Hbase
Hbase
Hbase概述:Hbase是一个构建在HDFS上的分布式存储系统,主要用于海量结构化数据存储,从逻辑上讲,Hbase将数据库按照表、行和列进行存储。
Hbse与HDFS对比:都具有良好的容错性和扩展性,均可扩展成百上千个节点;
HDFS:写模式:适合批处理场景,只支持增加,不支持数据随机查找,不适合增量数据处理,不支持数据更新(其中ORC支持更新,在hive里)。
读模式:全表扫描,分区扫描(hive的特性)
Hive(SQL)支持:非常好
量大
Hbase:写模式:一个随机的块增量的写。
读模式:随机读,小范围的扫描,全表扫描
Hive(SQL)支持:慢(MapReduce对Hbase操作)
较小
1. Hbase特点
老师总结图:

Crud操作!
HBase中表的特点
大: 一个表可以由百亿行,上百万列(列多时,插入变慢)
面向列:面向列(族)的存储和权限控制,列(族)独立检索
稀疏:对于为空(null) 的列,并不占用存储空间,因此表可以设计的非常稀疏。
多版本:每个Cell中的数据可以由多个版本,默认情况下版本号自动分配为时间戳。
类型唯一:HBase中的数据都是字符串,没有类型
NoSQL的数据库优势
1.1 扩展性强
1.2 并发性能好
NoSQL大数据量下性能好得益于它的弱关系性,数据库的结构简单。
Hbase 特性
Hbase作为一个典型的NoSQL数据库,仅支持单行事物。Hbase设计目标主要依靠横向扩展,通过不断增加廉价的商用服务器来增加计算能力。
1.2.1 容量巨大
HBase单表可以有百亿行、百万列,数据矩阵横向和纵向两个纬度所支持的数据量级都非常具有弹性。千万列亿级可能会超时。如果限定列则不会出现超时问题
1.2.2 面向列
HBase是面向列的存储和权限控制,并支持独立检索。列式存储 其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。比如一个字段的数据聚集存储。就更容易为这种聚集存储设计更好的压缩算法。
* 传统的行式数据库特性如下:
数据是按行存储的
没有索引的查询使用大量的I/O.
建立索引和物化视图需要花费大量的时间和资源
面对查询需求,数据库必须被大量膨胀才能满足需求
* 列式数据库的特性
数据按列存储,即每一列单独存放。
数据即索引
只访问查询涉及的列,可以大量降低系统I/O
每一列由一个线索来处理,即查询的并发处理性能高。
数据类型一致,数据特征相似,可以高效压缩
列式存储不但解决了数据稀疏性问题,最大程度节省存储开销,而且在查询发生时,仅检索查询涉及的列,能够大量降低磁盘I/O.这些特性也支撑HBase能够保证一定的读写性能。
1.2.3 稀疏性
大多数情况下,行式存储的数据往往是稀疏的,即存在大量为空(null)的列,而这些列都是占用存储空间的,这就造成存储空间的浪费。对HBase来讲,为空的列并不占用存储空间,因此,表可以设计的非常稀疏。
1.2.4 扩展性
底层依赖于HDFS.同时,HBase的Region和RegenServer的概念对应的数据可以分区,分区后数据可以位于不同的机器上,所以在HBase 核心架构具备可扩展性。Hbase的扩展性是热扩展,在不停止现有服务的情况下,可以随时添加或减少节点。
1.2.5 高可靠性
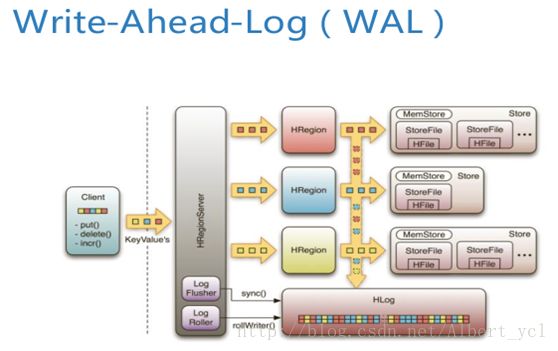
1WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失: Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS,HDFS本身也有备份。
在往HFile写数据之前,先向Hlog写一个日志。
1.2.6 高性能
底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得Hbase具有非常高的写入性能。Region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别。同时HBase对于高并发的场景也具备很好的适应能力。该特性也是业界众多公司选取HBase作为存储数据库的非常重要的一点
1.2.7 容错性

