Flink之运行时环境
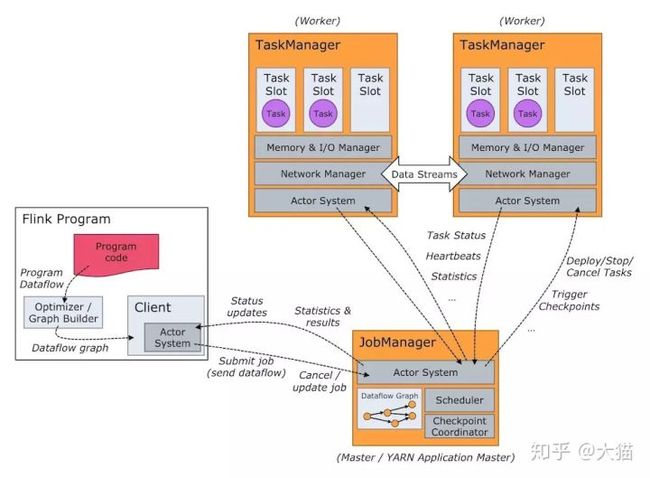
Flink 运行时环境由两种类型进程组成,JobManager和TaskManager
- JobManager,也称为 master,用于协调分布式执行。负责调度任务,检查点,失败恢复等。
- TaskManager,也称为 worker,用于执行数据流图的任务(更准确地说,是计算子任务),并对数据流进行缓冲、交换。Flink 运行环境中至少包含一个任务管理器。
Flink作业流程
Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。
在Local模式下,会在同一个JVM内部启动一个JobManager进程和TaskManager进程。当Flink程序提交后,会创建一个Client来进行预处理,并转换为一个并行数据流,这是对应着一个Flink Job,从而可以被JobManager和TaskManager执行。
在实现上,Flink基于Actor实现了JobManager和TaskManager,所以JobManager与TaskManager之间的信息交换,都是通过事件的方式来进行处理。 如上图所示,Flink系统主要包含如下3个主要的进程:
关于JobManager
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负责收集Job的状态信息,并管理Flink集群中从节点TaskManager。
JobManager所负责的各项管理功能,它接收到并处理的事件主要包括:
- RegisterTaskManager
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复消息AcknowledgeRegistration。
- SubmitJob
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息。
- CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则返回消息CancellationFailure。
- UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
- RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
- JobStatusChanged
ExecutionGraph向JobManager发送该消息,用来表示Flink Job的状态发生的变化,例如:RUNNING、CANCELING、FINISHED等。
关于TaskManager
TaskManager也是一个Actor,它是实际负责执行计算的Worker,在其上执行Flink Job的一组Task。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
TaskManager端可以分成两个阶段:
- 注册阶段
TaskManager会向JobManager注册,发送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然后TaskManager就可以进行初始化过程。
- 可操作阶段
该阶段TaskManager可以接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager无法连接到JobManager,这是TaskManager就失去了与JobManager的联系,会自动进入“注册阶段”,只有完成注册才能继续处理Task相关的消息。
Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
Client会将用户提交的Flink程序组装一个JobGraph, 并且是以JobGraph的形式提交的。一个JobGraph是一个Flink Dataflow,它由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
若干概念
任务槽与资源
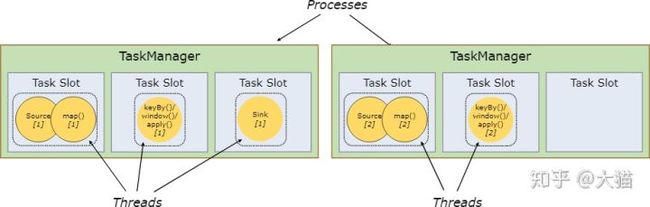
每个 worker(任务管理器)都是一个独立的 JVM 进程,每个子任务就是运行在其中的独立线程里。为了控制 worker 接收任务的数量,在 worker 中引入了任务槽的概念(每个 worker 中至少包含一个任务槽)。
每个任务槽代表任务管理器中一个特定的资源池子集。例如,如果任务管理器有3个槽,它会为每个槽分配 1/3 的内存。将资源池槽化可以让子任务获取指定容量的内存资源,而避免同其他作业中的子任务竞争。注意,这里没有对 CPU 进行隔离;目前任务槽仅仅用于划分任务的内存。
通过调整任务槽的数量,用户可以设定子任务之间独立运行的程度。如果任务管理器中只有一个槽,那么每个任务组都会在一个独立的 JVM(例如 JVM 可以在一个独立的容器中启动)中运行。任务管理器中配置更多的槽就意味着会有更多的子任务共享同一个 JVM。在同一个 JVM 中的任务会共享 TCP 连接(通过多路复用的方式)和心跳信息,同时他们也会共享数据集和数据结构,这在某种程度上可以降低单任务的开销。
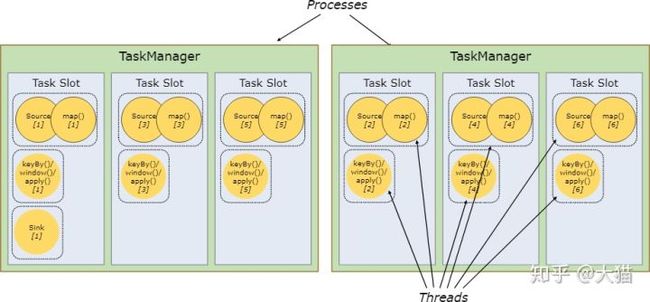
默认情况下,Flink 会允许同一个作业的多个子任务共享一个槽,即便这些子任务来自不同的任务。这种情况下,有可能会出现某个槽中包含一个完整的作业流水的场景。这样做主要有两点好处:
- Flink 集群需要在作业中确保任务槽数量和程序并发量完全一致,而并不需要计算程序中任务(每个任务的并发量也许都不相同)的具体数量。
- 可以提高资源利用率。如果没有任务槽共享机制,非密集型的 source/map() 子任务就会和密集型的 window 子任务一样阻塞大量资源。如果有任务槽共享机制,在程序的并发量从 2 提高到 6 的情况下(举个例子),就可以让密集型子任务完全分散到任务管理器中,从而可以显著提高槽的资源利用率。
Flink API 中包含一个资源组机制,可以避免不合理的任务槽共享。
依照以往的经验来说,默认的任务槽数量应设置为 CPU 核心的数量。如果使用超线程技术,每个槽中甚至可以调度处理超过 2 个硬件线程。
后端存储
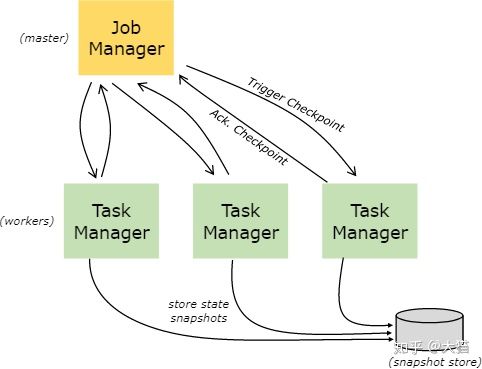
通过键值对索引的数据结构保存在选定的后端存储中。有的后端存储将数据保存在内存中的哈希表中,而有的存储会使用 RocksDB 来保存键值对。除了定义保存状态的数据结构之外,后端存储还实现了获取键值对的特定时间点快照的功能,该功能可以将快照保存为检查点的一部分。
保存点
使用数据流 API 的程序可以从指定的保存点恢复。保存点具备更新程序和 Flink 集群而不丢失任何状态的功能。
保存点可以看作是一种手动触发的检查点,该检查点可以获取程序的快照并将其写入后端存储中。所以说保存点的功能依赖于一般的检查点机制。程序执行时会定期在 worker 节点生成快照和检查点。由于 Flink 的恢复机制只需要使用最新一个有效的检查点,在新的检查点生成后就可以安全移除其余旧的检查点了。
保存点和定期检查点在大部分情况下都很相似,区别只在于保存点是由用户触发的,并且在新的检查点生成后不会自动过期失效。保存点可以通过命令行生成,也可以在调用REST API取消作业时产生。