《Python数据科学手册》 机器学习之模型验证——基于Scikit-Learn
《Python数据科学手册》 笔记
一、超参数
在模型拟合数据之前必须确定好的参数。
二、交叉验证
将模型分为N组,每一轮依次用模型拟合其中的 N-1 组数据,再预测剩下一组数据,评估模型准确率。
以五轮交叉验证为例:

用函数实现:

这是在我上一篇博客代码的基础上添加的,单独这两行代码是要报错的哦!(上一篇博客)
其中,model是实例化的一个模型(只需要初始化即可),X_iris是未手动分组的鸢尾花特征矩阵,y_iris是未手动分组的鸢尾花标签数组,cv=5表示要进行5轮交叉验证。
需要注意的是,model_selection模块在Scikit-Learn 0.18版之前是用的cross_validation。
另外有一种极端的情况,那就是每次只有一个样本做测试,其他样本全用于训练。这种交叉验证类型被称为LOO(leave-one-out)交叉验证。
用函数实现:
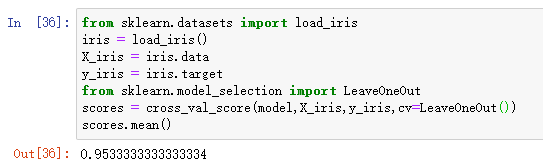
需要注意的是,从model_selection模块中导入的LeaveOneOut和低版本Scikit-Learn(Scikit-Learn 0.18版之前)里的cross_validation模块中导入的LeaveOneOut用法不同,前者为cv=LeaveOneOut(),而后者为cv=LeaveOneOut(len(X_iris))。
三、选择最优模型
假如模型效果不好,可以从以下几个方面进行改善:
①用更复杂/更灵活的模型
②用更简单/更确定的模型
③采集更多的训练样本
④为每个样本采集更多的特征
但是选择哪一种方案进行改善却不是件随便的事,有时候换一种复杂的模型有可能产生更差的结果,增加更多的训练样本也未必能改善性能。因此,改善模型的能力,是机器学习实践者需要努力培养的重要能力。Scikit-Learn中自带验证曲线(validation_curve)和学习曲线(learning_curve),可供我们探究某一类模型得分与其复杂度和训练数据集规模的关系。接下来对模型的选择进行稍微细致的分析。
1. 偏差与方差的均衡
“最优模型”的问题可以看成是找出偏差与方差平衡点的问题。
具有高偏差的模型被认为是对数据欠拟合,模型在验证集的表现与在训练及的表现类似;
具有高方差的模型被认为是对数据过拟合,模型在验证集的表现远不如在训练集的表现。
2.Scikit-Learn验证曲线
验证曲线表现的是模型得分与模型复杂度的关系
模型的训练得分和验证得分一般按照以下趋势发展:
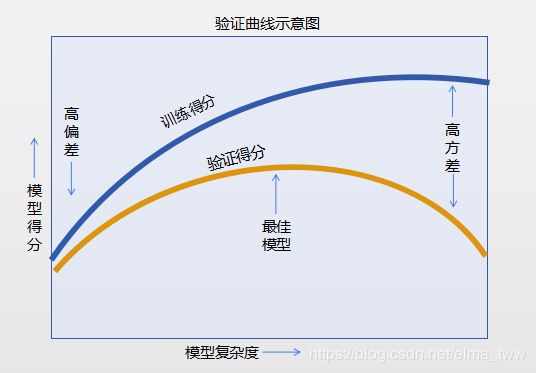
从中可以得出:
①训练得分肯定高于验证得分
②使用复杂度较低的模型(高偏差)时,训练数据往往欠拟合(模型对训练数据和新数据都缺乏预测能力)
③使用复杂度较高的模型(高方差)时,训练数据往往过拟合(模型对训练数据预测能力强,但是对新数据预测能力差)
④当使用复杂度适中的模型时,验证曲线得分最高(偏差与方差达到均衡)
以一个带多项式预处理器的简单线性回归模型为例,可视化验证曲线,代码如下:
-
import numpy
as np
-
import pandas
as pd
-
import matplotlib.pyplot
as plt
-
from sklearn.preprocessing
import PolynomialFeatures
-
from sklearn.linear_model
import LinearRegression
-
from sklearn.pipeline
import make_pipeline
-
import seaborn ;seaborn.set()
#设置图形样式
-
-
#定义模型
-
def PolynomialRegression(degree=2,**kwargs):
-
return make_pipeline(PolynomialFeatures(degree),LinearRegression(**kwargs))
-
#产生数据
-
def make_data(N,err=1.0,rseed=1):
-
rng = np.random.RandomState(rseed)
-
X = rng.rand(N,
1)**
2
-
y =
10 -
1./(X.ravel() +
0.1)
-
if err >
0:
-
y += err * rng.randn(N)
-
return X,y
-
X,y = make_data(
40)
-
-
#导入验证曲线
-
from sklearn.model_selection
import validation_curve
-
degree = np.arange(
0,
21)
#验证范围(多项式0阶到20阶)
-
train_score,val_score = validation_curve(PolynomialRegression(),X,y,
'polynomialfeatures__degree',degree,cv=
