声音采样率对声音事件分类的简单探究
-
环境音识别简述
通过阅读国内外文献总结出声音识别的流程如下图所示。

图1.1 声音识别流程图
从上图可知,环境音识别主要由三部分组成:声音预处理、声音特征提取以及分类器分类。这三个部分将在后面做出介绍。
-
声音预处理
在实际工程应用中声音信号的预处理包括端点检测、声音信号去噪以及信号归一化处理。其中端点检测以及声音信号的去噪是声音预处理的重点和难点。
-
1.1.1 端点检测技术
目前没有针对环境音的端点检测技术,不过我们可以借鉴语音端点检测技术。语音端点检测是从包含语音的一段声音信号中准确地确定语音的起始点和终止点。这种技术可以减少数据的采集量,节约处理时间以及排除无声段或者噪声段的干扰,提高语音识别系统的性能,而且在语音编码中还能降低噪声和静音段的比特率,提高编码效率。
(1)基于短时能量以及短时平均过零率的端点检测
语音和噪声的区别可以体现在它们的能量上,语音段的能量比噪声段能量大,语音段的能量是噪声段能量叠加语音声波能量的和。在信噪比很高时,只要计算输入信号的短时能量或短时平均幅度就能把语音段和噪声背景区分开。但是为了增加适用性,一般语音端点检测都要结合短时过零率。
短时过零率有两方面的应用:第一,用于粗略地描述信号的频谱特性;第二用于本判别轻音和浊音、有话和无话。
端点检测方法:首先为短时能量和过零率分别确定两组门限,一组是数值较低的门限,对信号的变化比较敏感,很容易超过;另一个是比较高的门限。低门限被超过未必是语音的开始,有可能是很短的噪声引起的,高门限被超过并且接下来的自定义时间段内的语音超过低门限,意味着信号开始。可以将整个端点检测可分为四段:静音段、过渡段、语音段、结束。静音段,如果能量或过零率超过低门限,就开始标记起始点,此时进入过渡段。如果过渡段中两个参数中的任一个超过高门限,即被认为进入语音段。处于语音段时,如果两参数降低到门限以下,而且总的计时长度小于最短时间门限,则认为是一段噪音,如果超过设定的最短时间门限则认为进入语音段。继续扫描后面声音信号,当声音信号两种特征均低于较低门限,此时语音结束,进入静音段。

