Matlab 图像分割 (阈值处理)
图像分割
图像处理中很重要的概念就是图像分割,在很多应用都需要图像分割的处理,例如产品检测,目标识别,匹配等。图像分割的概念,我之前在其他博客中描述过,分割:就是在一幅图像中,提取出感兴趣区域的过程。主要有四种方法。分别是边缘检测,阈值处理,基于区域的分割,还有其他的分割方法。
边缘检测,是基于灰度突变或者渐变来检测边缘的。边缘检测模型氛围三类,
分别是台阶模型,斜坡模型和屋顶边缘模型。
或者大多数主要针对前后两类,详细见图。
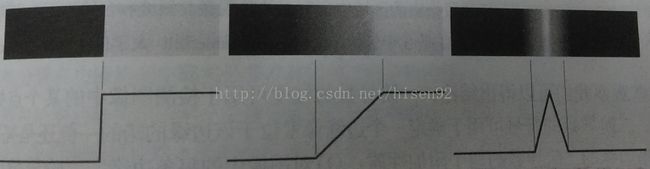
对边缘的特性,有两个属性来表示,分别是梯度幅值和梯度方向。这涉及到偏微分,实际应用过程中,使用差分来近似的。所以边缘检测可以近似认为,用一个定义的模板,来对图像进行滤波的过程,之后,可以适当的使用简单全局阈值处理。下面介绍一下各种检测算子及其功能。
简单的算子
Roberts 算子,定义一个2x2的模板,如下图。

Prewitt 算子,定义一个3x3的模板,如下图

Sobel算子,定义一个3x3的模板,和Prewitt相似,就是在中心系数上加了权值。
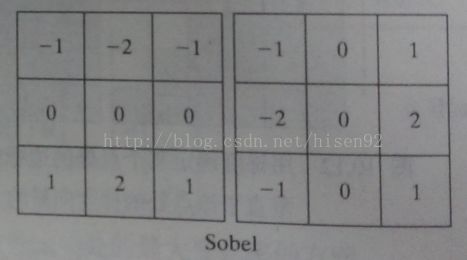
在这些模板中,所有系数和必须为零,因为必须保证对灰度均匀区域,响应为0。
较复杂的边缘检测技术,考虑到了图像噪声和图边缘本身的性质。有:
LoG(高斯拉普拉斯),Canny(坎尼)算子。
LoG算子(高斯拉普拉斯),对于高斯,我们第一印象是去噪,对于拉普拉斯,是边缘检测。两者结合,达到很好的效果。由LoG滤波器与图像卷积,在寻找零交叉来确定边缘的位置。在数学上,等效于先用高斯滤波器平滑图像,然后据算结果的拉普拉斯,最后寻找零交叉位置,确定边缘位置。
Canny算子(坎尼),是边缘检测效果比较好的检测器。基本思想是:先用高斯滤波器平滑图像,然后计算图像的梯度幅值和梯度方向矩阵,再对梯度幅值图像应用非最大抑制,最后用双阈值处理和连接分析来检测并连接边缘。这里涉及到非最大抑制概念。这里主要分析这个概念。
非最大抑制,主要为了细化边缘,Matlab给出的方案是:
1:寻找最接近每点(x,y)的梯度方向d
k
.
2: 如果M(x,y)的值至少小于沿
d
k
的两个邻居之一,则令该点的梯度幅值置为0.(抑制非最大值);否则,令该点幅值不变。
3:进行双阈值处理,减少伪边缘。

定义的四种边缘类型d
1
,d
2
,d
3
,d
4.
相对比3x3的模板,当确定的(x,y)的梯度方向位于四种边缘任意一种,这将该点的梯度幅值和其他所谓的相邻的梯度幅值比较,如果出现小于其中一个的,这非最大抑制,置为0。
阈值处理,可以简单的理解为二值化处理,分为全局阈值和可变阈值处理(局部阈值或区域阈值,自适应阈值)。
基本的全局阈值处理,有主要有以下几种:
1:简单的全局阈值。定义一个(Static threshold )T来处理图像灰度0-1.
2:迭代求阈值(iteration threshold)T来处理图像。具体过程是:1:预先定义一个初始阈值T
0
(一般定义为全局灰度均值)和迭代终止参数T4,
2:将图像像素分为两组:G1(像素值大于T
0)
,和G2(像素值小于等于T
0)
3:对G1,G2分别计算平均灰度值m
1
,m2
. 4:计算新的阈值T
1=(
m
1+
m
2)
/2.重复步骤2到4,迭代直到相邻T值间的差小于T
4.
3:最大类间方差法:又称为OTSU的最佳
全局
阈值处理,就是要让两组像素集合的方差达到最大,此时的阈值为最佳的。
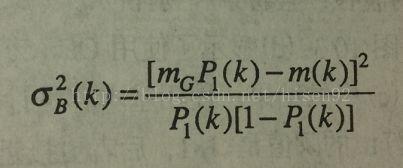

