中文版详解gensim中的FastText模块(官方文档翻译)
引文
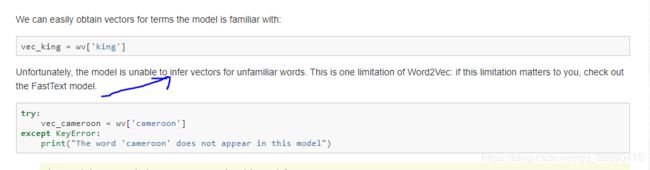
众所周知,在进行文本相似度分析时,我们可以用到gensim中的word2vec来构建词向量以描述词语之间的矢量关系从而实现相似度的计算。但是word2vec有一个很大的局限性,那就是该模型无法推断出不熟悉的单词的向量。如果这个限制了你的装逼,那就请查看FastText模型(官网也是这么说的)。
什么时候使用FastText
FastText背后的主要原理是,单词的词法结构会携带有关单词含义的重要信息,而传统的单词嵌入并不会考虑这些信息,传统的单词嵌入会为每个单词训练一个唯一的单词嵌入。这对于形态丰富的语言(德语,土耳其语)尤其重要,在这种语言中,单个单词可能具有大量的形态形式,每种形态形式很少出现,因此很难训练良好的词嵌入。
FastText尝试通过将每个单词视为其子单词的集合来解决此问题。为了简单和独立于语言,将子词视为该词的字符n-gram(n元)。一个单词的向量被简单地认为是其组成特征图的所有向量之和。
根据此笔记中Word2Vec和FastText的详细比较,与原始Word2Vec相比,FastText在语法任务上的表现要好得多,尤其是在训练语料库较小的情况下。在语义任务上,Word2Vec的性能略优于FastText。随着训练语料库大小的增加,差异变得越来越小。
FastText的训练时间明显长于Word2Vec的Gensim版本(15min 42s vs 6min 42s on text8, 17 mil tokens, 5 epochs, and a vector size of 100)。
如果训练数据中至少有一个字符,则可以通过总结其组成部分字符的向量,来获取词汇外(OOV)单词的向量。
训练模型
对于下面的例子,我们将使用LeeCorpus(如果您已经安装了gensim)来训练我们的模型。
from pprint import pprint as print
from gensim.models.fasttext import FastText as FT_gensim
from gensim.test.utils import datapath
# Set file names for train and test data
corpus_file = datapath('lee_background.cor')
model = FT_gensim(size=100)
# build the vocabulary
model.build_vocab(corpus_file=corpus_file)
# train the model
model.train(
corpus_file=corpus_file, epochs=model.epochs,
total_examples=model.corpus_count, total_words=model.corpus_total_words
)
print(model)Out:
训练超参数
用于训练模型的超参数与word2vec遵循相同的模式。FastText支持原始word2vec中的下列参数:
- model: 训练架构. (允许的值: cbow, skipgram (默认 cbow)
- size: 需要学习的嵌入的大小 (默认 100)
- alpha: 初始学习率 (默认 0.025)
- window: 上下文窗口大小 (默认 5)
- min_count: 忽略出现次数小于某个值的单词 (默认 5)
- loss: 训练目标. (允许的值: ns, hs, softmax (默认 ns)
- sample: 高频词的下采样阈值 (默认 0.001)
- negative: 要抽样的否定词数, for ns (默认 5)
- iter: epochs的数量 (默认 5)
- sorted_vocab: 按下降频率排序的单词 (默认 1)
- threads: 使用的线程数量 (默认 12)
此外, FastText 还有3个额外参数:
- min_n: char ngrams的最小长度 (默认 3)
- max_n: char ngrams的最大长度 (默认 6)
- bucket: 用于散列ngrams的buckets数量 (默认 200000
参数min_n和max_n控制每个单词在训练和查找嵌入时分解成的字符字符图的长度。如果max_n设置为0,或者小于min_n,则不使用字符ngrams,该模型有效地简化为Word2Vec。
为了限制所训练模型的内存需求,使用了一个哈希函数,该函数将ngrams映射到1到k中的整数。为了散列这些字符序列,使用了 Fowler-Noll-Vo hashing function (FNV-1a variant)
注意: 与Word2Vec一样,可以在使用Gensim的FastText本地实现的同时继续训练你的模型。
保存/加载模型
模型可通过load和save方法加载或保存。
# saving a model trained via Gensim's fastText implementation
import tempfile
import os
with tempfile.NamedTemporaryFile(prefix='saved_model_gensim-', delete=False) as tmp:
model.save(tmp.name, separately=[])
loaded_model = FT_gensim.load(tmp.name)
print(loaded_model)
os.unlink(tmp.name)Out:
save_word2vec_method方法会导致ngram的向量丢失。因此,以这种方式加载的模型将表现为一个普通的word2vec模型。
词向量查找
注意:像词向量查找和相似度查询这样的操作可以以完全相同的方法执行。因此,在这里只使用本地的FastText来实现。
FastText模型通过总结属于单词的字符ngram来支持这些单词以外单词的向量查找。
print('night' in model.wv.vocab)Out:
True
print('nights' in model.wv.vocab)Out:
False
print(model['night'])Out:
array([ 0.09290078, 0.00179044, -0.5732425 , 0.47277036, 0.59876233,
-0.31260246, -0.18675974, -0.03937651, 0.42742983, 0.3419642 ,
-0.6347907 , -0.01129783, -0.6731092 , 0.40949872, 0.27855358,
-0.0675667 , -0.19392972, 0.17853093, 0.24443033, -0.37596267,
-0.23575999, 0.27301458, -0.36870447, 0.02350322, -0.8377813 ,
0.7330566 , 0.11465224, 0.17489424, 0.4105659 , 0.00782498,
-0.6537432 , 0.23468146, 0.0849599 , -0.4827836 , 0.46601945,
0.10883024, -0.16093193, -0.0672544 , 0.4203116 , 0.21155815,
-0.00366337, -0.0748013 , 0.3834724 , -0.06503348, 0.12586932,
0.1853084 , -0.1237317 , 0.20932904, -0.01647663, -0.3908304 ,
-0.5708807 , -0.5556746 , 0.06411647, 0.0105149 , 0.3988393 ,
-0.8015626 , -0.1093765 , -0.18021879, 0.01527423, -0.03230731,
0.21715961, -0.12600328, -0.48359045, -0.10510948, -0.5346136 ,
0.34130558, 0.00175925, 0.15395461, 0.03269634, 0.4691867 ,
-0.5634196 , -0.51715475, -0.01452069, -0.11632308, -0.33402348,
0.03678156, 0.2714943 , 0.11561721, -0.13655168, 0.18497233,
0.44912726, 0.05588026, -0.16958544, 0.4569073 , -0.38961336,
-0.25632814, 0.11925202, 0.29190361, 0.3145572 , 0.28840527,
-0.1761603 , 0.11538666, -0.03718378, -0.19138913, -0.2689859 ,
0.55656165, 0.28513685, 0.44856617, 0.5552184 , 0.46507034],
dtype=float32)
print(model['nights'])Out:
array([ 0.08160479, 0.00211581, -0.49826992, 0.41022694, 0.5195688 ,
-0.27314973, -0.1630029 , -0.03343058, 0.3712295 , 0.29791382,
-0.55389863, -0.01124268, -0.5853901 , 0.35737413, 0.2381446 ,
-0.05847026, -0.17071408, 0.15347946, 0.21084373, -0.32725066,
-0.20492734, 0.23824975, -0.3212196 , 0.02110198, -0.728978 ,
0.6370283 , 0.09962698, 0.15249957, 0.35706517, 0.00637152,
-0.5662229 , 0.20523196, 0.07256062, -0.4219087 , 0.40503132,
0.09435709, -0.13849337, -0.05977419, 0.36544353, 0.1847734 ,
-0.00228304, -0.06519727, 0.33295807, -0.05484347, 0.10837447,
0.16139933, -0.11116385, 0.18381876, -0.01496008, -0.33843184,
-0.49896452, -0.48239845, 0.05691842, 0.01010948, 0.3474576 ,
-0.69720525, -0.09521793, -0.15558553, 0.01095809, -0.02779314,
0.18840933, -0.11044046, -0.42034045, -0.09200079, -0.46539423,
0.29623416, 0.00164192, 0.1337628 , 0.0301894 , 0.40878546,
-0.48996508, -0.4493049 , -0.01268086, -0.10204876, -0.2902913 ,
0.03117974, 0.23619917, 0.10075174, -0.11683178, 0.1600669 ,
0.39141724, 0.04842569, -0.14833327, 0.39648855, -0.33779994,
-0.22229995, 0.10574951, 0.25514117, 0.2729022 , 0.25152075,
-0.15353616, 0.10010949, -0.03372021, -0.1661839 , -0.2337282 ,
0.484296 , 0.24699508, 0.38859773, 0.48236763, 0.40448022],
dtype=float32)in 操作与原来的word2vec略有不同。它测试给定单词的向量是否存在,而不是该单词是否存在于单词词汇表中。
测试 word 是否存在于词汇中:
print("word" in model.wv.vocab)Out:
False
测试 是否存在 word 向量:
print("word" in model)Out:
True
相似度运算
相似度运算操作的工作方式与word2vec相同。词汇外的单词也可以使用,只要训练数据中至少有一个字符ngram。
print("nights" in model.wv.vocab)Out:
False
print("night" in model.wv.vocab)Out:
True
print(model.similarity("night", "nights"))Out:
0.9999927在FastText模型中,语法相似的词通常具有很高的相似性,因为大量的组件char-ngram将是相同的。因此,FastText通常在句法任务上比word2vec做得更好。这里提供了一个详细的比较。
其他相似度运算
print(model.most_similar("nights"))Out:
[('Arafat', 0.9982752203941345),
('study', 0.9982697367668152),
('"That', 0.9982694983482361),
('boat', 0.9982693791389465),
('Arafat,', 0.9982683062553406),
('Endeavour', 0.9982543587684631),
('often', 0.9982521533966064),
("Arafat's", 0.9982460737228394),
('details', 0.9982452392578125),
('north.', 0.9982450008392334)]
print(model.n_similarity(['sushi', 'shop'], ['japanese', 'restaurant']))Out:
0.99995166
print(model.doesnt_match("breakfast cereal dinner lunch".split()))Out:
/Volumes/work/workspace/gensim_misha/gensim/models/keyedvectors.py:877: FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future.
vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
'breakfast'
print(model.most_similar(positive=['baghdad', 'england'], negative=['london']))Out:
[('1', 0.2434064894914627),
('40', 0.23903147876262665),
('2', 0.2356666624546051),
('20', 0.2340335100889206),
('26', 0.23390895128250122),
('blaze', 0.23327460885047913),
('UN', 0.2332388311624527),
('keep', 0.23248346149921417),
('As', 0.2321406602859497),
('...', 0.23206500709056854)]
print(model.accuracy(questions=datapath('questions-words.txt')))
Out:
[{'correct': [], 'incorrect': [], 'section': 'capital-common-countries'},
{'correct': [], 'incorrect': [], 'section': 'capital-world'},
{'correct': [], 'incorrect': [], 'section': 'currency'},
{'correct': [], 'incorrect': [], 'section': 'city-in-state'},
{'correct': [],
'incorrect': [('HE', 'SHE', 'HIS', 'HER'), ('HIS', 'HER', 'HE', 'SHE')],
'section': 'family'},
{'correct': [], 'incorrect': [], 'section': 'gram1-adjective-to-adverb'},
{'correct': [], 'incorrect': [], 'section': 'gram2-opposite'},
{'correct': [('GOOD', 'BETTER', 'GREAT', 'GREATER'),
('GREAT', 'GREATER', 'LOW', 'LOWER'),
('LONG', 'LONGER', 'GREAT', 'GREATER')],
'incorrect': [('GOOD', 'BETTER', 'LONG', 'LONGER'),
('GOOD', 'BETTER', 'LOW', 'LOWER'),
('GREAT', 'GREATER', 'LONG', 'LONGER'),
('GREAT', 'GREATER', 'GOOD', 'BETTER'),
('LONG', 'LONGER', 'LOW', 'LOWER'),
('LONG', 'LONGER', 'GOOD', 'BETTER'),
('LOW', 'LOWER', 'GOOD', 'BETTER'),
('LOW', 'LOWER', 'GREAT', 'GREATER'),
('LOW', 'LOWER', 'LONG', 'LONGER')],
'section': 'gram3-comparative'},
{'correct': [('GREAT', 'GREATEST', 'LARGE', 'LARGEST')],
'incorrect': [('BIG', 'BIGGEST', 'GOOD', 'BEST'),
('BIG', 'BIGGEST', 'GREAT', 'GREATEST'),
('BIG', 'BIGGEST', 'LARGE', 'LARGEST'),
('GOOD', 'BEST', 'GREAT', 'GREATEST'),
('GOOD', 'BEST', 'LARGE', 'LARGEST'),
('GOOD', 'BEST', 'BIG', 'BIGGEST'),
('GREAT', 'GREATEST', 'BIG', 'BIGGEST'),
('GREAT', 'GREATEST', 'GOOD', 'BEST'),
('LARGE', 'LARGEST', 'BIG', 'BIGGEST'),
('LARGE', 'LARGEST', 'GOOD', 'BEST'),
('LARGE', 'LARGEST', 'GREAT', 'GREATEST')],
'section': 'gram4-superlative'},
{'correct': [('GO', 'GOING', 'PLAY', 'PLAYING'),
('PLAY', 'PLAYING', 'SAY', 'SAYING'),
('PLAY', 'PLAYING', 'LOOK', 'LOOKING'),
('SAY', 'SAYING', 'LOOK', 'LOOKING'),
('SAY', 'SAYING', 'PLAY', 'PLAYING')],
'incorrect': [('GO', 'GOING', 'LOOK', 'LOOKING'),
('GO', 'GOING', 'RUN', 'RUNNING'),
('GO', 'GOING', 'SAY', 'SAYING'),
('LOOK', 'LOOKING', 'PLAY', 'PLAYING'),
('LOOK', 'LOOKING', 'RUN', 'RUNNING'),
('LOOK', 'LOOKING', 'SAY', 'SAYING'),
('LOOK', 'LOOKING', 'GO', 'GOING'),
('PLAY', 'PLAYING', 'RUN', 'RUNNING'),
('PLAY', 'PLAYING', 'GO', 'GOING'),
('RUN', 'RUNNING', 'SAY', 'SAYING'),
('RUN', 'RUNNING', 'GO', 'GOING'),
('RUN', 'RUNNING', 'LOOK', 'LOOKING'),
('RUN', 'RUNNING', 'PLAY', 'PLAYING'),
('SAY', 'SAYING', 'GO', 'GOING'),
('SAY', 'SAYING', 'RUN', 'RUNNING')],
'section': 'gram5-present-participle'},
{'correct': [('AUSTRALIA', 'AUSTRALIAN', 'INDIA', 'INDIAN'),
('AUSTRALIA', 'AUSTRALIAN', 'ISRAEL', 'ISRAELI'),
('FRANCE', 'FRENCH', 'INDIA', 'INDIAN'),
('FRANCE', 'FRENCH', 'ISRAEL', 'ISRAELI'),
('INDIA', 'INDIAN', 'ISRAEL', 'ISRAELI'),
('INDIA', 'INDIAN', 'AUSTRALIA', 'AUSTRALIAN'),
('ISRAEL', 'ISRAELI', 'INDIA', 'INDIAN'),
('SWITZERLAND', 'SWISS', 'INDIA', 'INDIAN')],
'incorrect': [('AUSTRALIA', 'AUSTRALIAN', 'FRANCE', 'FRENCH'),
('AUSTRALIA', 'AUSTRALIAN', 'SWITZERLAND', 'SWISS'),
('FRANCE', 'FRENCH', 'SWITZERLAND', 'SWISS'),
('FRANCE', 'FRENCH', 'AUSTRALIA', 'AUSTRALIAN'),
('INDIA', 'INDIAN', 'SWITZERLAND', 'SWISS'),
('INDIA', 'INDIAN', 'FRANCE', 'FRENCH'),
('ISRAEL', 'ISRAELI', 'SWITZERLAND', 'SWISS'),
('ISRAEL', 'ISRAELI', 'AUSTRALIA', 'AUSTRALIAN'),
('ISRAEL', 'ISRAELI', 'FRANCE', 'FRENCH'),
('SWITZERLAND', 'SWISS', 'AUSTRALIA', 'AUSTRALIAN'),
('SWITZERLAND', 'SWISS', 'FRANCE', 'FRENCH'),
('SWITZERLAND', 'SWISS', 'ISRAEL', 'ISRAELI')],
'section': 'gram6-nationality-adjective'},
{'correct': [('PAYING', 'PAID', 'SAYING', 'SAID')],
'incorrect': [('GOING', 'WENT', 'PAYING', 'PAID'),
('GOING', 'WENT', 'PLAYING', 'PLAYED'),
('GOING', 'WENT', 'SAYING', 'SAID'),
('GOING', 'WENT', 'TAKING', 'TOOK'),
('PAYING', 'PAID', 'PLAYING', 'PLAYED'),
('PAYING', 'PAID', 'TAKING', 'TOOK'),
('PAYING', 'PAID', 'GOING', 'WENT'),
('PLAYING', 'PLAYED', 'SAYING', 'SAID'),
('PLAYING', 'PLAYED', 'TAKING', 'TOOK'),
('PLAYING', 'PLAYED', 'GOING', 'WENT'),
('PLAYING', 'PLAYED', 'PAYING', 'PAID'),
('SAYING', 'SAID', 'TAKING', 'TOOK'),
('SAYING', 'SAID', 'GOING', 'WENT'),
('SAYING', 'SAID', 'PAYING', 'PAID'),
('SAYING', 'SAID', 'PLAYING', 'PLAYED'),
('TAKING', 'TOOK', 'GOING', 'WENT'),
('TAKING', 'TOOK', 'PAYING', 'PAID'),
('TAKING', 'TOOK', 'PLAYING', 'PLAYED'),
('TAKING', 'TOOK', 'SAYING', 'SAID')],
'section': 'gram7-past-tense'},
{'correct': [('MAN', 'MEN', 'CHILD', 'CHILDREN')],
'incorrect': [('BUILDING', 'BUILDINGS', 'CAR', 'CARS'),
('BUILDING', 'BUILDINGS', 'CHILD', 'CHILDREN'),
('BUILDING', 'BUILDINGS', 'MAN', 'MEN'),
('CAR', 'CARS', 'CHILD', 'CHILDREN'),
('CAR', 'CARS', 'MAN', 'MEN'),
('CAR', 'CARS', 'BUILDING', 'BUILDINGS'),
('CHILD', 'CHILDREN', 'MAN', 'MEN'),
('CHILD', 'CHILDREN', 'BUILDING', 'BUILDINGS'),
('CHILD', 'CHILDREN', 'CAR', 'CARS'),
('MAN', 'MEN', 'BUILDING', 'BUILDINGS'),
('MAN', 'MEN', 'CAR', 'CARS')],
'section': 'gram8-plural'},
{'correct': [], 'incorrect': [], 'section': 'gram9-plural-verbs'},
{'correct': [('GOOD', 'BETTER', 'GREAT', 'GREATER'),
('GREAT', 'GREATER', 'LOW', 'LOWER'),
('LONG', 'LONGER', 'GREAT', 'GREATER'),
('GREAT', 'GREATEST', 'LARGE', 'LARGEST'),
('GO', 'GOING', 'PLAY', 'PLAYING'),
('PLAY', 'PLAYING', 'SAY', 'SAYING'),
('PLAY', 'PLAYING', 'LOOK', 'LOOKING'),
('SAY', 'SAYING', 'LOOK', 'LOOKING'),
('SAY', 'SAYING', 'PLAY', 'PLAYING'),
('AUSTRALIA', 'AUSTRALIAN', 'INDIA', 'INDIAN'),
('AUSTRALIA', 'AUSTRALIAN', 'ISRAEL', 'ISRAELI'),
('FRANCE', 'FRENCH', 'INDIA', 'INDIAN'),
('FRANCE', 'FRENCH', 'ISRAEL', 'ISRAELI'),
('INDIA', 'INDIAN', 'ISRAEL', 'ISRAELI'),
('INDIA', 'INDIAN', 'AUSTRALIA', 'AUSTRALIAN'),
('ISRAEL', 'ISRAELI', 'INDIA', 'INDIAN'),
('SWITZERLAND', 'SWISS', 'INDIA', 'INDIAN'),
('PAYING', 'PAID', 'SAYING', 'SAID'),
('MAN', 'MEN', 'CHILD', 'CHILDREN')],
'incorrect': [('HE', 'SHE', 'HIS', 'HER'),
('HIS', 'HER', 'HE', 'SHE'),
('GOOD', 'BETTER', 'LONG', 'LONGER'),
('GOOD', 'BETTER', 'LOW', 'LOWER'),
('GREAT', 'GREATER', 'LONG', 'LONGER'),
('GREAT', 'GREATER', 'GOOD', 'BETTER'),
('LONG', 'LONGER', 'LOW', 'LOWER'),
('LONG', 'LONGER', 'GOOD', 'BETTER'),
('LOW', 'LOWER', 'GOOD', 'BETTER'),
('LOW', 'LOWER', 'GREAT', 'GREATER'),
('LOW', 'LOWER', 'LONG', 'LONGER'),
('BIG', 'BIGGEST', 'GOOD', 'BEST'),
('BIG', 'BIGGEST', 'GREAT', 'GREATEST'),
('BIG', 'BIGGEST', 'LARGE', 'LARGEST'),
('GOOD', 'BEST', 'GREAT', 'GREATEST'),
('GOOD', 'BEST', 'LARGE', 'LARGEST'),
('GOOD', 'BEST', 'BIG', 'BIGGEST'),
('GREAT', 'GREATEST', 'BIG', 'BIGGEST'),
('GREAT', 'GREATEST', 'GOOD', 'BEST'),
('LARGE', 'LARGEST', 'BIG', 'BIGGEST'),
('LARGE', 'LARGEST', 'GOOD', 'BEST'),
('LARGE', 'LARGEST', 'GREAT', 'GREATEST'),
('GO', 'GOING', 'LOOK', 'LOOKING'),
('GO', 'GOING', 'RUN', 'RUNNING'),
('GO', 'GOING', 'SAY', 'SAYING'),
('LOOK', 'LOOKING', 'PLAY', 'PLAYING'),
('LOOK', 'LOOKING', 'RUN', 'RUNNING'),
('LOOK', 'LOOKING', 'SAY', 'SAYING'),
('LOOK', 'LOOKING', 'GO', 'GOING'),
('PLAY', 'PLAYING', 'RUN', 'RUNNING'),
('PLAY', 'PLAYING', 'GO', 'GOING'),
('RUN', 'RUNNING', 'SAY', 'SAYING'),
('RUN', 'RUNNING', 'GO', 'GOING'),
('RUN', 'RUNNING', 'LOOK', 'LOOKING'),
('RUN', 'RUNNING', 'PLAY', 'PLAYING'),
('SAY', 'SAYING', 'GO', 'GOING'),
('SAY', 'SAYING', 'RUN', 'RUNNING'),
('AUSTRALIA', 'AUSTRALIAN', 'FRANCE', 'FRENCH'),
('AUSTRALIA', 'AUSTRALIAN', 'SWITZERLAND', 'SWISS'),
('FRANCE', 'FRENCH', 'SWITZERLAND', 'SWISS'),
('FRANCE', 'FRENCH', 'AUSTRALIA', 'AUSTRALIAN'),
('INDIA', 'INDIAN', 'SWITZERLAND', 'SWISS'),
('INDIA', 'INDIAN', 'FRANCE', 'FRENCH'),
('ISRAEL', 'ISRAELI', 'SWITZERLAND', 'SWISS'),
('ISRAEL', 'ISRAELI', 'AUSTRALIA', 'AUSTRALIAN'),
('ISRAEL', 'ISRAELI', 'FRANCE', 'FRENCH'),
('SWITZERLAND', 'SWISS', 'AUSTRALIA', 'AUSTRALIAN'),
('SWITZERLAND', 'SWISS', 'FRANCE', 'FRENCH'),
('SWITZERLAND', 'SWISS', 'ISRAEL', 'ISRAELI'),
('GOING', 'WENT', 'PAYING', 'PAID'),
('GOING', 'WENT', 'PLAYING', 'PLAYED'),
('GOING', 'WENT', 'SAYING', 'SAID'),
('GOING', 'WENT', 'TAKING', 'TOOK'),
('PAYING', 'PAID', 'PLAYING', 'PLAYED'),
('PAYING', 'PAID', 'TAKING', 'TOOK'),
('PAYING', 'PAID', 'GOING', 'WENT'),
('PLAYING', 'PLAYED', 'SAYING', 'SAID'),
('PLAYING', 'PLAYED', 'TAKING', 'TOOK'),
('PLAYING', 'PLAYED', 'GOING', 'WENT'),
('PLAYING', 'PLAYED', 'PAYING', 'PAID'),
('SAYING', 'SAID', 'TAKING', 'TOOK'),
('SAYING', 'SAID', 'GOING', 'WENT'),
('SAYING', 'SAID', 'PAYING', 'PAID'),
('SAYING', 'SAID', 'PLAYING', 'PLAYED'),
('TAKING', 'TOOK', 'GOING', 'WENT'),
('TAKING', 'TOOK', 'PAYING', 'PAID'),
('TAKING', 'TOOK', 'PLAYING', 'PLAYED'),
('TAKING', 'TOOK', 'SAYING', 'SAID'),
('BUILDING', 'BUILDINGS', 'CAR', 'CARS'),
('BUILDING', 'BUILDINGS', 'CHILD', 'CHILDREN'),
('BUILDING', 'BUILDINGS', 'MAN', 'MEN'),
('CAR', 'CARS', 'CHILD', 'CHILDREN'),
('CAR', 'CARS', 'MAN', 'MEN'),
('CAR', 'CARS', 'BUILDING', 'BUILDINGS'),
('CHILD', 'CHILDREN', 'MAN', 'MEN'),
('CHILD', 'CHILDREN', 'BUILDING', 'BUILDINGS'),
('CHILD', 'CHILDREN', 'CAR', 'CARS'),
('MAN', 'MEN', 'BUILDING', 'BUILDINGS'),
('MAN', 'MEN', 'CAR', 'CARS')],
'section': 'total'}]
单词移动距离
以两个句子为例:
sentence_obama = 'Obama speaks to the media in Illinois'.lower().split()
sentence_president = 'The president greets the press in Chicago'.lower().split()去除停用词:
from nltk.corpus import stopwords
stopwords = stopwords.words('english')
sentence_obama = [w for w in sentence_obama if w not in stopwords]
sentence_president = [w for w in sentence_president if w not in stopwords]计算 WMD:
distance = model.wmdistance(sentence_obama, sentence_president)
print(distance)Out:
1.3929935492649077就这样! 恭喜你完成了本教程!