清华大学计算机操作系统网易公开课笔记(持续更新)
注:本文使用的所有截图均来自于网易公开课课程
1.开机
开机的时候,内存里的bios先进行外设的自检,然后从硬盘加载bootloader到内存,然后指令转到bootloader的地址,然后再把操作系统加载到内存里,然后指令转到操作系统的地址,由操作系统接管整个机器。
2.中断和异常
中断(interrupt):来源于外设,系统调用(system call)和异常(exception)来源于应用程序。处理时间:中断异步,异常同步,系统调用异步或同步,同步指你知道这里会发生,异步指你在等待,不知道这里会不会发生。响应:中断,持续,异常,杀死或重新执行,系统调用:等待和持续。
产生中断或者异常,由哪个位置服务呢?我们有个表,一侧称为key,是中断号或者异常号,给他编号可以区分不同的外设的中断,每个编号有个地址,收到中断,查中断表,直接转到地址去执行指令。程序的保存与恢复:中断后程序回到之前状态执行。
- 中断处理过程
硬件:外设产生中断标记,cpu看到标记可以得出是哪号中断,可以得到一个具体的中断号,把中断号发给操作系统。
软件:保存被打断的现场+中断服务程序处理+清除中断标记+恢复之前保存的处理状态。
- 异常处理过程
异常编号,保存现场,异常处理(杀死产生异常的程序或者重新执行异常指令),恢复现场后,重点是,这里可能会修复异常指令后重新执行指令
- 系统调用过程
系统调用接口:操作系统给应用程序提供服务。
如:应用程序代码printf触发系统调用write,包括显示设备和显示内容,获取信息后就会去执行。
操作系统有各自的高级API,应用程序一般直接调用这些高级API,比如win32API用于windows,java API用于JAVA虚拟机(jvm),POSIX用于POSIX-based system(包括unix,linux,macosx),JVM是虚拟在windows和posix上的。
- 操作系统怎样完成系统调用的实现呢?
Interface(应用程序通过library库访问) –> 触发从用户态到内核态的转变(用户态:特权级低,不能访问特权指令和IO指令,内核态:特权级高,可以访问所有的指令,控制权从应用程序交到操作系统 -> 从系统调用ID号,等参数做标识,从而识别并完成对应服务。函数调用:一个堆栈内完成;系统调用,不同堆栈完成
3.1 计算机体系结构和内存分层
- 体系结构
CPU,内存,设备(I/O)
- 内存层次结构
CPU访问的数据包括指令和数据,从CPU往外:寄存器,cache,主存(即物理内存),磁盘(虚拟内存)
- 操作系统的目标
1. 抽象:应用程序不用考虑底层的东西,只要考虑一个连续的逻辑地址空间即可
2. 保护:内存中可同时运行多个不同的应用程序,可能会需要访问想同的内存空间,可能会破坏,需要隔离。
3. 共享:很多应用程序要共享数据,进程之间要交互,使得进程之间能够安全可靠地传递数据
4. 虚拟化:当内存不够的时候,把最需要内存空间的数据放到内存里,暂时不需要访问的数据可以放到硬盘里,硬盘分配出一块虚拟空间。
CPU运行程序时,要把两个部分放到内存中:
(1) 程序本身 (2)程序要使用的数据
操作系统管理内存必须高度依赖硬件
3.2 地址空间和地址生成
- 物理地址空间
主存和硬盘,和硬件直接对应,管理和控制由硬件完成。
- 逻辑地址空间
一个运行的程序看到的内存空间(程序没有直接访问硬盘的权限,需要通过操作系统转化地址,并且方便应用程序自身的访问和控制)是一个简单的一维数据空间。两者形成映射。
