Titanic
不管学习什么,都是觉得原理好简单,但是实际操作起来好难,其实也不是难,就是觉得麻烦。尤其是让我理解可以,就是不想动手去写代码。这次对于kaggle题目也是如此,但是这样实在不好,所以强逼着自己来写代码,来做个自己的整理。
一、数据分析
1.读取数据
下载的train、test文件都是csv格式,用Python的Pandas包读取。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas import DataFrame, Series
data_train = pd.read_csv("/home/futao/Downloads/all/train.csv")
data_test = pd.read_csv("/home/futao/Downloads/all/test.csv")
data_train.head()
#显示train文件的前几行
print(data_train.head())
#统计train文件的数据信息
print(data_train.info())
#显示test文件的数据信息
print(data_test.info())train信息:
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)test信息:
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
从上面的信息可以看出训练数据和测试数据都存在缺失值,Age和Cabin 的缺失值最多,Fare 和Embarked的缺失值较少,具体怎么处理在下面会讨论。接下来先进行数据的分析。
2.分析属性与幸存之间的关系
为了顺便熟悉Python的数据处理方法,接下来会用两种方法来展示关系图。
- 不同属性对获救人数影响的对比
- 不同属性的获救概率
(1) 船舱等级对获救的影响分析
a.不同等级对获救人数的影响
#分析Pclass对Survived的影响
#dataframe的行索引作为x轴,将Pclass作为行索引
#Survived作为比较值
Sur_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Sur_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df_Pclass = DataFrame({'Survived': Sur_1, 'no_Survived': Sur_0})
print(df_Pclass)
df_Pclass.plot(kind='bar')
plt.title("different class")
plt.xlabel("Pclass")
plt.ylabel("num people")
plt.show()

可见,等级1获救的可能性更大,等级3的获救可能最最小。等级制度还是很明显的。
b.不同等级的获救概率图
获得概率主要使用pandas的分组运算groupby,顺便学习了解了一下groupby的使用。
(1)统计不同等级获救的人数
#s = data_train.groupby(['Pclass', 'Survived'])['Pclass'].count()
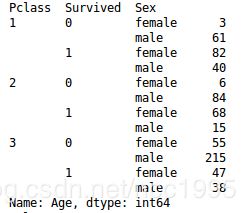
s = data_train.groupby(['Pclass', 'Survived', 'Sex'])['Age'].count()
data.groupby()的使用:从得到的结果可以分析出,先将数据按groupby中的第一个参数分类,再把每一类分别按第二个属性分类,以此类推。得到的统计数据待统计的数据属性与分类结果的匹配。
(2) 求出每个等级获救的概率
data_train[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
将Survived按Pclass分类,由于Survived采用0和1来表示,所以直接求均值就是获救的概率。
求均值可以用上面代码来写,也可以用下面代码,区别在于有没有提前将Pclass的数据提取出来备用。
data_train[['Survived']].groupby(data_train['Pclass']).mean().plot.bar()
上面是groupby的简单总结。接下来是画出概率图。
s = data_train.groupby(['Pclass', 'Survived'])['Pclass'].count()
print(s)
data_train[['Pclass', 'Survived']].groupby(['Pclass']).mean().plot.bar()
plt.show()
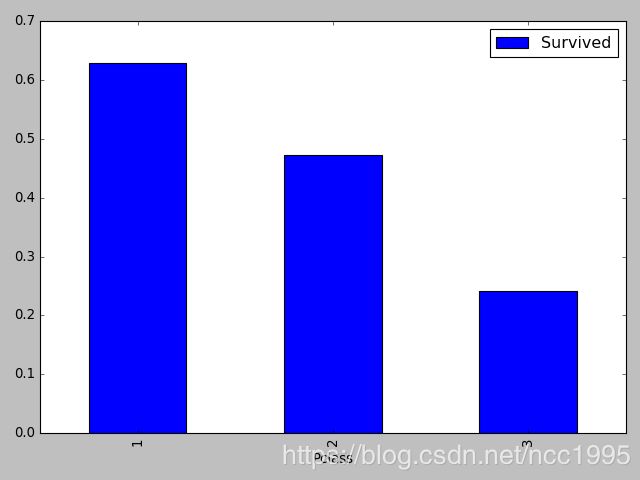
概率图可以更加直观的看出不同等级的获救可能大小。
(2) 性别对获救与否的影响
a.不同性别获救人数的对比
#思路类似不同等级
Sur_Sex0 = data_train.Sex[data_train.Survived == 0].value_counts()
Sur_Sex1 = data_train.Sex[data_train.Survived == 1].value_counts()
df_sex = DataFrame({'Survived': Sur_Sex1, 'no_Survived':Sur_Sex0})
print(df_sex)
df_sex.plot(kind='bar')
plt.title("different Sex")
plt.xlabel("Sex")
plt.ylabel("number")
plt.show()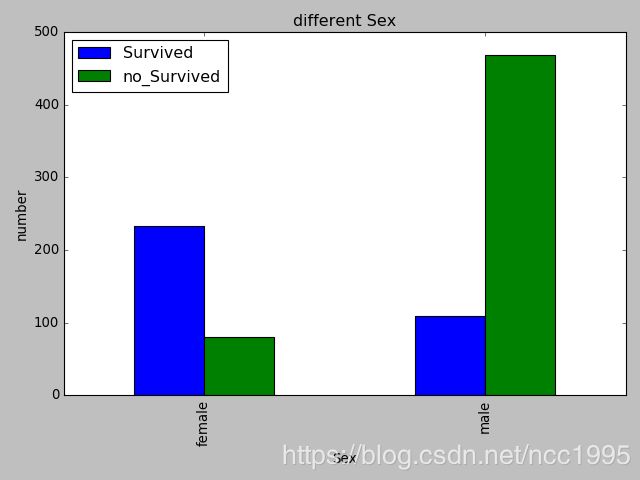
b.不同性别获救概率大小
#获救概率分析
#分别统计男女的获救人数
#再将获救人数通过性别进行分类计算均值
num = data_train.groupby(['Sex', 'Survived'])['Sex'].count()
print(num)
data_train[['Sex', 'Survived']].groupby(['Sex']).mean().plot(kind='bar')
plt.title('different Sex')
plt.ylabel('percent')
plt.show()