图1.2 数字“4”的短时能量与平均过零率
除此之外还有基于倒谱特征的端点检测、基于信息熵的检测方法以及基于复杂性的端点检测(KC复杂性和C0![]() 复杂性)。
复杂性)。
-
声音特征参数提取
通过阅读国内外文献,总结出声音特征如下图所示。
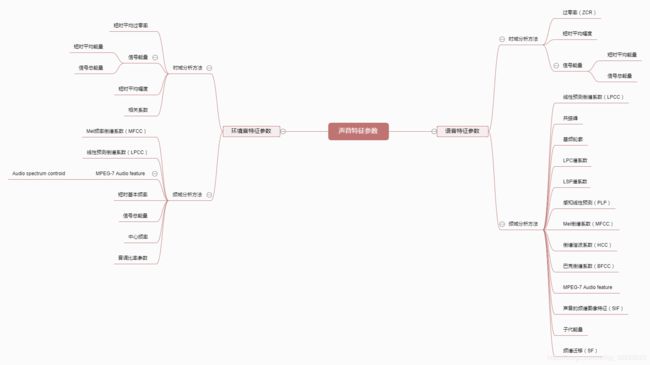
图1.3 声音特征参数
针对语音与环境音两类声音有两套声音特征参数,针对每类声音又分为时域特征和频域特征。
-
分类器
早期的分类器是基于数学模型建立而来的,随着十九世纪数学领域的蓬勃发展,模式识别技术也应运而生,发展到现在模式识别算法主要有高斯混合模型(GMM)、贝叶斯分类法(BayesClassifier)、主成分分析(PCA)、线性判别分析(LDA)、动态时间规划(DTW)、最近邻算法(KNN)、支持向量机(SVM)等算法。模式识别发展至今已经逐步被机器学习所取代,两者的含义有所区别又有重叠,其区别主要在前者是喂给机器各种特征描述,从而让机器对未知的事物进行判断;后者是喂给机器某一事物的海量样本,让机器通过样本来发现特征,最后去判断某些未知的事物。目前机器学习算法根据应用分为回归、分类、聚类,根据学习方式分为有监督学习、无监督学习半监督学习和强化学习,无监督学习算法主要是聚类算法,例如K-means聚类算法、最近邻规则试探法等,常见的监督学习算法有K-近邻算法、决策树、朴素贝叶斯以及近几年特别火的深度学习算法。而对于环境声音检测问题,我们常用机器学习算法是分类算法,在分类算法中监督学习的算法相对来说比较复但是分类性能比较好,在声音图片相关的分类问题中应用比较多。
- 验证实验(采样频率对声音识别的影响)
- 实验目的
本次实验目的根据已有的数据集以及分类算法验证不同声音采样频率对声音识别性能的影响。
- 实验条件
实验所用的声音集采用刘鑫老师提供的玻璃破碎声、枪击声和人的尖叫声各1000条并且不掺杂噪声,每条声音均采用32KHz的采样率以及16位深度编码为wav格式。
用于分类的声音特征采用梅尔倒谱系数(mfcc),其特征包括16维的mfcc系数、16维的一阶差分参数和16维的二阶差分参数。
分类器采用卷积神经网络(cnn),神经网络由两个卷积层、两个池化层以及两个全连接层组成。
- 实验内容及结果
对数据库中的声音进行降采样,分别转化为16KHz采样、8KHz采样、4Khz采样以及1Khz采样,并将这些声音提取mfcc特征输入到cnn分类器中进行训练然后输出测试结果。下表是各种采样率下的识别情况。
表2.3 不同采样频率下的识别率
| 采样率 |
mfcc特征维度 |
识别率 |
损失函数 |
| 32KHz |
(45,48) |
100% |
0.0029 |
| 16KHz |
(45,48) |
95.8% |
0.1981 |
| 8KHz |
(45,48) |
98.3% |
0.0456 |
| 4KHz |
(45,48) |
33.3% |
1.0986 |
| 1KHz |
(45,48) |
33.3% |
1.0986 |
通过上表可以看出声音的采样频率在8KHz以及以上还能保持较高的识别率,低于8KHz后,在4KHz以及1KHz时,识别率为0.333,其分类结果已经变为随机概率分类,无法进行分类。
- 汽车鸣笛声频谱分析
- 声音分析
本次实验用matlab2017a对汽车鸣笛声的频谱进行分析,鸣笛声样本选取自ESC-50声音库以及用韦金泉同志编写的手机录音软件采集的电动车鸣笛声,这两种声音均采用44.1KHz采样频率以及16位量化并保存为wav文件。首先听一下声音库中的汽车鸣笛声和自制软件录的电车鸣笛声。然后分别看一下两者的时域波形和频域波形。
- 手机录制电车鸣笛声
用手机软件录制电车的鸣笛声,其录制采样率为44.1khz,编码位数为16bit。其时域波形和频谱图如下图。

图3.1 电车鸣笛声时域波形

图3.2 电车鸣笛声频谱图
从上面图可以看出来电车鸣笛声的频谱分布范围很广,由于采样频率的限制,其频谱范围只能看到22.05KHz。
-
2.2.1 声音库汽车鸣笛声时频分析
从ESC-50声音库中挑选出一条汽车鸣笛声,利用专业音频编辑软件得知其采样频率为44.1KHz,位深度为16bit,分析其时域和频域如下图。

图3.3 汽车鸣笛声时域波形图
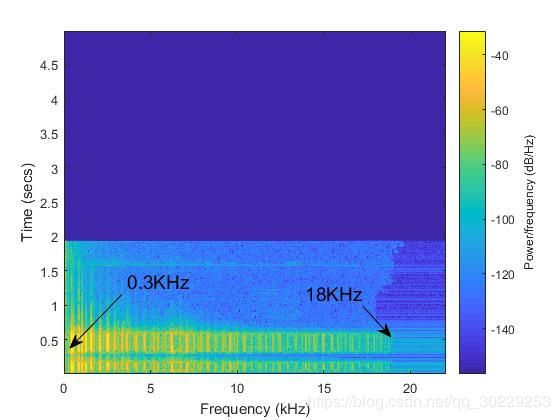
图3.4 汽车鸣笛声能量谱图
从上图中可以看出该汽车鸣笛声频谱范围:0.3KHz~18KHz
-
2.2.2 降采样对音质的影响
本次实验利用专业音乐编辑软件Adobe Audition CC 2018,对汽车鸣笛声进行降采样并分析其时频特性。首先来听一下不同采样频率下的汽车鸣笛声:44.1KHz、32KHz、16KHz、8KHz、4KHz、2KHz、1KHz、800Hz。
2.2.3 降采样为32KHz后时频分析
降采样为32KHz后汽车鸣笛声时域波形图及能量谱图如下图所示。