1.3.1. 重要的组建都有高可用的配置。
1.3.2. Master不能用了,必须停机检查。
1.3.3. 在zookeeper上会存储一些元数据,所以Region Server不能用后数据依然不会丢掉。
1.3.4. zookeekper一般配置奇数个,一般3个,保险的话5个。
RegionServer定期向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上;失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer。
2. Hbase适用的场景
老师总结图:

2.1、存储大量的数据(TB级数据),hbase适合大数据量的查询,但并不适合大范围的查询;kv大,只适合kv形式。
2.2、需要很高的写吞吐量;快速读取批量数据
2.3、在大规模数据集中进行很好性能的随机访问(基于RowKey);写入频繁
2.4、需要进行数据扩展;
2.5、结构化和半结构化的数据;
2.6、不支持关系数据库特性,例如交叉列、交叉表,事务,连接;(MapReduce可以)
3. Hbase物理存储
老师总结图:
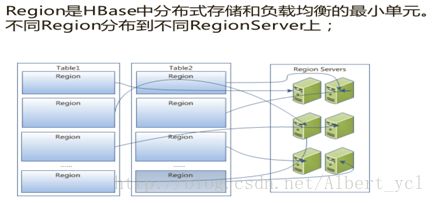
把一个大表切到不同的Region里面,不同的Region又会分到不同的Region Server之上,Region越来越大后就是分成两个Region,一个Region Server就像一个数据节点,有利于并行分布式处理,Region他是一个最小处理单元,但不意味着他最小。
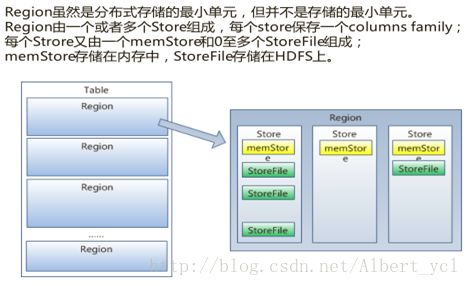
一个Region上有不同的Store(表里有十个columns family 就有十个store),并且也含有一个memstor和多个storefile,memstor在内存中,效率高。Storefile存储在HDFS中,但是,一个Region不会拆分到多个server上。
4. Hbase架构
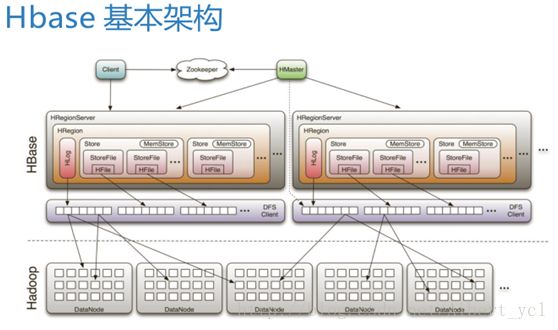
Hbase是一个数据库,数据库下面封装了一层存储,存储是由HDFS提供,HDFS也有自己的客户端和实际存储在datanode之上。
架构图包含:
Client
1 包含访问Hbase的接口,client维护着一些cache来加快对Hbase的访问,比如regione的位置信息。
Zookeeper(数据同步和数据存储)
1 保证任何时候,集群中只有一个master(还可以在起一个standby高可用)
2 存贮所有Region的寻址入口。(类似HDFS中的Namenode)
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema(元数据),包括有哪些table,每个table有哪些column family
Master
1 为Region server分配region
2 负责region server的负载均衡(分)
3 发现失效的region server并重新分配其上的region
4 GFS上的垃圾文件回收
5 处理schema更新请求,管理用户对table的增删改查
RegionServer
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
所以client访问Hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
还有Region和store.加上底层的HDFS。
流程:Client端提交作业时,先去zookeeper(存储Hbase元数据和HMaster的一些信息在HDFS上)请求Region可存储的地方,并且怎么去读和写。Client得到信息后找到相应的Region并且找到其中的store,取得相应的storefile。在去底层找到相应的HDFS文件。Master是一个整体的管理。
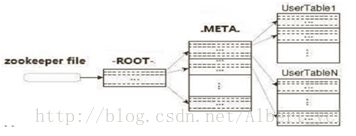

Client准确定位Region:1.请求zookeeper(HDFS).2.进入-ROOT-(单Region在Hbase),他储存所有.META.信息在HBase。3.通过root找到META表,MATE中有相信的需求表元数据信息。4.根据详细的元数据信息,去HDFS找相应的表。
比较冗余,但他只找一次,并把信息放到本地。
5. HbaseShell使用
进入Hbase shell里