从而得到使类间方差最大的阈值k*.
4:用图像平滑去噪后,再采取合适的全局阈值。
5:用边缘改进后,再采取合适的全局阈值。具体过程是:1:计算一幅边缘图像G,可以是f(x,y)梯度的幅值或者拉普拉斯的绝对值。2:指定一个阈值T。3:用阈值T对图像G进行阈值处理,产生一幅二值图像g
T
(x,y)。4:仅用f(x,y)中对应于
g
T
(x,y)中像素值为1的位置的像素计算直方图。5:使用步骤4的直方图全局的分割f(x,y).
可变阈值处理(可叫做自适应阈值处理),主要有两种。基于局部图像特性的可变阈值处理,和使用移动平均的可变阈值处理。
1:基于局部图像特性的可变阈值处理, 就是考虑每个像素点的邻域像素来确定每个像素点相应的阈值,而标准差和均值可以局部确定邻域内像素阈值,计算公式为:

2:使用移动平均的可变阈值处理,基本思想是以一幅图像的扫描行计算移动平均为基础的。计算公式如下:

其中n为计算平均的点数,z
k+1
为步骤中扫描序列中遇到的点的灰度。
最终的阈值T=bm
xy
,其中b为常数。
使用移动平均的可变阈值处理,对很多对比度差的图像处理效果可以很好,但相应的程序代码的编写却很羞涩,难懂。
function g = movingthresh(f, n, K)
%MOVINGTHRESH Image segmentation using a moving average threshold.
% G = MOVINGTHRESH(F, n, K) segments image F by thresholding its
% intensities based on the moving average of the intensities along
% individual rows of the image. The average at pixel k is formed
% by averaging the intensities of that pixel and its n − 1
% preceding neighbors. To reduce shading bias, the scanning is
% done in a zig-zag manner, treating the pixels as if they were a
% 1-D, continuous stream. If the value of the image at a point
% exceeds K percent of the value of the running average at that
% point, a 1 is output in that location in G. Otherwise a 0 is
% output. At the end of the procedure, G is thus the thresholded
% (segmented) image. K must be a scalar in the range [0, 1].
% Preliminaries.
% || means or operator;rem(n,1) means the residual of n/1
f = tofloat(f);
[M, N] = size(f);
if (n < 1) || (rem(n, 1) ~= 0)
error('n must be an integer >= 1.')
end
if K < 0 || K > 1
error('K must be a fraction in the range [0, 1].')
end
% Flip every other row of f to produce the equivalent of a zig-zag scanning pattern. Convert image to a vector.
f(2:2:end, :) = fliplr(f(2:2:end, :)); %fliplr realize the overturn of the vector
f = f'; % Still a matrix.
f = f(:)'; % Convert to row vector for use in function filter.
% Compute the moving average.
maf = ones(1, n)/n; % The 1-D moving average filter.
ma = filter(maf, 1, f); % Computation of moving average.
% Perform thresholding.
g = (f > K * ma);
% Go back to image format (indexed subscripts).
g = reshape(g, N, M)';
% Flip alternate(交替的) rows back.
g(2:2:end, :) = fliplr(g(2:2:end, :));
基于区域的分割:这是一种直接对区域处理的分割方法,不同于阈值处理和边缘提取,其中边缘提取是基于寻找灰度值不连续的。阈值处理,是基于像素分布的特性。基于区域的分割,分两类,一类是区域生长(Region Growing),另一类是区域的聚合和分裂(Region Merging and Splitting).
区域生长,基本思想是从一组”种子“点开始,将与种子点预先定义的性质相似的那些邻域像素添加到每个种子上来形成生长区域。需要注意的是,种子点的选取,一般从原图像中经过全局阈值,然后腐蚀,从而确定一组种子点的。其二,性质相似,一般选取灰度值相近。
区域分裂和聚合,基本思想是将一幅图像细分为一组任意的不相交的区域,然后聚合或者分裂这些区域。类似与四叉树原理来分裂和聚合。
疑惑:对几种分割思想的实现代码,理解还不太清楚。