图3.4 汽车鸣笛声(采样率为32KHz)时域图
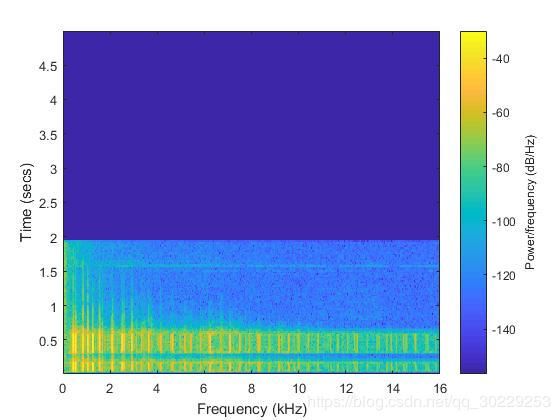
图3.5 汽车鸣笛声(采样率为32KHz)能量谱图
-
2.2.4 降采样为16KHz后时频分析
降采样为16KHz后汽车鸣笛声时域波形图及能量谱图如下图所示。

图3.6 汽车鸣笛声(采样率为16KHz)时域图

图3.7 汽车鸣笛声(采样率为16KHz)能量谱图
-
2.2.5降采样为8KHz后时频分析
降采样为8KHz后汽车鸣笛声时域波形图及能量谱图如下图所示。
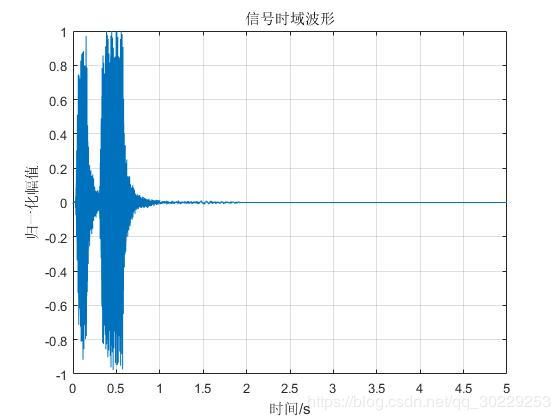
图3.8 汽车鸣笛声(采样率为8KHz)时域图
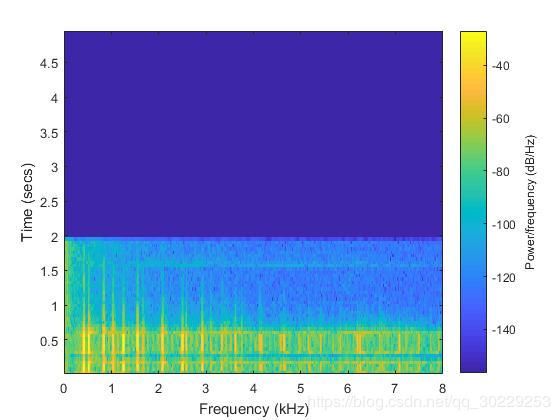
图3.9 汽车鸣笛声(采样率为8KHz)能量谱图
- 总结
通过本次实验可知,对于前端的采集设备,8KHz的采样率就可以达到较高的识别准确率,而且低于8KHz采样的声音丢失的特征过多无法进行识别,综合各个因素考虑,前端采集装置的采样率设置至少是8KHz,采样频率越高,保留下来的特征越多,对识别越有益。
本次实验并不全面,实验用的声音种类较少,且都处于无噪声状态,普适性并不高。
通过对汽车鸣笛声的降采样实验,仅人耳去感受,就能感受到对于不同的采样频率对声音的影响还是挺大的,这也能反映出声音完整度对识别的好处。
(如有错误,望批评指正)