7)
-
#设置绘图样式
-
plt.plot(degree,np.median(train_score,
1),color=
'blue', label=
'training score')
-
plt.plot(degree,np.median(val_score,
1),color=
'red',label=
'validation score')
-
plt.legend(loc=
'best')
-
plt.ylim(
0,
1)
-
plt.xlabel(
'degree')
-
plt.ylabel(
'score')
需要注意的是,validation_curve在Scikit-Learn 0.18版之前是放在learning_curve模块中的,即需要将
from sklearn.model_selection import validation_curve
换为:
from sklearn.learning_curve import validation_curve
另外,注意'polynomialfeatures__degree'中间是两个下划线
运行结果如下:
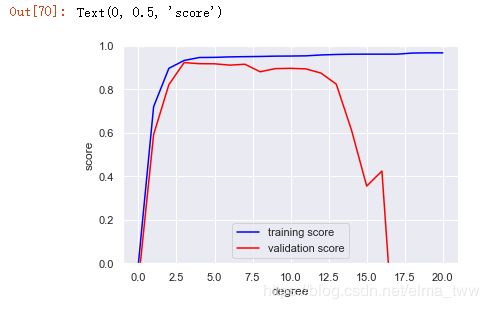
从图中可以得出如下结论:
①训练得分总是比验证得分高
②训练得分随着模型复杂度的提升而单调递增
③验证得分增长到最高点后由于过拟合而开始骤降
③(此例中)偏差与方差均衡性最好的是三次多项式
3.Scikit-Learn学习曲线
学习曲线表现的是模型得分与训练数据集规模的关系
模型的训练得分和验证得分一般按照以下趋势发展:
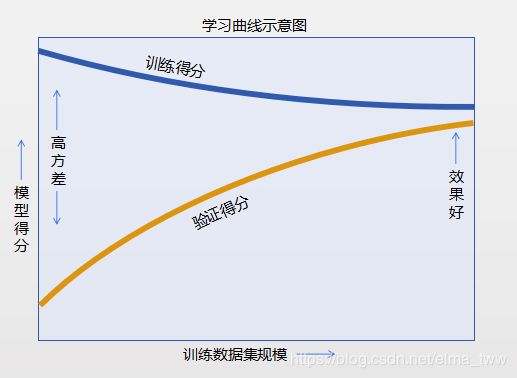
从中可以得出:
①特定复杂度的模型对较小的数据集容易过拟合(训练得分高,验证得分低)
②特定复杂度的模型对较大的数据集容易欠拟合(随着数据的增大,训练得分不断降低,验证得分不断升高)
③模型的验证集得分永远不会高于训练集得分(两条曲线一直在靠近,但永远不会交叉)
④随着训练样本数量的增加,分数会收敛到定值
和可视化验证曲线相同,以一个带多项式预处理器的简单线性回归模型为例,可视化学习曲线,代码如下:
-
from sklearn.model_selection
import learning_curve
-
fig,ax = plt.subplots(
1,
3,figsize=(
15,
5))
-
for i,degree
in enumerate([
2,
4,
9]):
-
N,train_lc,val_lc = learning_curve(PolynomialRegression(degree),X,y,cv=
7,train_sizes=np.linspace(
0.3,
1,
25))
-
ax[i].plot(N,np.mean(train_lc,
1),color=
'blue',label=
'training score')
-
ax[i].plot(N,np.mean(val_lc,
1),color=
'red',label=
'validation score')
-
ax[i].hlines(np.mean([train_lc[
-1],val_lc[
-1]]),N[
0],N[
-1],color=
'gray',linestyle=
'dashed')
-
ax[i].set_ylim(
0,
1)
-
ax[i].set_xlim(N[
0],N[
-1])
-
ax[i].set_xlabel(
'training size')
-
ax[i].set_ylabel(
'score')
-
ax[i].set_title(
'degree={0}'.format(degree),size=
14)
-
ax[i].legend(loc=
'best')
注意,learning_curve在Scikit-Learn 0.18版之前是放在learning_curve模块中的,即需要将
from sklearn.model_selection import learning_curve
替换为
from sklearn.learning_curve import learning_curve
运行结果如下: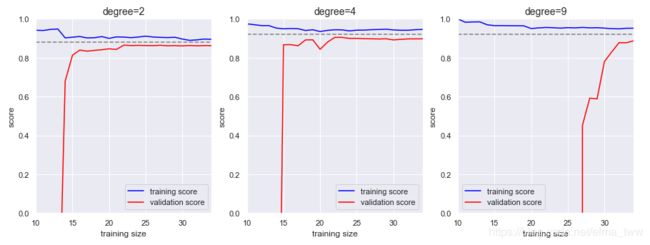
从图中可以得出如下结论:
(选取三个子图中的任意一图观察)当学习曲线已经收敛是(即训练曲线和验证曲线已经贴合在一起),再增加训练数据也不能再显著改善拟合效果,这时候,提高收敛的唯一办法就是换模型,通常是换更复杂的模型(图1,图2,图3的收敛值(虚线)逐渐增大)。
4.网格搜索
从以上的探索可以看出,模型得分和模型的复杂度以及训练集的大小有关,如何找到最优的模型?Scikit-Learn的grid_search模块提供了一个自动化工具解决这个问题。
例如要用网格搜索寻找最优多项式回归模型,我们可以在模型特征的三维网格中寻找最优值——包括多项式的次数的搜索范围、回归模型是否拟合斜距,以及回归模型是否需要进行标准化处理。