- 逻辑地址生成
对一个.c file从硬盘上创建编译汇编链接,再载入到内存中的全过程:(每个部分的逻辑地址都是只对它自己有意义)
1、一个c file,函数位置和变量名字就是它逻辑地址;
2、经过编译后得.s file,还是名字;
3、经过汇编,得到.o file,这时候,语句已经分布到一个它的一维的逻辑地址了,比如,jmp 75,指的是跳到逻辑地址为75的语句
4、再经过链接(多个文件),成为exe file,已经是可以执行但是目前还存放在硬盘里的程序,地址已经进行了全局的分布,不同的.o程序对应到了同一个一维逻辑地址的不同位置,从常规库开始分布,后面是各个文件语句的位置。
5、载入:放在硬盘中的exe文件,通过loader,loader也是一个应用程序,当程序被操作系统放到内存中去运行,loader在上面的逻辑地址加上一个偏移量,得到了内存中的逻辑地址。
1到5步,不需要操作系统参与,通过编译器,通过loader等,就可以完成,接下来,我们要把这个最终得到的内存中的逻辑地址转化成物理地址。
CPU有一个叫MMU,内存管理单元,里面有一块区域,表示了逻辑地址到物理地址的映射关系,也存在内存中的一个位置。我们查这个表,就能知道了。
- CPU执行指令流程
流程:CPU执行一条指令,ALU部件需要发出请求这条指令的内容,参数就是逻辑地址,CPU就去查MMU中的映射表,如果有就找到了物理地址,如果没有就去内存的map中找,然后CPU的控制器给主存发出一个请求,需要这个物理地址的内容,主存通过总线把这个内容通过主线传到CPU,进行执行。操作系统完成的就是在这个流程之前,就建好逻辑地址到物理地址的映射关系。这个关系可以放在内存中,加快速度。
操作系统还要设置逻辑地址空间的基址和界限,以保证内存访问的正确性。超过界限,就抛出异常,按前述异常处理。
3.3 连续内存分配
内存碎片:外碎片,程序分配的区域之间的碎片;内碎片:程序分配之内的碎片
操作系统把程序从硬盘加载到内存中去,需要分配一块空间,常用的分配策略:
首次适配first fit,最优适配best fit和最差适配worst fit
first fit:从零开始,找到的第一个能放得下的空间放它
best fit:最小的可以放得下的空间放它
worst fit:最大的可以放得下的空间放它
3.4 连续内存分配:压缩式与交换式碎片整理
(一)压缩式碎片整理
重置程序以合并孔洞
要求所有程序是动态可重置的
(二)交换式碎片整理
运行程序需要更多的内存
抢占等待的程序&回收它们的内存
4.1 非连续内存分配:分段
可以更好的利用碎片,需要从逻辑地址到物理地址的转换:软件方案带来开销太大,所以要和硬件进行结合。
主要方法:分段方法和分页方法。
分段方法核心问题
如何寻址和怎么实现分段寻址机制?
- 思想
连续逻辑地址分段后放在不连续的不同段的物理地址中。 - 寻址
一个逻辑地址,分为一个段号s和段内偏移offset的二元组(s,offset),可以是段寄存器+地址寄存器方案,也可以是两个接在一起的单地址方案。 - 实现
一个程序,通过CPU执行每条指令,CPU就要进行寻址,即具体的物理地址在哪,逻辑地址分成两部分,第一部分是段号,第二部分是段偏移,操作系统建立一个段表,对于一个逻辑地址的段号作为索引index,在段表里查找出唯一一个二元组(base,limit),这个二元组对应的是物理地址的基址和界限,然后再基址的基础上加上偏移offset即为物理地址。如果超过了界限,就按之前说的,抛出异常,按异常的方法进行处理,流程如下图:

4.2 非连续内存分配:分页
和分段一样,也需要页号和页的偏移
把物理内存划分为固定大小的帧;把逻辑地址划分至相同大小的页
划分大小是2的幂,划分数量也是2的幂,这样就能把页号,帧号和页内偏移,帧内偏移都用二级制的位数来代替。
一个物理地址是二元组(f,o)f是帧号,共有2(f)个帧,o有S位,即每帧有2(s)字节,注意,这里每个位置是存了一个字节,因为计算机中最基础的存储单位是字节。


逻辑地址:页
逻辑地址被分为大小相等的页,页内偏移大小=帧内偏移大小,页号大小和帧号大小进行映射,其他的格式和物理地址一样,注意的是,保存页号的位数一般来说会大于保存帧号的位数,那么物理内存少了怎么办?用到虚拟内存,以后再说。
转换过程:页号作为索引,在页表里面查找对应帧号,需要的是两个,页号和页表基址(页表从哪里开始),查找得到帧号在加上偏移量(两个偏移量是相同的)得到物理地址。


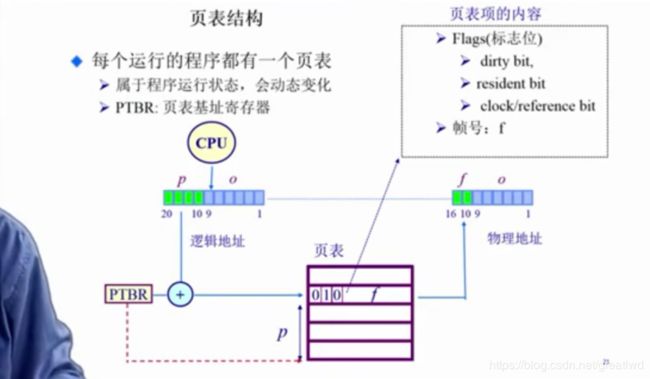
4.3 非连续内存分配 页表
操作系统和硬件相互配合才能完成的目标:页表
页表是个大数组,索引是页号,索引对应的内容是帧号,页表项还包含着一些用来描述状态的标志位(Flags)标志存在与否,写入读出等
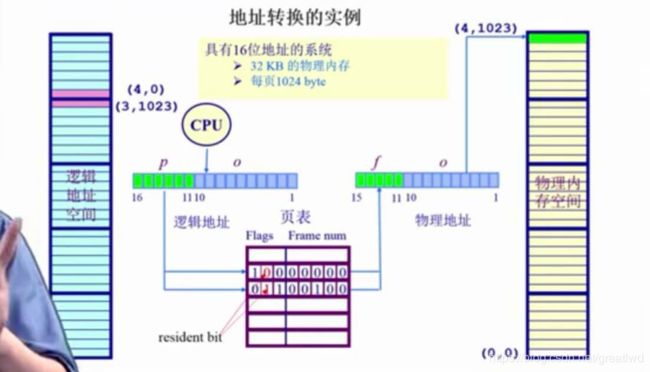
16位地址,对应的是64kb逻辑地址,如果这时候只有32kb物理内存,我们一般以1kb为一页,页号就有6位(绿色11到16),帧号只有5位(绿色11到15),可能有些逻辑地址就不存在对应的物理地址。
页表里面,resident bit 代表当前物理内存是否存在,0代表不存在,1代表存在,CPU如果访问这个地址会产生一个异常。一般情况下,这样的非法访问,操作系统杀死这个程序
- 带来的问题:页表会占用的空间开销大和时间慢。
空间:64位机器如果每页1024字节,那么一个页表要用64-10=54位空间来存放页表,而这个相当于2^20TB,根本不现实。而且对于多个应用程序,为了有效实施内存的隔离,每个程序对应各自的页表,n个程序就要用n个页表,更耗空间。
时间:既然页表很大,CPU的cache只有几mb,肯定放不下,只能放在内存里。访问一个内存单元需要访问页表加访问实际物理地址两次内存访问,内存访问并不快
- 解决方法
时间:缓存(TLB)
空间:间接访问(多级页表)
TLB,简单来说,这是个CPU里的缓冲,直接存好了常用的逻辑地址的页号p和物理地址的帧号f,如果命中,就不需要去查页表了。如果miss,则查表并更新到TLB中。32位系统,一个页是4kb,每平均访问4*1024次才能碰到一次要查页表,TLB的缺失就很小。

TLB miss之后,从页表中存到TLB中,x86就是完全由硬件完成,MIPS则有软件操作系统完成。
4.4 非连续内存分配 页表-二级,多级页表
多级页表(不一定要平均分,以平均分为例):
(注意,这个不对,引以为鉴)我们把一个n位的空间,分为k个n/k位的空间,第i个空间,寻址结果决定了下一个寻址的基址(即乘以一个2^((k-i)*n/k)的空间),具体:一级页表号p1 number通过一级页表查到的一级页表项是二级页表的起始地址,加上二级页表号p2 number得到的页表项,存的是frame number

对16位页表分成两个8位来说,一级页表项之间(即上图一级页表每往上走一格)相差256字节的整数倍(大概可以这样简单理解),代表二级页表的基址,然后二级页表的大小也是256字节。就很像一个棵树,一级页表每一项对应内存不同基址。每个基址开始存着一个耳机页表,看样子好像没有节省空间,但是实际上,如果p1表里面的驻留位resident bit是0,那么p2表就不需要空间了,这样实际上能节省极大空间,多级页表,就是每一级都能得出下一级有些空间不需要,实际上这可能是个很不平衡的树,但是就很省空间。
4.5反向页表
前面都是页号映射到帧号,反向页表是帧号映射到页号,这样反向页表就是和物理内存大小对应。使用的是页寄存器:

那么怎么从反向页表里面查找逻辑地址页号对应的帧号呢?可以用关联内存,通过查找反向页表里的内容,输出它的索引,就对应物理地址,然而这样开销巨大,因为这个实现的机理非常复杂,导致容量不能做很大,而且放到cpu外面内存开销更大。对大的关联存储器,速度反而会下降。

那么我们怎么办,用hash table查找
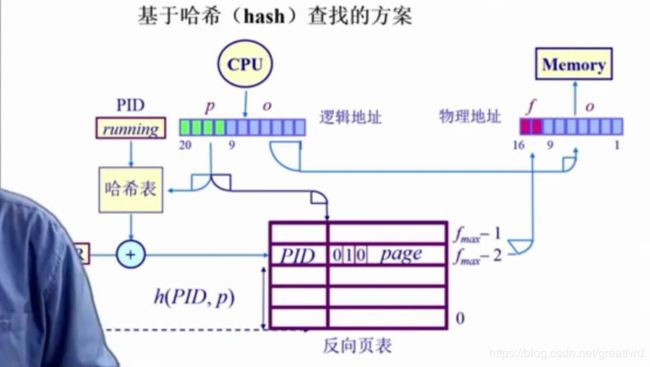
用hash函数,输入一个值得到输出,输入的值为page number,输出frame number,用硬件加速,可以加一个PID标识,加上页号page number,能够得到一个简洁的hash函数,算出帧号frame number
缺点:hash函数可能会出现多个帧号结果,就要通过PID来判断取哪个
部分高级CPU里面存在反向页表
5虚拟内存
内存不够,用到硬盘,覆盖技术,交换技术,虚存技术
-
覆盖技术

如果程序块之间没有相互调用(可简单理解为函数调用),则相互独立的块可以放在同一块内存,运行一个时其他的放在硬盘里,由软件程序员手动指定,如图两种覆盖方法,A,BC,DEF和A,BEF,CD -
交换技术

-
虚存技术
目标:不由程序员指定的自动完成更好的覆盖+只对程序部分内容进行的完成更好的交换
条件:程序的局部性原理,指程序在执行过程的一个较短周期内,指令和指令操作数的地址分别局限于一定区域
时间局部性,上述两点集中在一个较短时期;空间局部性,上述两点集中在一个较小区域
虚存:访问速度快,空间大,访问方便(不用手动调控)
考虑如下问题:

左边程序是先访问每一列,右边程序是先访问每一行
数组大小为4m,一页是4k,那么有1024页。结果如下:

在内存中,数组是按行排列的,也就是说,每一行大小是4k,就正好放在同一个页里面。那么,如果先读行,那就是第一次读出现异常,读入一页,然后要读1024次,才下一次缺页(TLB?),而如果先读页,那么每次都要重读,读完1024页又要读最开始的页,不仅慢,而且局部性差。
- 虚存技术的基本概念
把程序按照分段,分页,和虚存技术合并,也就是在程序局部性比较好的时候,只对页进行操作,先将应用程序当前需执行的部分调入内存,程序就可以开始执行。过程中,如果少了一些东西,那么算缺页,再把缺的部分调入,如果缺页的同时没空间了,再把一些不常用的放入硬盘。注意到这里如果程序局部性比较好,缺页率就很低,影响就很小。
- 虚拟技术的特征
空间大(硬盘提供支持)部分交换(按段或者按页)不连续性(物理内存分配不连续,逻辑地址不连续,因为唤入唤出可能把原本连续的虚拟地址变得不连续,操作系统会自己弥补)
- 虚拟技术的实现
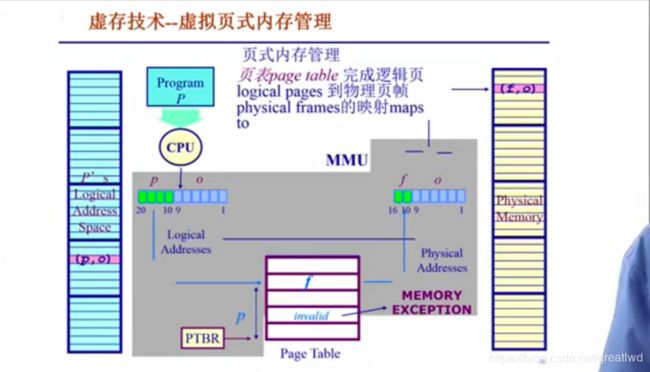
左侧逻辑地址空间,右侧物理地址空间,页表维护映射关系,页表项的索引是页号,内容是页帧号。页表项内除了页帧号,还有几个bit,表示存不存在等状态。当不存在时会产生异常,异常机制会被我们利用为一种很有效的虚拟技术手段。
虚存技术:在原本页式存储管理的基础上,增加请求调页和页面置换功能。请求调页:调入时是按页的;页面置换:唤入唤出操作。
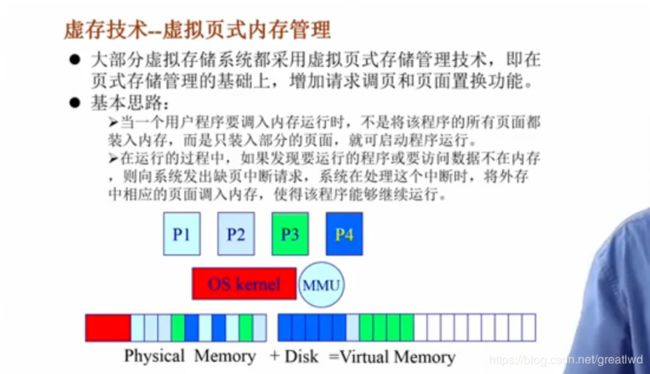
- 页表项添加几位来操作

