Python 之父的解析器系列之可视化 PEG 解析
让我们来看看可视化已取得的进展。截图里的屏幕被分隔为三个部分,分别是简单的 ASCII 字符,以及用连字符划出的线:
上部分显示了解析器的调用堆栈,你可能还记得它是一个具有无限回溯的递归下降解析器。我将在下面解释如何阅读它。
中间的单行部分展示了标记符缓冲区的内容,光标指向下一个要解析的标记符。
在底部,我们呈现 packrat 解析算法使用的记忆缓存。它的条目类似于一些解析器堆栈条目(具有结果的条目)。
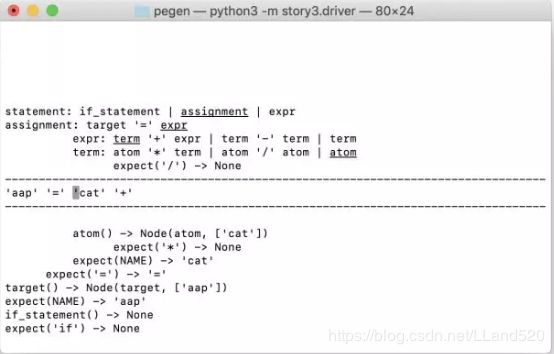
阅读此图表时,要注意的主要事项是:顶部和底部部分的缩进线与标记符缓冲区相对应。(译注:最好看一下后面的 gif 动图,再往下看这部分内容。)
前两行(以statement 和assignment 开头)表示尚未返回的解析方法调用,并且当标记位置处在第一个标记符(‘aap’ )之前时调用。
接下来的两行(以expr 和term 开头)与标记符’cat’ 的开头垂直对齐,后者是调用相应解析方法的地方。
堆栈部分所显示的第五行和最后一行是一个expect(’/’) 调用,它返回 None 。它是在标记符’+’ 处被调用的。
缓存部分的条目的缩进也对应着标记符缓冲区的位置。例如,在底部,我们看到有负数缓存条目(negative cache entries)在标记符缓冲区的开头查找标记符’if’ 以及规则if_statement 。我们还发现标记符’=’ 和NAME (特别是’cat’ )所成功缓存的条目,它们与将来的输入位置相对应。
在显示出来的解析器堆栈和缓存中,已返回的调用被显示成function(args) -> result 。有时解析器堆栈也会显示几个已返回的方法——我这样做是为了减少显示时的“跳跃性”。
(说到“跳跃”,顶部显示的解析器堆栈会在一个调用被添加到堆栈时,向上移动,而当从堆栈中弹出一个调用时,它则向下移动。似乎我们的眼睛跟随这样的动作不会有太大问题——至少我没有。这很可能因为我们大脑中有一块区域是用于跟踪移动的物体。?
缓存被可视化为一种 LRU 缓存,最近使用过的缓存条目位于顶部,较少使用的项目则向屏幕底部掉落。(我在之前的帖子中展示的 packrat 解析器原型不使用 LRU,但它可能是改善其内存使用的好策略。)
让我们看一下解析堆栈在显示时的更多一些细节。前四个条目对应于尚未返回的解析方法,每一行显示了语法中的一行。带下划线的条目会引起下一次调用。
在这种情况下,我们看到我们处于 statement 的第二种选择,也即 assignment,并且在该规则中我们处于第三项,即 expr。在 expr 规则中,我们只是在第一个可选项的第一个条目(term ‘+’ expr );而在 term 规则中,我们处在最后的选项(atom)。
在那之后,我们看到导致第二个选项(atom ‘/’ term )失败的结果:expect(’/’) - > None 用 ‘+’ 标记符缩进。当我们将可视化向前移动时,我们会看到它沉入缓存中。
但当然了,你肯定宁愿自己看动画!我已经录制了示例程序的完整解析。你也可以自己玩代码,但请注意,这只是一个临时的黑科技。
当你在观看录制的GIF时,可能会感到有些迷惑,有时下一个标记符还未显示(例如,在最开始时,堆栈在标记符’aap’ 被显示之前,就增长了几个条目)。
这正是解析器所看到的:标记符缓冲区被延迟地填充,并且在解析器通过调用 expect() 来请求它们之前,并不会扫描标记符。一旦标记符出现在缓冲区中,它就会保留在那里,即便在解析器回溯时也如此。
标记符缓冲区中的光标向左跳跃,显示了回溯过程;该动图中有很多次出现这种现象。你还可以在 gif 中观察到缓存填充,解析器在那不会进行额外的递归调用。(发现这种情况时,我应该加以强调,但我没时间了。)
关注我,持续更新更多学习内容,不懂可以留言评论相互学习交流,私信可以领取免费学习资料