按住Ctrl可删除,查询服务器状态:
![]()
查询版本:
![]()
创建表,并查看:
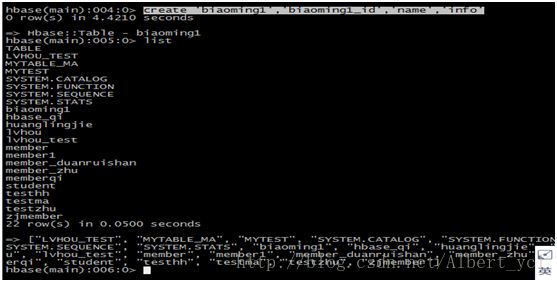
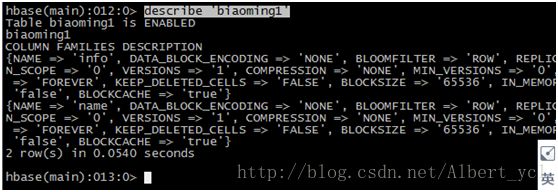
查看表的描述:

表的上线和下线:
![]()

删除列族并检查删除成功:

删除表并且下线表:
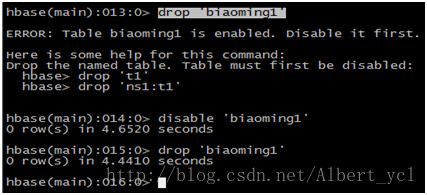
删除表后查询表是否存在在创建表检查上下线状态:

数据插入:
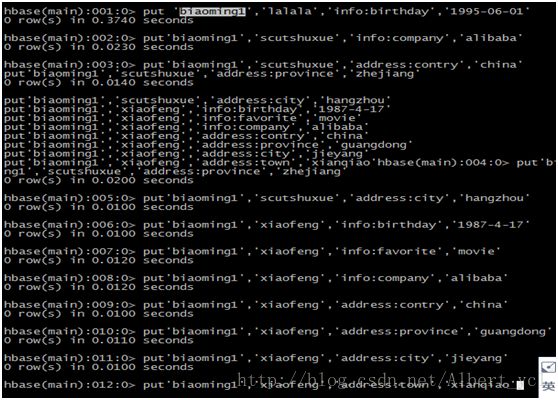
扫描全表:
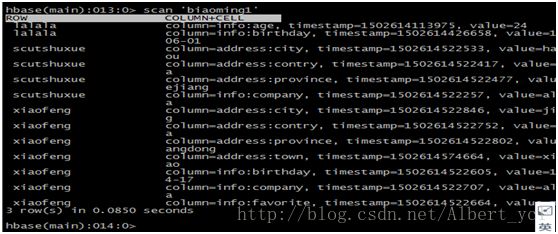
获取一条数据:

获取1个ID,一个列族的所有数据
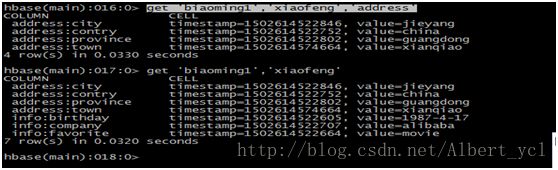
获取1个ID,一个列族中一个列的所有数据

更新1条记录
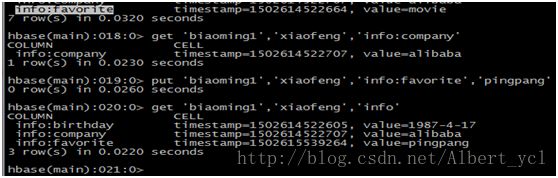
通过timestamp来获取两个版本的数据

删除sddress为lalalainfo为age的字段
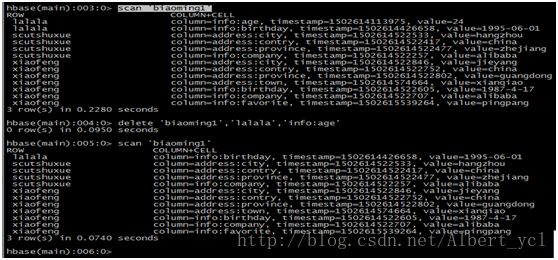
删除整行:
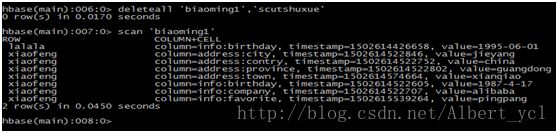
查看表中有多少行:
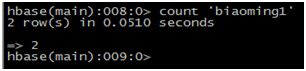
清空一张表并检查:
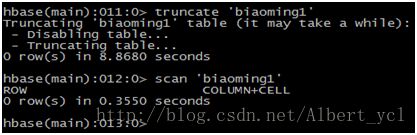
6. Hive 操作Hbase
创建hbase表:
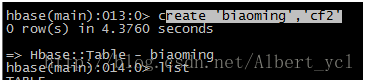
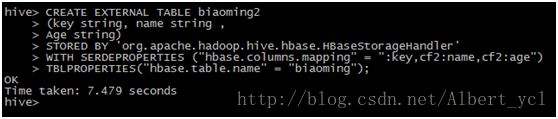
Hive建表:
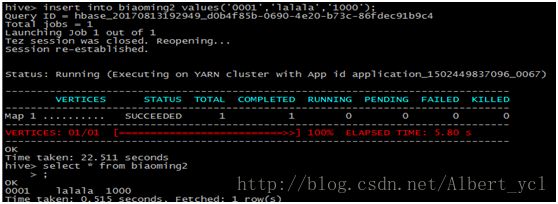
插入数据并查询:

7. Phoenix操作Hbase(官方文档常用命令)
启动位置加启动:
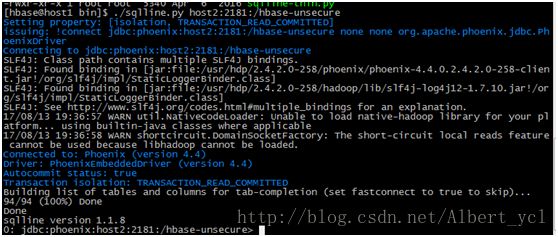
退出:
![]()
查看表格和新建表插入表:

查询:

多插入一些数据等命令:
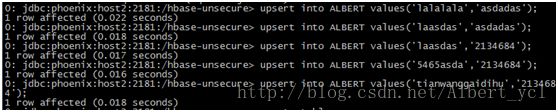
Example:
UPSERT INTO TEST VALUES('foo','bar',3);
UPSERT INTO TEST(NAME,ID) VALUES('foo',123);
UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER =COUNTER + 1;
UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE;
创建一个新表并且复制另一个表的内容:
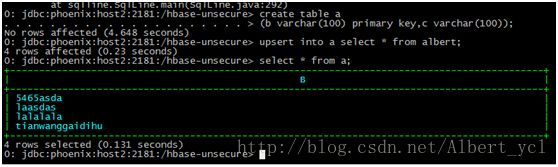
查看相关命令:
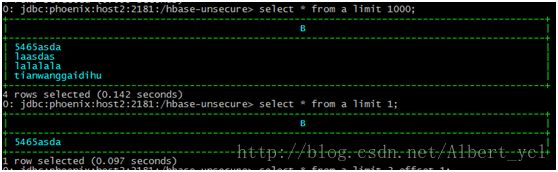
Example:
SELECT * FROM TEST LIMIT 1000;
SELECT * FROM TEST LIMIT 1000 OFFSET 100;
SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0
UNION ALL SELECT reviewer_name FROM CUSTOMER_REVIEWWHERE score >= 8.0
查看内置命令:
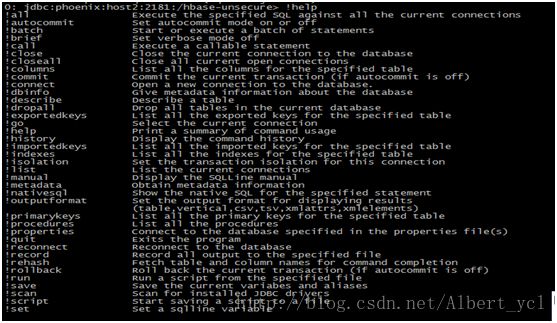
查看表结构:
![]()
修改表数据:
![]()
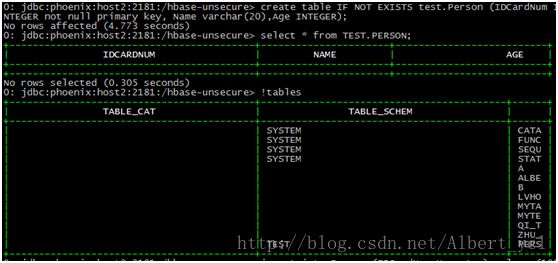
总结:
完全可以把Phoenix当成MySQL来用。但是老是出错是个问题。。。。
附加:
创建表:
