黑马程序员——零基础学习iOS开发——03 c语言基础语法:关键字、标示符、注释、数据结构、变量、变量内存分析、scanf函数
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
一、关键字、标识符、注释
1.关键字
关键字是被赋予了特殊含义,可以触发特殊事件的一组字符。
C语言一共提供了32个关键字,这些关键字都被C语言赋予了特殊含义。
auto double int struct break elselongswitch
case enum register typedef char extern return union
const float short unsigned continue for signed void
default goto sizeof volatile do if while statictips:
看着茫茫多的关键字是不是压力很大?不用担心,这些关键字以后会经常用到的,到时候你想不记住都。关键字的特征:
1> 全部都是小写
2> 在开发工具或者智能文本编辑工具中会显示特殊颜色。默认情况下,C语言中的所有关键字在Xcode中都会显示紫褐色
2.标识符
1) 什么是标示符?
tips:标识符要跟关键字区分开来:关键字是C语言默认提供的符号,标识符是程序员自定义的。
2) 标示符的作用:用来区分我们自定的众多函数、变量名等。(变量后边会学到)
3)标识符的命名
标示符只能用字母、数字、下划线组成,必须由字母开头,不能有标点,不能与关键字一样
tips:
为了保持良好的代码风格,最好遵守以下标识符命名规范:尽量起个有意义的名称,比如一个完整的英文单词,别人一看这个名称就能才能这个标识符的作用。如果标识符中含有多个单词,可以使用驼峰标识(除开第一个单词,后面每个单词的首字母都是大写):firstName、myFirstName,或者使用下划线_来连接:first_name、my_first_name;
4)错误标识符命名示例
| 非法标识符 |
错误点 |
| from#12 |
标识符中不能使用#符号 |
| my-Boolean |
标识符中不能使用“-”符号,应使用下划线“_”代替 |
| 2ndObj |
标识符不能使用数字开头 |
| int |
“int”是关键字 |
| jack&rose |
符号“&”不能出现在标识符中 |
| G.U.I |
标识符内不能出现’.' |
3.注释
1)什么是注释
1>注释是在所有计算机语言中都非常重要的一个概念,从字面上看,就是注解、解释的意思
2>注释可以用来解释某一段程序或者某一行代码是什么意思,方便程序员之间的交流。假如我写完一行代码后,加上相应的注释,那么别人看到这个注释就知道我的这行代码是做什么用的
3>注释可以是任何文字,也就是说可以写中文
4>在开发工具中注释一般是豆沙绿色
2)单行注释
1>单行注释以两个正斜杠开头,也就是以//开头,只能注释一行,从//开始到这行的结尾都是注释的内容
2>任何地方都可以写注释:函数外面、里面,每一条语句后面
int a; //这是一行注释,我定义了一个整型变量a3)多行注释
多行注释以/*开头,以*/结尾,/*和*/中间的内容都是注释
/*
这是一段注释
这是一段注释
这是一段注释
*/4)注释的作用
1> 标注代码的意义,当多人合作开发代码时,便于其他人读懂你的代码
2> 检查代码的作用。注释掉某行代码,然后重新编译执行程序,对比程序结果有什么不同。
3> 排除错误。注释掉某行代码,然后重新编译程序,看程序是否还报相同错误,如果不报错,则问题可能就出在这行代码上。
tips: 当编译程序的时候,并不会将注释编译到.o目标文件中
5)注释的嵌套现象
1) 单行注释可以嵌套单行注释、多行注释
// 哇哈哈 //呵呵呵// /* fsdfsdf */ // sdfsdfsd
2) 多行注释可以嵌套单行注释
/*
// 作者:
// 描述:第一个C语言程序
作用:这是一个主函数,C程序的入口点
*/
/* 哈哈哈
/*嘻嘻嘻*/
呵呵呵 */3) 下面的写法是错误的
// /*
哈哈哈
*/6)注释的重要性
1)要养成写注释的良好习惯。绝大部分项目经理检查下属代码的第一件事就是看有没有写注释,也有很多公司的机试也会检查注释(机试就是给你一道编程题、一台电脑,在规定时间内解题)
2)今天,你写了几百行代码,很高兴,做出了一个非常不错的功能,但是,忘了写注释。一个星期过后,你再回去看那一段代码,你可能完全看不懂了,这是很正常的事。如果你写了注释,那情况就不一样了,注释可以帮助你回顾代码的作用。
3)你在某家公司待了1年多,写了10几万行代码,但是你不写一点注释。有一天你离职了,新的员工接手你做的项目,他首先要做的事情肯定是要读懂你写 的代码。可是你一点注释都没写,10万行代码,全部都是英文,这会让这位新员工非常地蛋疼。每个人都有自己的思想,写代码的思路肯定是不一样的,看别人写 的代码是件非常痛苦的事情,特别是没有注释的代码。你不写注释的做法会大大降低公司的开发效率。因此,所有的正规公司都非常重视注释。二、数据
1.数据分类
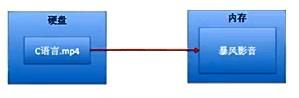
2.数据的大小
3.C语言中的数据类型
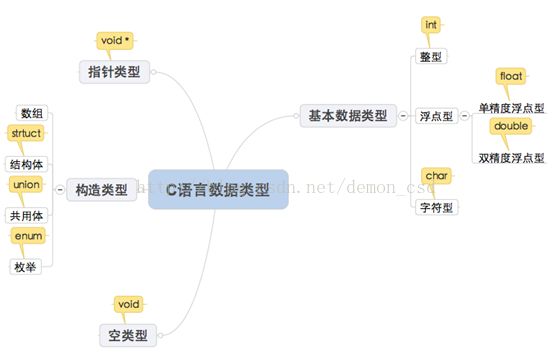
三、常量
1.什么是常量?
常量表示一些固定不变的数据。
2.常量的分类
1> 整型常量(int)
包括了所有的整数,比如6、27、109、256、-10、0、-289等
2> 浮点型常量(float\double)
浮点型常量分为double和float两种数据类型
double:双精度浮点型,其实就是小数。比如5.43、-2.3、0.0等(注意,0.0也算是个小数)
float:单精度浮点型,也是小数,比double的精确程度低,也就是说所能表示的小数位数比较少。为了跟double区分开来,float 型数据都是以f结尾的,比如5.43f、-2.3f、0.0f。需要注意的是,绝对不能有10f这样格式的,编译器会直接报错,只有小数才允许加上f。
3> 字符常量(char)
u 将一个数字(0~9)、英文字母(a~z、A~Z)或者 其他符号(+、-、!、?等)用单引号括起来,这样构成的就是字符常量。比如'6'、'a'、'F'、'+'、'$'等。
注意:单引号只能括住1个字符,而且不能是中文字符,下面的写法是错误的:'abc'、'123456'、'男'
4> 字符串常量
将一个或者多个字符用双引号("")括起来,这样构成的就是字符串常量。比如"6"、"男"、"哇哈哈"、"abcd"、"my_car4",其实printf("Hello World");语句中的"Hello World"就是字符串常量。
那究竟6、'6'、"6"在用法上有什么区别呢?这个先不作讨论,以后会介绍。
3.习题
下面的都是什么类型的常量?
10.6 double(双精度浮点)19.0f float(单精度浮点)
0.0 double
0 int(整形)
‘A’ char(字符)
“男” 字符串
“mj” 字符串
294 int
‘+’ char
四、变量
1.什么是变量
当一个数据的值需要经常改变或者不确定时,就应该用变量来表示。比如游戏积分。
2.定义变量
1> 目的
程序运行中的数据都储存在内存中,定义变量的目的就是为了在内存中分配一块适量的储存空间给变量,以便存储相应的数据。
举个例子:
计算机内存就像停车场,每个变量就像是各种不同尺寸的车子。
你要开进一辆车,首先要有一个空车位才行,定义变量的过程就像是在找一个合适车位。
如果你要开进去一辆公共汽车,就得找一个足够长的车位,数据类型就相当于决定了车的长短,长数据类型需要分配的内存空间要比短数据类型大一些。
每开进停车场一辆车,你就得找到一个合适的车位。如果车位满了,你就没法开新车车子进去了。
2> 格式
变量类型 变量名; 比如 int number;
变量名属于标识符
变量类型:不同类型的变量占用不同大小的存储空间。由于内存极其有限,系统会分配适当的存储空间约束变量所存放的数据类型(方便运算)
3> 实例
int main()
{
int i; // 定义了一个整型变量 i
char c; // 定义了一个字符型变量 c
int a, b; // 定义了一个整型变量a,一个整型变量b
return 0;
}tips:可以在同一行语句中定义两个变量,用逗号隔开
3.变量的使用
1> 赋值
往变量里面存点东西,就是赋值。赋值语句后带个分号;
i = 10;
注意:这里的等号=,并不是数学中的“相等”,而是C语言中的赋值运算符,作用是将右边的常量10赋值给左边的变量i
第一次赋值,可以称为“初始化”
初始化的两种形式
1)先定义,后初始化:
int a;
a = 10;2)定义的同时进行初始化:
int a = 10;2> 修改
可以修改变量的值,多次赋值。每次赋值都会覆盖原来的值
i = 10;
i = 20;变量i最后的值是20。
使用printf输出一个\多个变量的值
int a =10, c = 11;
printf("a=%d,c=%d", a, c); // %d是占位符,输出时,会将a和c的值按顺序填到两个%d中去。不同数据类型输出所用的占位符不一样:%d输出整型十进制,%f输出double或float类型,%c输出char类型
double height =1.55;
char blood ='A';
printf("height=%.2f,血型是%c", height, blood); // f前面的 ".2" 代表输出精确到小数点后两位。简单的加减操作
int a = 10 + 20;
int b = a - 15;
int c = a + b;没有初始化时不要拿来使用(下面的写法是不建议的)
int score;
printf("score=%d", score);3> 变量之间值的传递
// 可以将一个变量的值赋值给另一个变量
int a =10;
int b = a;
// 连续赋值
a = b = 10; 4.常见错误
1> 变量名相同
{ // 在同一个大括号内,不允许定义两个名字相同的变量
int a =10;
int a = 12;
