-together/_doc/1?pretty'结果返回:
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"relationship_type" : "group",
"name" : "Denver Clojure",
"organizer" : [
"Daniel",
"Lee"
],
"description" : "Group of Clojure enthusiasts from Denver who want to hack on code together and learn more about Clojure",
"created_on" : "2012-06-15",
"tags" : [
"clojure",
"denver",
"functional programming",
"jvm",
"java"
],
"members" : [
"Lee",
"Daniel",
"Mike"
],
"location_group" : "Denver, Colorado, USA"
}
}搜索时可以要求ES只返回指定的字段,而不是整个_source。
curl -XGET '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d '
{
"query": {
"terms": {
"_id": [
"1"
]
}
},
"_source": [
"name",
"organizer"
]
}'结果返回:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"organizer" : [
"Daniel",
"Lee"
],
"name" : "Denver Clojure"
}
}
]
}
}功能类似于如下SQL:
select name, organizer from get-together where id=1;(2)_all
_source字段存储所有信息,而_all是索引所有的信息。_all字段将所有字段的值连接成一个大字符串,使用空格作为分隔符,然后对其进行分析和索引,但不进行存储。这意味着可以把它作为搜索条件,但不能返回它。_all字段允许在不知道哪个字段包含值的情况下搜索文档中的值。 如果不指定字段名,系统默认将会在_all上搜索,下面的两条命令是等价的,返回相同的结果:
curl '172.16.1.127:9200/get-together/_search?q=elasticsearch&pretty'
curl -X GET '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"query_string": {
"query": "elasticsearch"
}
}
}'(3)_index、_type、_id
ES用这三个字段识别单个文档。ID可以由用户手动提供:
curl -XPUT '172.16.1.127:9200/manual_id/_doc/1st?pretty' -H 'Content-Type: application/json' -d '
{
"name": "Elasticsearch Denver"
}'可以在回复中看到ID:
{
"_index" : "manual_id",
"_type" : "_doc",
"_id" : "1st",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}也可以由ES自动生成唯一ID:
curl -XPOST '172.16.1.127:9200/logs/_doc/?pretty' -H 'Content-Type: application/json' -d '
{
"message": "I have an automatic id"
}'可以在回复中看到自动生成的ID:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "iEbXOmgBWHJVyzwYQ9ho",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}除了_id和_type,ES还在文档中存储索引的名称。可以在搜索或者是GET请求中看到_index。
curl '172.16.1.127:9200/_search?q=_index:get-together&pretty'
curl '172.16.1.127:9200/_search?q=_index:blog&pretty'二、更新数据
ES中更新文档有两种方法,一是PUT一篇不同的文档到相同的地方(索引、类型和ID),功能上类似于SQL中的replace into;二是使用更新API。例如执行类似SQL中的如下功能:
update get-together set organizer='Roy' where id=2;更新API的流程如图2所示。
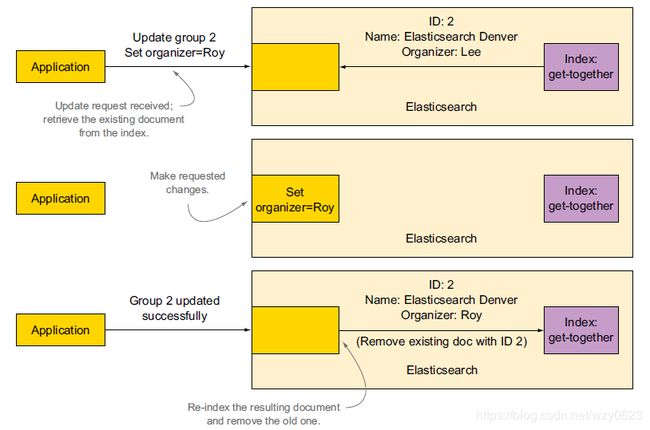 图2 文档的更新包括取回文档、处理文档、并重新索引文档,直至先前的文档被覆盖
图2 文档的更新包括取回文档、处理文档、并重新索引文档,直至先前的文档被覆盖
如图2所示,ES进行了如下操作(从上至下):
- 从_source字段检索现有文档。
- 进行指定的修改。
