Python爬取豆瓣电影Top250
想学Python了,花了一下午的时间把Python基础点学了下,发现什么都不会,不知道能干啥,想这做个小Demo,正好看到了一篇文章于是就有了下面的想法。那篇文章给了启发,谢谢博主。
豆瓣电影Top250就是这个网页,我想把他整个的爬下来。
如果有其他的语言的开发经验,就会发现,这就是一个网络请求,比如说Java,就是请求这个页面,然后通过打印即可。不过我听说好像有个就 requests 的第三方库挺不错的。用一下。
import requests
douban = 'https://movie.douban.com/top250'
def download():
content = requests.get(douban).content
print(content)
def main():
download()
if __name__ == '__main__':
main()
恩,上面这个就是一个简单的下载豆瓣电影Top250的一个页面,可是打印出来好像没有转码一样,汉字没了,没关系,听过bs4可以用来解析网页,试一下。
def parseHtml(html):
soup = BeautifulSoup(html)
print(soup)
def download():
content = requests.get(douban).content
parseHtml(content)

这样就算是爬下来了,不过,我要这个没什么用啊,我想要的是Top250,有哪些电影,评分都是多少。
可是在哪?
我想到了F12,在豆瓣电影Top250按下F12,找到电影名所在的控件名,然后获取下来,同样的,找到评分控件名,然后获取。
恩,找到了,电影名在一个class=hd的div中的a标签下的第一个class名为title标签。
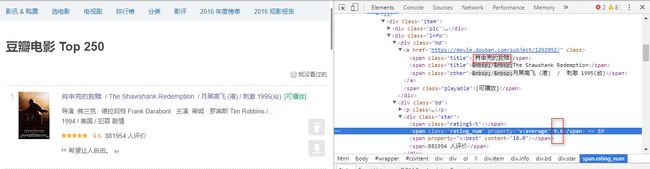
movie_name = soup.find('span', attrs={'class': 'title'}).getText()
print(movie_name)
这样应该就行了吧,试试看,结果只有一个《肖申克的救赎》,嗯,差得不远,第一个出来了,哪其他的呢。仔细看看

好像有好多的li标签,这些都是在一个 class=gird_view 的ol里的,那是不是构成了一个类似与数组的样式,那应该是先获取那个数组,然后再遍历寻找电影名,对吧。
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
for movie_li in movie_list_soup.find_all('li'):
movie_name = movie_li.find('span', attrs={'class': 'title'}).getText()
print(movie_name)
同样的,获取评分也就没有问题了。唉,那个,每个电影好像有个推荐语,顺便也搞下来吧,反正也不费什么力气。
def parseHtml(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
for movie_li in movie_list_soup.find_all('li'):
movie_name = movie_li.find('span', attrs={'class': 'title'}).getText()
movie_star = movie_li.find('span', attrs={'class': 'rating_num'}).getText()
movieQuote = movie_li.find('span', attrs={'class': 'inq'}).getText()
print('{0} {1} {2}'.format(movie_name, movie_star, movieQuote))

这样就完了?这才第一页,我想把所有的都搞下来,那继续吧,怎么做呢,当我把页面拉到最下面的时候,发现一页一共是25个电影那一共就有10页,那我把页码包含的地址搞下来,然后构成一个循环,剩下的就是和上面一样的结果了。等等,好像有个后页,更简单了,我每次爬取的时候顺便把后页的地址爬取下来,然后再继续刚才的就行了。
不过好像要注意一点就是,如果抓取的本身就是最后一页,那肯定没有后页了,所以要判断有没有后页才能继续,如果有继续爬取,如果没有就是在最后一页了,就退出好了。
nextPage = soup.find('span', attrs={'class': 'next'}).find('a')
if nextPage:
download(download(douban + '{0}'.format(nextPage['href'])))
else:
exit(0)
不过,我们需要改一下了,把之前的download函数添加一个参数,放进去一个url。
def download(url):
content = requests.get(url).content
parseHtml(content)
def main():
download(douban)

这是什么情况,没道理啊。
仔细看看,说什么找不到getText()这个属性,什么鬼,哪里有问题,提示是获取推荐语出现了问题,不对,那怎么之前还有推荐语呢?找到了这个在《玩具总动员3》下面出现了问题,找找看,这个电影是在哪一页,下面一部电影是什么?
还好,我们刚才传入一个url,我把url打印一下,不就知道了?,最后一个打印的url是这个打开找到《玩具总动员3》下面那个,《二十二》这个好像没有推荐语,那怎么办?
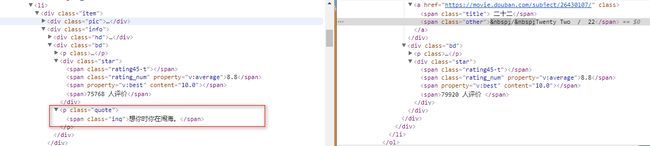
仔细看一下,发现,这个电影比其他电影少了一个p标签,正好是放推荐语的,那我先判断p标签是否存在,再去找推荐语吧。嗯,就这么改。
好了,整体搞完了,总体看一下代码。
import requests
from bs4 import BeautifulSoup
douban = 'https://movie.douban.com/top250'
def parseHtml(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
for movie_li in movie_list_soup.find_all('li'):
movie_name = movie_li.find('span', attrs={'class': 'title'}).getText()
movie_star = movie_li.find('span', attrs={'class': 'rating_num'}).getText()
quoteP = movie_li.find('p', attrs={'class': 'quote'})
if quoteP:
movieQuote = movie_li.find('span', attrs={'class': 'inq'}).getText()
print('{0} {1} {2}'.format(movie_name, movie_star, movieQuote))
else:
print('{0} {1}'.format(movie_name, movie_star))
nextPage = soup.find('span', attrs={'class': 'next'}).find('a')
if nextPage:
download(download(douban + '{0}'.format(nextPage['href'])))
else:
exit(0)
def download(url):
print(url)
content = requests.get(url).content
parseHtml(content)
def main():
download(douban)
if __name__ == '__main__':
main()