}2> 变量的作用域不对
代码块作用域:变量的作用域是从它被定义开始,一直到它所在的大括号结束。
{
int a =10; // a的作用域从这一行开始
{ // a的作用域涵盖这个大括号
// int a; // 如果这行也定义一个a,那么这个a和第2行的a不是同一个a,
a = 5; // 这一句赋值操作会优先在自己的代码块(大括号)中找定义过的变量a进行赋值,如果自己的代码块没有找到变量a,则像外面一层代码块找,再没有,则再向外找。
}
} // 第2行定义的a的作用域到这里截止
int a; // 这个a和上面大括号中的a不是同一个a 5.习题
1> 交换整型变量a、b的值。比如a=10、b=11;交换之后a的值是11,b的值是10。用两种方式实现:
使用第三方变量
int a = 10, b = 11;
int temp; //定义一个变量temp
temp = a; //这句执行后,temp = a = 10
a = b; //这句执行后,a = b = 11
b = temp; //这句执行后,b = temp = 10不使用第三方变量(这种凑数的方法很少用到,不必纠结,有印象就可以)
int a = 10, b = 11;
a = b - a; // a = 11-10 = 1
b = b - a; // b = 11 - 1 = 10
a = b + a; // a = 10 + 1 = 11五、变量的内存分析
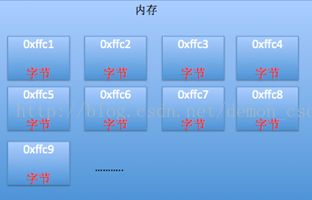
0x表示的是十六进制,不用过于纠结,能看懂这些数字之间谁大谁小就行了
1)所占用字节数跟类型有关,也跟编译器环境有关。
(下表中单位是字节Byte)
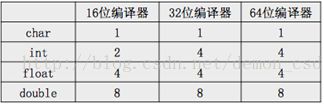
- 内存由大到小寻址,优先分配内存地址较大的字节给变量。b的内存地址比a大
- 每个变量都有地址:第一个字节的地址就是变量的地址
// 我们可以用输出地址的方式验证内存地址的分配是否真的是由大到小
int a;
int b;
int c;
printf("a的内存地址为%p\n",&a);
printf("a的内存地址为%p\n",&b);
printf("a的内存地址为%p\n",&c);4)注意
int a;
printf("a的值是:%d\n", a);
上面的写法是不建议的
六、scanf函数
1.简介
2.简单用法
#include
int main()
{
int age;
scanf("%d", &age);
return 0;
} - scanf函数时,会等待用户的键盘输入,并不会往后执行代码。scanf的第1个参数是"%d",说明要求用户以10进制的形式输入一个整数。这里要注意,scanf的第2个参数传递的不是age变量,而是age变量的地址&age,&是C语言中的一个地址运算符,可以用来获取变量的地址
- 输入完毕后,敲一下回车键,目的是告诉scanf函数我们已经输入完毕了,scanf函数会将输入的值存入age变量的地址,也就相当于完成了给age变量赋值的操作。
3.其他用法
scanf("%d-%d-%d", &a, &b, &c);3个%d之间是用中划线-隔开的,因此我们在每输入一个整数后都必须加个中划线-,比如这样输入10-14-20,不然在给变量赋值的时候会出问题
2)用scanf函数接收3个数值,每个数值之间用空格隔开
scanf("%d %d %d", &a, &b, &c);3个%d之间是用空格隔开的,我们在每输入一个整数后必须输入一个分隔符,分隔符可以是空格、tab、回车
4.注意
int a;
scanf("%d", a); // 这个写法是错误的,应该传入变量a的地址
scanf("%d", &a); //这个写法是正确的5.习题
#include
int main()
{
// 1.定义2个变量,保存用户输入的整数
int num1, num2;
// 2.提示用户输入第1个整数
printf("请输入第1个整数:\n");
// 3.接收用户输入的第1个整数
scanf("%d", &num1);
// 4.提示用户输入第2个整数
printf("请输入第2个整数:\n");
// 5.接收用户输入的第2个整数
scanf("%d", &num2);
// 6.计算和,并且输出
int sum = num1 + num2;
printf("%d+%d=%d\n", num1, num2, sum);
//printf("num1=%d, num2=%d\n", num1, num2);
return 0;
} 小结:
1.注释无论是对自己回顾知识,还是对多人开发,都很重要,要重视。
2.系统从后向前给变量分配内存地址。
3.注意scanf函数中不能接收\n 否则会导致无法退出scanf函数。
4.注意tips