- 删除旧的文档,在其原有位置索引新的文档。
1. 使用更新API
(1)发送部分文档
curl -XPOST '172.16.1.127:9200/get-together/_doc/2/_update?pretty' -H 'Content-Type: application/json' -d '
{
"doc": {
"organizer": "Roy"
}
}'这条命令设置了在doc下指定的字段,将其值设置为所提供的值。它并不考虑这些字段之前的值,也不考虑这些字段之前是否存在。如果之前整个文档是不存在的,那么更新操作会失败,并提示文档缺失。
(2)使用upsert
为了处理更新时文档并不存在的情况,可以使用upsert。这个单词是关系数据库中update和insert的混成词。如果被更新的文档不存在,可以在JSON的upsert部分中添加一个初始文档用于索引:
curl -XPOST '172.16.1.127:9200/get-together/_doc/2/_update?pretty' -H 'Content-Type: application/json' -d '
{
"doc": {
"organizer": "Roy"
},
"upsert": {
"name": "Elasticsearch Denver",
"organizer": "Roy"
}
}'(3)通过脚本更新文档
一个更新脚本具有以下三项重要元素:
- 默认的脚本语言是painless。
- 由于更新要获得现有文档的_source内容,修改并重新索引新的文档,因此脚本会修改_source中的字段。使用ctx._source来引用_source,使用ctx._source[字段名]来引用某个指定的字段。
- 如果需要变量,推荐在params下作为参数单独定义,和脚本本身分开。这是因为脚本需要编译,一旦编译完成,就会被缓存。如果使用不同的参数,多次运行同样的脚本,脚本只需要编译一次。之后的运行都会从缓存中获取现有的脚本。相比每次不同的脚本,这样运行会更快,因为不同的脚本每次都需要编译。这个思想和Oracle的绑定变量与软编译概念异曲同工。
curl -XPUT '172.16.1.127:9200/online-shop/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"caption": "Learning Elasticsearch",
"price": 15
}'
curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?pretty' -H 'Content-Type: application/json' -d '
{
"script": {
"source": "ctx._source.price += params.price_diff",
"params": {
"price_diff": 10
}
}
}'
curl -XGET '172.16.1.127:9200/online-shop/_doc/1?pretty'结果返回:
{
"_index" : "online-shop",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source" : {
"caption" : "Learning Elasticsearch",
"price" : 25
}
}price已经改为25。
2. 通过版本实现并发控制
ES本身没有事务概念,但由于ES的文档更新是先取出再更改,所以并发更新文档时同样存在数据库领域中所谓的“第二类丢失更新”问题。如图3所示,在其它更新获取原有文档并进行修改期间,有可能另一个更新重新索引了这篇文档。如果没有并发控制,第二次的重新索引将会覆盖第一次更新所做的修改。
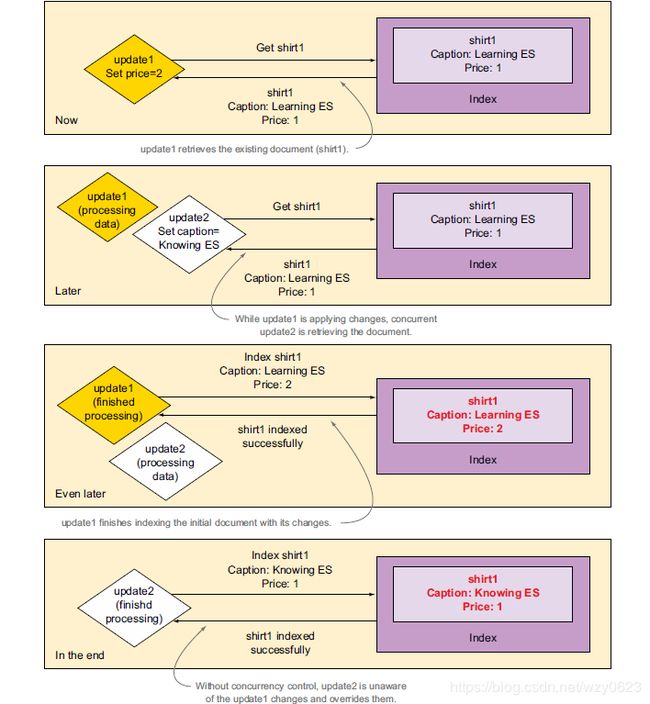 图3 没有并发控制,修改就可能会丢失
图3 没有并发控制,修改就可能会丢失
ES使用文档的_version字段进行并发控制。它采用一种乐观锁定防止第二类丢失更新,思想类似于Oracle 11g的Row Version。理论上可以使用下面的代码重现图3所示的流程,但遗憾的是,6.4.3版本的ES使用painless作为脚本语言,其中不支持Thread.sleep方法,因此执行这段代码会失败。
/***
curl -XPOST 'localhost:9200/online-shop/shirts/1/_update' -d '{
"script": "Thread.sleep(10000); ctx._source.price = 2"
}' &
% curl -XPOST 'localhost:9200/online-shop/shirts/1/_update' -d '{
"script": "ctx._source.caption = \"Knowing Elasticsearch\""
}'
***/这里使用下面的代码来演示version的作用:
curl -XGET "172.16.1.127:9200/online-shop/_doc/1?version=2&pretty"
curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?pretty' -H 'Content-Type: application/json' -d '
{
