Kaggle HousePrice 特征工程部分之统计检验
專 欄
王勇,Python中文社区专栏作者,目前感兴趣项目为商业分析、Python、机器学习、Kaggle。17年项目管理,通信业干了11年项目经理管合同交付,制造业干了6年项目管理:PMO,变革,生产转移,清算和资产处理。MBA, PMI-PBA, PMP。
❈本文目标是通过比较,引入传统的统计方法(上古魔法),打开数据集的黑盒子。探讨如下方法:
1、检验训练集和测试集是否相同分布。相同分布,是统计方法和机器学习的共同前提。 这可以帮助预判后面的机器学习的训练,调参和stacking是否有意义?
2、统计检验发现的概率(p value)帮助做feature selection辅助。
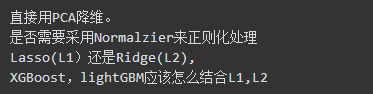
3、检查变量间是否存在共线性关系(奇异矩阵,不满秩) ? 后期机器学习,或者预处理,应该采用什么样的方式正则化处理? 例如:
直接用PCA降维。
是否需要采用Normalzier来正则化处理
Lasso(L1)还是Ridge(L2),
XGBoost,lightGBM应该怎么结合L1,L2
网上和一些书上都有对比统计方法和机器学习方法,非常精彩。品味这些文章和书籍后,我的理解是:
统计-上古魔法
机器学习-上帝视角
两者相同之处:针对已有的数据,推导出来理解和认知。
两者不同之处:统计方法就像上古魔法。因为数据很少,数据很宝贵,计算能力也能昂贵。主要靠神秘的魔法师和神秘的魔法,即统计学家,统计和概率学。统计学家,开山鼻祖就是来自北方冰雪之国的Kolmogorov马尔可夫。统计和概率的基础:假设,中心极限定理,大数定理等。
机器学习就像开了上帝视角的游戏玩家。因为数据又多又广(足够多的话,就好比开了上帝视角的游戏玩家),训练数据可能有数百万条,甚至更多。例如:Kaggle 的Bosche 生产线优化案例,解压后数据文件超过了60G, 数据记录约5百万条(注:Dream competition 之一,可惜对机器内存,和算力要求太高。 Kaggle上的许多选手都只采用了部分数据抽样来作预测),训练数据(sample)足够广,甚至可以作为总体(population)来看待。上面这两点都成立的话,这简直就是游戏中的上帝视角。所有尽在掌握了,计算能力便宜,云计算和GPU,TPU让计算机时不再成为约束。
等等,扯了半天。这和Kaggle HousePrice特征工程部分有啥关系?为啥在浪费时间,浪费口水,扯上面的东西?答案是,在House Price 机器学习的优势并不显著呀!
首先,数据机不多也不广,上帝视角没有开,训练集只有1460条记录,测试集和训练集几乎相等。
其次,计算能力也不够,自费玩Kaggle的限制。 文章第一篇,我说过参加比赛用的机器是阿里云-最低配版本(单核1Gcpu,1G内存)。GradientBoost,这类算法耗时太长,基本就不用。甚至传说中的XGBoost神器,也只是参考使用。在(n_estimator)小于3000时,RMSE成绩太差。大于3000后,计算单个Pipe就要用上0.5到1个小时。 更不要说,Stacking和Ensemble时候的CV叠加时间,N小时。N>2。
那么,为什么不用统计方法来看看?说干就干。
应该是如下几个步骤:
1、检验训练集和测试集是否来自同一个分布?如果不是,就洗洗睡吧。统计方法或者机器学习没有意义的。如果是同一个分布,不能拒绝学习时有意义的这一假设。上面的话比较拗口,简单说来。就好比,拿乐高得宝积木来玩普通乐高积木。两者虽然都是积木,但是大小尺寸不一样。"通常"不能直接一起玩。
2、用统计方法,来看看(采用经典二乘法)下面这些情况。
回归的整体结果是否有意义(Ftest)
回归的数据集中的变量(Xi)是否有贡献(Ttest)
回归的可预测性R2(adjusted R2)高低
回归的数据集中的变量(Xi)是否存在多重共线性(multicollinearity)或者说是否是奇异矩阵(Singular Matrix)
存在多重共线性(或者说奇异矩阵)怎么办?好吧,首先来看看检验训练集和测试集是否来自同一个分布?
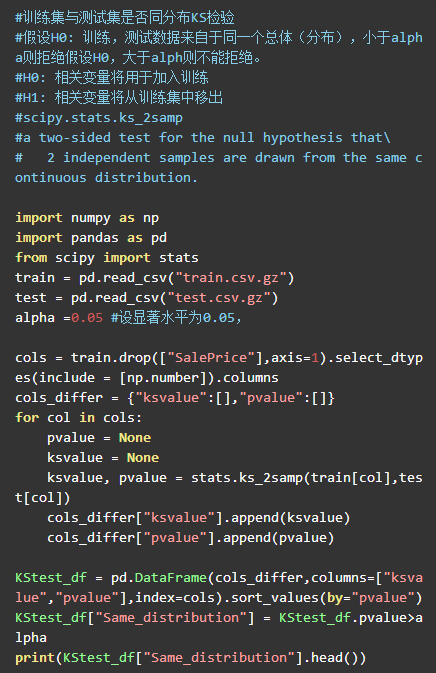