驻留位:判断当前页是在内存还是外村,1是内存,0是外存,缺页将导致缺页中断。保护位:表示允许访问的种类。修改位:如果修改过,可能要存回硬盘。访问位:如果被访问过,则设置此位,用于页面置换算法,比如最近访问的就不要换,很久没访问就换。

如上图,左侧是逻辑地址的页表,其中索引是逻辑地址的页号,表项如下,其中x代表驻留位为0,数字代表驻留位为1而且偏移量为数字大小,比如最底下的0到4k这个页,页号是0,页项驻留位表示在主存中,偏移量是2,即,8k到12k区域。
对第一条指令,把虚拟的0地址的内容赋给一个寄存器,那么虚拟0地址对应页号是0,页表中是2,那么对应的就是2*4k = 8192
对第二条指令,虚拟地址为32780,页表中页号为8,对应的是X,不存在内存中的物理地址,产生缺页异常 - 缺页中断处理过程
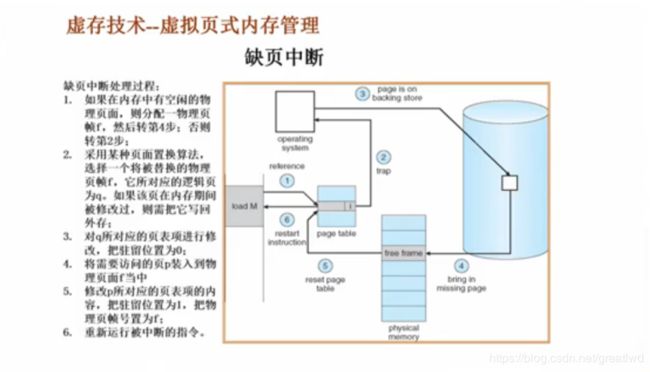
过程描述:
比如CPU要load一个内存,如果不存在内存里,即缺页,如果内存由空闲的物理页面,设帧号为f,转到第四步,将实际还在硬盘里的要load的逻辑地址页号为p的数据装入到内存帧f中,然后修改p对应的页表项的驻留位为1,页帧号为f。如果内存满,使用某种页面置换算法,选择一个页帧f,如果它在内存期间被修改过,由于内存断电不保存,还要把历史修改过的数据写到硬盘里,然后把f原本对应的页号q对应的页表项驻留位设为0,然后再转到4.
概况:内存没满直接分配新页,并由操作系统设好页表,内存满了把一个挪出去,注意保存后设好挪出去的页表,然后再像第一步挪进来,再设好挪进来的页表。
 q为对数据修改后要写进硬盘的概率,上式如果p很小,那么这两项可能能是同等数量级。
q为对数据修改后要写进硬盘的概率,上式如果p很小,那么这两项可能能是同等数量级。
6.1 最优页面置换算法
页面置换算法
功能:如果发生缺页,就要把你觉得不需要的页面换出去替换成需要的页面
目标:尽量减少页面的置换,因为硬盘的读写效率很低
像操作系统,这些需要常驻的内存,就要锁住,所以要加一个锁定位,lock bit
我们记录一个进程对页访问的轨迹,跟踪虚拟地址,重点是它的页号,因为访问同一页,不需要考虑偏移,因为同一页不会产生缺页中断。
最优页面置换算法(OPT):当一个缺页中断发生时,对保存在内存中的每个逻辑页面,计算下一次访问它时还需等待最长时间的那一页,把它置换出来。缺点:这个是理想的,因为你实际上不知道未来是怎么样的。作用,可以用来评估其他算法优劣。
总结来说,置换的页面是将来最长时间不需要的页面。