"script": "ctx._source.caption = \"Knowing Elasticsearch\""
}'
curl -XGET "172.16.1.127:9200/online-shop/_doc/1?version=2&pretty"当最后一个命令查询已经被更新的版本数据时,会报以下错误:
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[_doc][1]: version conflict, current version [3] is different than the one provided [2]",
"index_uuid" : "b6z8mwmRQ1ambP9g5rv9vQ",
"shard" : "3",
"index" : "online-shop"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[_doc][1]: version conflict, current version [3] is different than the one provided [2]",
"index_uuid" : "b6z8mwmRQ1ambP9g5rv9vQ",
"shard" : "3",
"index" : "online-shop"
},
"status" : 409
}使用版本控制并发后的流程如图4所示。
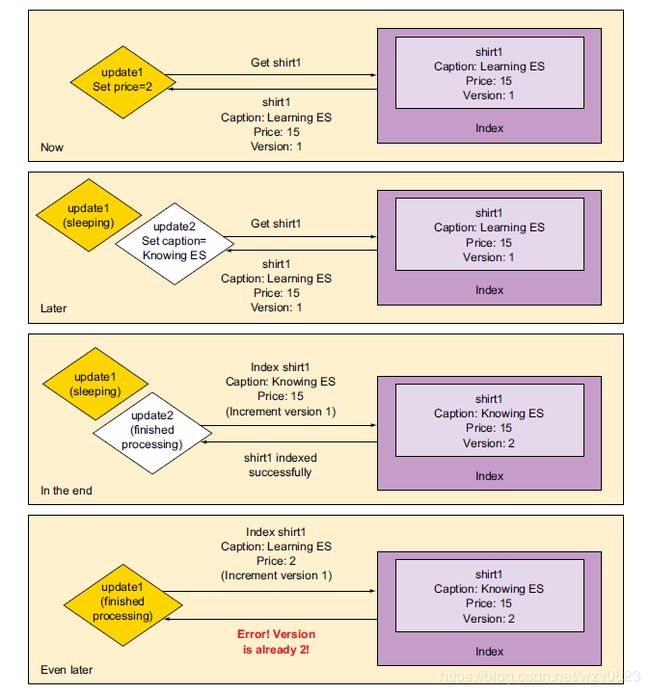 图4 通过版本来控制并发,预防了一个更新覆盖另一个更新
图4 通过版本来控制并发,预防了一个更新覆盖另一个更新
当版本冲突出现的时候,可以通过retry_on_conflict参数,让ES自动重试:
curl -XPOST '172.16.1.127:9200/online-shop/_doc/1/_update?retry_on_conflict=3&pretty' -H 'Content-Type: application/json' -d '
{
"script": "ctx._source.price = 2"
}'更新文档的另一个方法是不使用更新API,而是在同一个索引、类型和ID之处索引一个新的文档。这样的操作会覆盖现有文档,这种情况仍然可用版本字段来进行并发控制。为了实现这一点,要设置HTTP请求中的version参数。例如当前版本为4,重新索引的请求命令如下:
curl -XPUT "172.16.1.127:9200/online-shop/_doc/1?version=6&pretty" -H 'Content-Type: application/json' -d '
{
"caption": "I Know about Elasticsearch Versioning",
"price": 5
}'如果更新时的版本实际上已经不是4,那么这个操作就会抛出版本冲突的异常并失败。
三、删除数据
1. 删除文档
删除单个或一组文档时,ES只是将它们标记为删除,所以它们不会在出现于搜索结果中,稍后ES通过异步的方式将它们彻底从索引中删除。
curl -XDELETE '172.16.1.127:9200/online-shop/_doc/1?pretty'也可以使用版本来管理删除操作的并发,但删除的版本控制有个特殊情况。一旦删除了文档,它就不复存在了,于是一个更新操作很容易重新创建该文档,尽管这是不应该发生的(假设更新的版本要比删除的版本更低)。为了防止这样的问题发生,ES将在一段时间内保留这篇文档的版本,如此它就能拒绝版本比删除操作更低的更新操作了。这个时间段默认是60秒,可以通过index.gc_deletes来修改它。
可以查询某个索引中的文档并删除它们:
curl -X POST "172.16.1.127:9200/my_index/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"query_string": {
"query": "elasticsearch"
}
}
}'2. 删除索引
# 删除一个索引
curl -XDELETE "172.16.1.127:9200/blog?&pretty"
# 删除多个索引
curl -XDELETE "172.16.1.127:9200/my_index,manual_id?&pretty"删除索引是很快的,因为它基本上就是移除了和索引分片相关的文件。和删除单独的文档相比,删除文件系统中的文件更快。从执行时间上看,其实数据库也一样,通常drop table比delete快得多。删除索引的时候,文件只是被标记为已删除,在分段进行合并时,它们才会被删除。这里的合并是指将多个Lucene小分段组合为一个更大分段的过程。
3. 关闭索引
除了删除索引,还可以选择关闭它们。如果关闭一个索引,就无法通过ES读写其中的数据。当使用应用日志这样的流式数据时,此操作非常有用。可以关闭旧的索引释放ES资源,但又不删除它们以防后续使用。
# 关闭索引
curl -XPOST '172.16.1.127:9200/logs/_close?pretty'
# 打开索引
curl -XPOST '172.16.1.127:9200/logs/_open?pretty'一旦索引被关闭,它在ES中内存中唯一的痕迹是其元数据,如索引名以及分片的位置。可以重新打开被关闭的索引,然后在其中再次搜索。