从上面的KS test 可以看出,除了Id 以外的Feature 列都通过了Kstest (预设显著性水平为0.05,两侧检验),看来,训练集和测试集是相关。把Id列删除了,就能玩。
上面列了许多问题,其实用Python测试起来非常简单。Pandas+Statsmodel就可以搞定。我在Kaggle HousePrice : LB 0.11666(前15%),用搭积木的方式(2.实践-特征工程部分)一文中,最后一个test函数中已经写好了这部分内容。只要把注释去掉,就可以解锁新的姿势,哈哈。
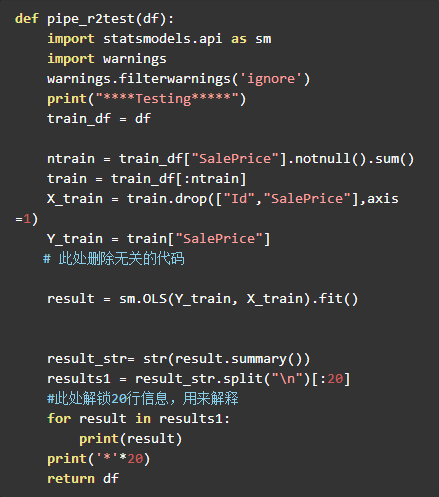
其他函数不变。下面用搭积木的方式来生产两个预处理文件并比较测试。
注:pipe_PCA是一个新函数。这两天刚刚做出来的特征函数之一。基于statsmodels库,当然sklearn 和scipy 也有同样的库,我只是选用了其中的一个方法而已。


先上结论:
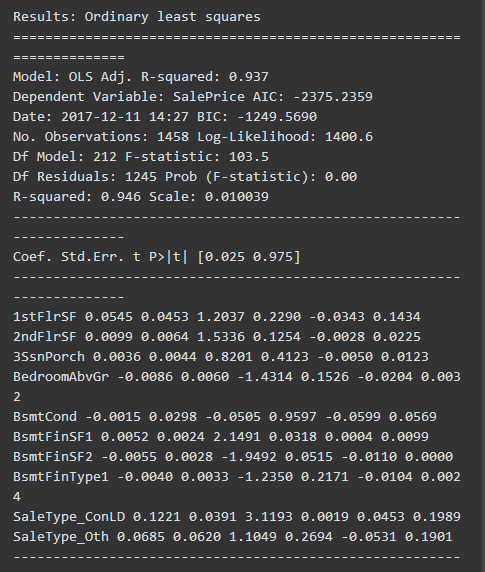
**回归的整体结果有意义。**Ftest 的概率=0,拒绝零假设(即:回归模型直线斜率=0)
1、Basic 小火车(Pipe测试):有意义,Prob (F-statistic): 0.00
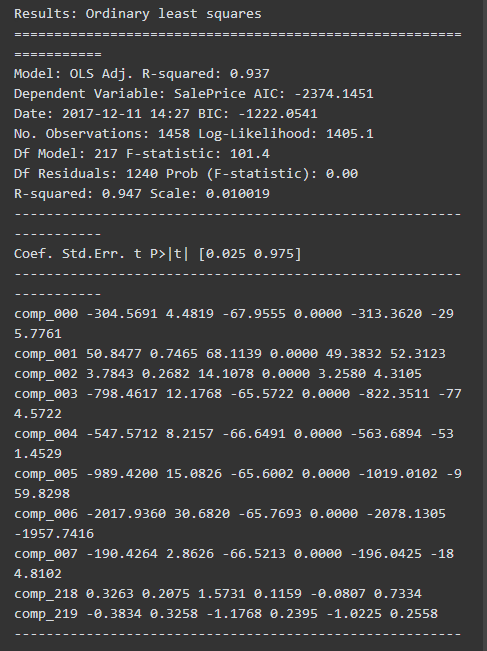
2、Basic_PCA小货车(Pipe测试):有意义,Prob (F-statistic): 0.00
回归的数据集中较多变量(Xi)没有贡献
(P>|t|列,是计算出来的Xi的贡献概率。 假定alpha=0.05,许多列都大于0.05.不能拒绝零假设)零假设,是该Xi的系数(coe) =0. 不能拒绝零假设,意味着很可能有没有这个Xi特征变量,对于回归来说都没有关系。
变量(Xi)没有贡献,往往意味着可以直接从模型中删除,这样可以提高计算的速度和降低噪音。不过如何删除就是另一个特征工程话题。可以通过feature selection或者PCA方式。 下文小火车2(Basic_PCA)就展示PCA进行了正交处理的功能。
例如:

回归的可预测性R2(adjusted R2)一样。
为了展示方便,小火车Basic_PCA管道没有进一步处理,故两者adjusted R2一样。
Basic 小火车(Pipe测试): 0.937
Basic_PCA小火车: 0.937
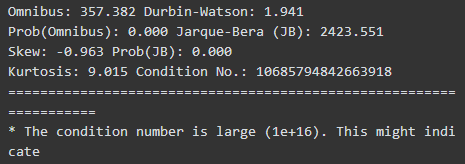
回归的数据集中的变量(Xi)存在多重共线性(multicollinearity)是奇异矩阵(Singular Matrix),Statsmodel 提供了Condition number 作为共线性和奇异矩阵的判断标准。 这两个处理后的数据都有非常严重的共线性。
The condition number is large (1e+18)
The condition number is large (1e+16)
从上面可以看出,通过传统的统计方法(上古魔法),可以打开数据集的黑盒子。可以达到如下目标:
1、检验训练集和测试集是否相同分布。相同分布,是统计方法和机器学习的共同前提。 这可以帮助预判后面的机器学习的训练,调参和stacking是否有意义?
2、检查变量间是否存在共线性关系(奇异矩阵,不满秩) ? 后期机器学习,或者预处理,应该采用什么样的方式正则化处理?
例如:
feature 选择时的两种方法机器学习参数(lasso, randomforest) 还是用统计检验发现的概率(p value)
输出摘要:
小火车 - pipe_basic 测试结果

小火车 - pipe_basic_pca 测试结果

长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
