决策树、随机森林、聚类分析
背景
预测新承包商的信用评级,这5个特征指标分别是:
x1 市场份额
x2 客诉率
x3 当年度毛利率
x4 销售收入占实收资本比例
x5 净利润
利用上述五项指标及历史评级结果的821条样本数据开发多分类信用评级模型和聚类模型,如下:
将R语言加载包的网络链接,指向国内镜像,确保网络通畅;
镜像设置加载有2种方式,如下:
A.方法一:代码指定镜像
local({r <- getOption(“repos”)
r[“CRAN”] <- “http://mirrors.aliyun.com/CRAN/”
r[“CRANextra”] <- “http://mirrors.aliyun.com/CRAN/”
options(repos=r)})
B.方法二:手动修改镜像

(2)使用na.omit()命令删除有缺失的数据行;

可见数据无缺失值,删除后数据和原数据保持相同,可以进行下一步分析。
(3)对于读入R语言的附件1数据集,将评级结果grade这一列,利用factor函数转换为有序因子的数据类型。

对数据因子进行有序化后,结果为A

对数据的抽取比例和数据样本分别进行了随机数的设置。

经典决策树模型
(5)利用df1.train训练经典决策树模型,并用df1.validate验证模型准确性。
library(rpart)
set.seed(123456)
dtree <- rpart(grade~.,data = df1.train,method = 'class',
parms = list(split = 'information'))
dtree$cptable #不同大小的树对应的预测误差
plotcp(dtree) #交叉验证误差与复杂度参数的关系图
dtree.pruned <- prune(dtree,cp=0.015) #根据复杂度剪枝,控制树的大小
library(rpart.plot)
prp(dtree.pruned,type = 2, extra = 104,
fallen.leaves = TRUE, main = 'Decision Tree') #画出最终的决策树
dtree.pred <- predict(dtree.pruned,df1.validate,type = 'class')
str(dtree.pred)
dtree.pref <- table(df1.validate$grade,dtree.pred,
dnn = c('Actual','Predicted'))
print(dtree.pref)
结果展示如下:

图 交叉验证误差与复杂度参数的关系
cp=0.015,根据复杂度剪枝,控制树的大小.绘制决策树图形为:

对该决策树模型使用验证集数据进行验证,结果如下:

计算可得验证准确的数据个数有:54+205+31+31=321,总体数据为: 737个。最终准确率为:321/737=43.56%.
推断决策树模型
(6)利用df1.train训练条件推断决策树模型,并用df1.validate验证模型准确性。
#install.packages("party")
library(party) #加载必要包
fit.ctree <- ctree(grade~.,data = df1.train) #生成条件决策树
plot(fit.ctree,main = 'Conditional Inference Tree') #画出决策树
ctree.pred <- predict(fit.ctree,df1.validate,type = 'response') #对验证集分类
ctree.pref <- table(df1.validate$grade,ctree.pred,
dnn = c('Actual','"Predict')) #观察准确率
print(ctree.pref)
执行结果如下:

图 条件推断决策树
对该决策树模型使用验证集数据进行验证,最终预测数据结果为:
计算可得验证准确的数据个数有:0+304+0+31=335,总体数据为: 737个。最终准确率为:335/737=45.45%
随机森林模型
(7)利用df1.train训练随机森林模型,并用df1.validate验证模型准确性。
library(randomForest)
set.seed(123456)
ez.forest <- randomForest(grade~.,data = df1.train,
na.action = na.roughfix, #变量缺失值替换成对应列的中位数
importance = TRUE) #生成森林
print(ez.forest)
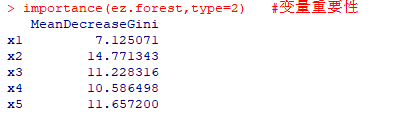
importance(ez.forest,type=2)
#type=2参数得到的某个变量的相对重要性就是分割该变量时节点不纯度的下降总量(所有决策树)取平均(/决策树的数量)
forest.pred <- predict(ez.forest,df1.validate)
forest.perf <- table(df1.validate$grade,forest.pred,
dnn = c('Actual','Predicted'))
print(forest.perf)
执行结果如下:
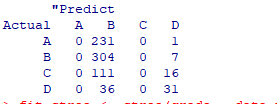
对该决策树模型使用验证集数据进行验证,最终预测数据结果为:

计算可得验证准确的数据个数有:77+224+29+35=365,总体数据为: 737个。最终准确率为:365/737=49.53%
计算上述三个模型在验证集上的预测准确率,并评价哪个模型准确率最高。
综上比较,经典决策树模型最终准确率为:43.56%,条件推断决策树模型最终准确率为:45.45%,随机森林模型最终准确率为:49.53%,选择准确率高的随机森林模型。
聚类分析模型
利用K均值聚类模型对该批数据进行聚类分析。
setwd("C:\\Users\\Administrator\\Desktop\\project")
df2<-read.csv("data2_cluster.csv")
str(df2)
library(factoextra)
df2<-df2[,-1]
b<-scale(df2)
#设置随机种子,保证试验客重复进行
set.seed(1234)
#确定最佳聚类个数,使用组内平方误差和法
fviz_nbclust(b,kmeans,method="wss")+geom_vline(xintercept=4,linetype=2)
#根据最佳聚类个数,进行kmeans聚类
res<-kmeans(b,4)
#将分类结果放入原数据集中
res1<-cbind(df2,res$cluster)
#导出最终结果
write.csv(res1,file='res1.csv')
#查看最终聚类图形
fviz_cluster(res,data=df2)

图:最佳聚类个数判断
这里函数直观给出最佳分类个数:4。因此数据聚成4类。聚类结果图形为:

图: 聚类结果图形