横坐标代表当前内存中的页面和导入的时间,纵坐标代表从当前状态开始的时间和要访问的页面,值是按照当前算法内存中的页面。红点代表发生缺页中断的节点,下面也是一样
复习一下课程逻辑:
为了应用程序更方便->虚拟地址和物理地址->连续分配产生碎片->分段分页非连续分配->分页为主,两个地址都用页(帧)号和偏移量表示->映射地址时,要查页表,速度慢开销大->TLB和多级页表和反向页表->逻辑地址>物理地址->虚存技术:请求调页和页面置换->页面置换算法
6.2 先进先出算法 FIFO
即当缺页中断发生时,对于当前内存中的每一个页面,置换出在内存中停留最久的页面。缺点:可能效果很差,不单独使用,经常混合使用。
流程见下图:缺页中断太多了 0 0

6.3 最近最久未被使用 least recently used LRU
当发生缺页中断时,置换的页面是最近的最久未被使用的页面,是一种用历史来预测未来的方法,前提是局部性原理,见下图:需要注意的是,我们从当前中断点往前找到每一页最近一次被访问的位置,然后从里面选择最久的那个,所以叫最近(所有页中)最久(的那个)置换。
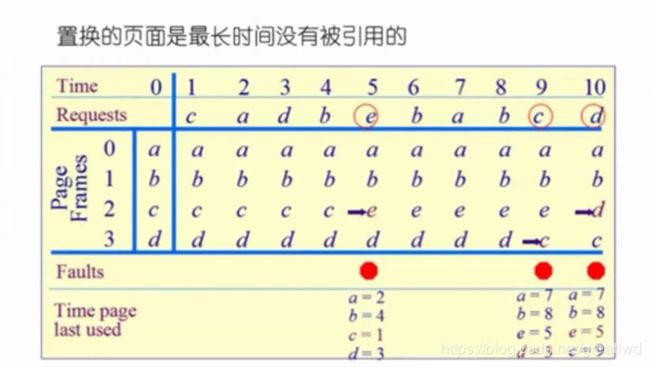
实现方法:
1、 链表,内部维护一个链表,对新访问的页面,从链表中删除后插入头部,即更新出最近的访问位置,当缺页中断时,链表尾部的就是要置换出的页面
2、 堆栈,同理,刚访问的页面,从栈中找到删除,然后放入栈顶,缺页中断时置换的页面是栈底页面

6.4时钟页面置换算法(clock算法)
LRU算法,精确记录最近最久的访问,要查找,耗时久,所以我们实际上不一定需要知道精确的访问时间,如果我们知道它最近有没有访问就行,那就好了。
时钟页面置换算法:每个页表项加入一个访问位,access bit,可以使0或者1,硬件和软件都能改变它的值。如果页面被访问,硬件会自动将其置1,然后我们把这些页按照一开始的顺序顺时针方向做一个循环链表,用一个指针,每次缺页中断时就开始扫描循环链表,如果当前指针指向的页acces bit是0,则把它置换,放入新的页面后对该新页面硬件自动置为1;如果是1,那就把它变成0(这里是操作系统来完成)。判断完后,指向下一个页。(即两种情况都要指向下一页)如果一圈都是1,那么循环一圈每个都变成0,然后又到第一个就把它置换出去,这个算法可以大概看成FIFO和LRU的结合体。


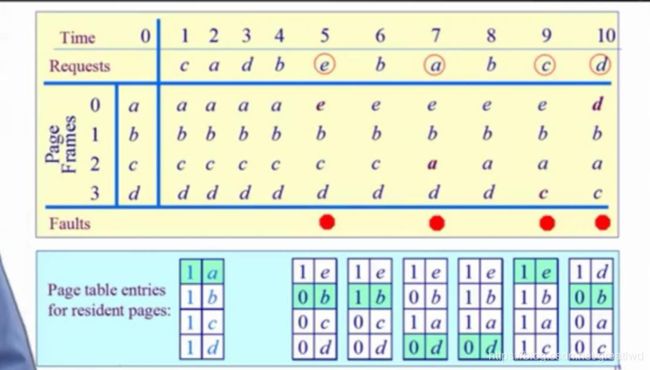
注意这里,每次缺页中断的指针是继承前一次的位置,如上图绿色的标志位置。
标志位的变化情况:
访问(1或0变成1),缺页,转到是0置换,是1就变成0跳到下一个。
我们可以形成一个画面,CPU疯狂的在内存中的页面跳来跳去,这时候循环链表的时钟指针是不动的,当形成缺页中断时,这时候时钟指针开始转动,处理,实际上也很快,然后处理好后,CPU又开始疯狂的跳来跳去,指针又不动了,只有发生缺页中断时开始转动。这样的画面有助于理解记忆。
6.5 二级机会法(enhanced clock algorithm)
我们在时钟页面置换算法中再加上一位,dirty bit,如果访问是写操作,那么access bit和dirty bit都置为1,如果是读操作,那么access bit是1,dirty bit是0。如下图:
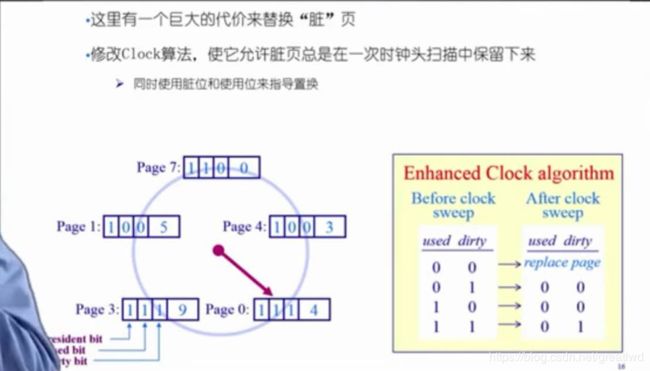
我们的思想是,写操作还要把内存中的部分存到硬盘里,如果把它置换出去,但是不停地写,那么每次对它进行写操作,都得把它再读进来,然后再写出去,这样会造成两倍开销,所以我们多给它一次机会,即上图右下角表格,每次缺页,时钟指针转到一个页面对其这两位进行这样的处理,重点是11变成01,也就是对刚写访问(也就是11)的文件多给它一次循环的机会,放到下一个循环再置换,所以叫二次机会法。
标志位的变化情况:
写访问(10或00变成11),读访问(10或00变成10),缺页,则按上表的规律。循环和更新指针的方法和clock方法类似。

巩固方法:可以对每个方法算上面表格的结果。
6.6 最不常用法(least frequently used,LFU)
当缺页中断发生时,选择访问次数最少的页面淘汰。
基本思路:设置一个记录该页被访问多少次的计数器,然后开销太大(比如需要很多位数),还有如果一个页进程开始时访问很多,但是现在基本不用了,按这个就一直会占用内存,实际可以置换出去。
改进方法:如果我们隔一段时间,把这个计数器左移一位,就是把它变小,对时间就可以大概查看分段的规律。
6.7 Belady现象和各方法比较
采用FIFO算法是,有时候分配物理页面数量增加,缺页率反而提高。如下图,物理页面是4,缺页9次,物理页面加1到5,缺页10次。图中使用的是FIFO的队列头尾,新来的放入尾。


不同算法的比较:


6.8局部页替换算法的问题,工作集模型
局部当然分配越多物理页越好,但是其他的程序分配的页就少了。
前面的局部页替换算法的前提都是局部性原理,如何对局部性原理进行定量分析呢?
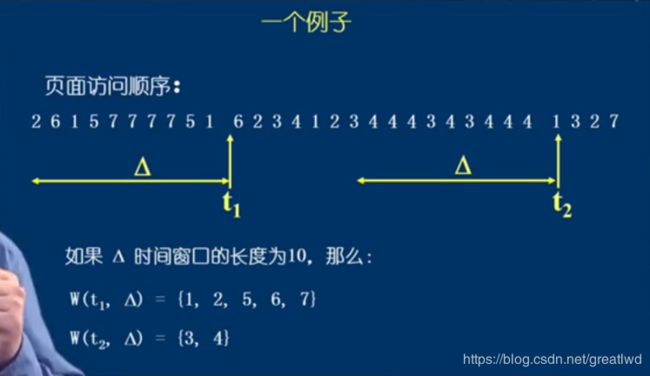
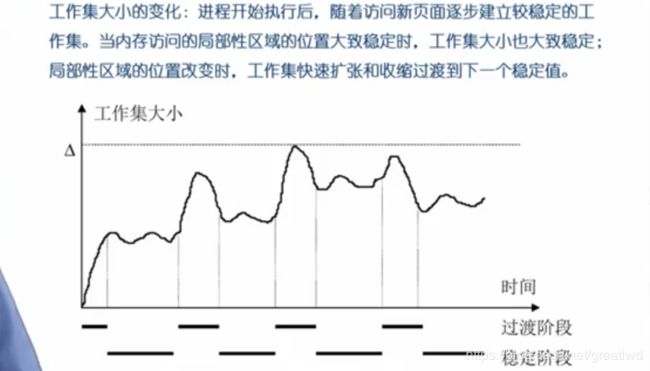
使用工作集模型。工作集和常驻集:

可以理解为一个框,这个框框住一段时间,如下图:

6.9两个全局置换算法
方法一:当出现缺页时,在工作集以外的页面淘汰掉

方法二:缺页率算法,简单来说,就是当缺页率高,那么证明应该读入更多的页面,增加工作集;如果缺页率低,应该腾出空间给其他进程,减小工作集。



当两次缺页之间时间大,那么就把这个时间差外的移除并加入缺失页,如果小,则仅加入缺失页。上图中下方的数字代表两次缺页时间差。
6.10 抖动问题

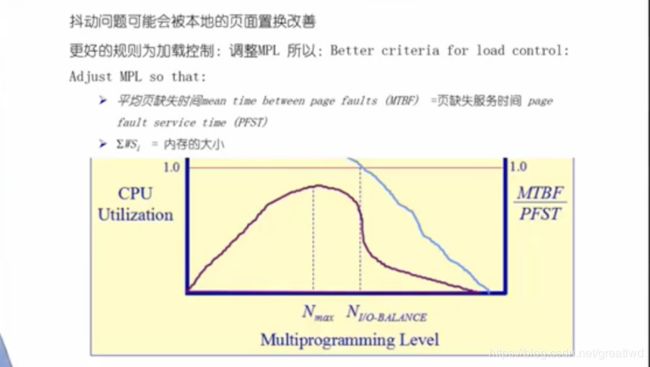
如果疯狂缺页,可能页面还没处理好又发生了缺页,那么久很慢了,所以上图是一个尽可能多的跑进程的同时又保证比较快的CPU运行的一个trade off折中。
7.1~7.4进程的定义,组成,特点,PCB
程序是一段代码,进程是代码动态运行后的运行过程,包括各个不同的部分,比如控制的状态啊,要使用的数据啊,等等,它的数据结构很复杂,叫进程控制块,PCB,里面包含各个不同的量给操作系统来操控管理进程。
7.5~7.7进程管理:进程的生命期管理,进程的状态模型,进程的挂起
进程创建start:操作系统创建一个最初始进程,由它创建接下来的所有进程;根据用户要求创建进程;进程自身创建子进程。
进程状态:new,ready,running,blocked
ready:已获取处理机以外所有的资源;running:获取处理机开始运行;blocked:出现中断比如读写文件比如等待指令,进入阻塞;new:ready之前和创建后之间的状态;程序并发地在不同的进程切换,比如一个程序阻塞的话就转换到其他进程,加快效率。一个CPU不能并行。

进程的挂起:从内存转到外存


我们使用方便删除插入的队列来控制进程的各个状态,不同的状态产生不同的队列,每个PCB根据自己的状态在不同的队列之间切换,按照优先级插入


7.8为什么使用线程
比如一个听mp3进程,如下图,可能一个函数后到下一个函数要等,听歌可能就不流畅,我们把它分成三个分开的部分,可以并发地执行,这一点和进程相似,但是像7.1~7.3中所说,为了安全,进程不能互相访问各自内存,而这里我们要访问同一块内存(这三部分属于同一个进程),所以线程就是能并发执行并且共享资源的过程。