原来,女性的获救概率超出男性这么多!
(3) 兄弟姐妹对获救影响
a.有无兄弟姐妹对获救与否人数对比
Sur_0 = data_train.SibSp[data_train.Survived == 0].value_counts()
Sur_1 = data_train.SibSp[data_train.Survived == 1].value_counts()
print(Sur_0)
print(Sur_1)
df_SibSp = DataFrame({'Survived': Sur_1, 'no_Survived': Sur_0})
df_SibSp.plot(kind='bar')
plt.title('different SibSp')
plt.xlabel('SibSp')
plt.ylabel('number of people')
plt.show()

从得到的图来看感觉影响不大,接下来不区分兄弟姐妹个数,只讨论有无来看一下。
def sta(series):
no_zero = 0
for i in series.index:
if i != 0:
no_zero = series[i] +no_zero
else:
zero = series[i]
s1 = Series([zero, no_zero], index=[0, 1])
return s1
Sur_0 = data_train.SibSp[data_train.Survived == 0].value_counts()
Sur_1 = data_train.SibSp[data_train.Survived == 1].value_counts()
s_0 = sta(Sur_0)
s_1 = sta(Sur_1)
df_SibSp1 = DataFrame({'Survived': s_1, 'no_Survived': s_0})
df_SibSp1.plot(kind='bar')
plt.title('have Sibsp?')
plt.xlabel('SibSp')
plt.ylabel('number of people')
plt.show()

没有找到直接统计Serise索引0与非0的办法,只好自己写了一个函数来统计,这么来看的话有没有兄弟姐妹还是有一定的影响的,下面再来看看更直观的概率图。
b.有无兄弟姐妹获救概率大小
- 插入一个小广告,用plt画图的两种方法总结。
#不用先设定图纸大小
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.subplot(122)
#先设定图纸大小
fig = plt.figure()
plt.subplot2grid((2, 3), (0, 0))
下面是查看获救概率的代码:
plt.figure(figsize=(10, 5))
sibSp0 = data_train[data_train['SibSp'] == 0]
sibSp1 = data_train[data_train['SibSp'] != 0]
plt.subplot(121)
sibSp0['Survived'].value_counts().plot.pie(labels=['no_Survived', 'Survived'], autopct='%0.1f%%')
plt.xlabel('no_SibSp')
plt.subplot(122)
sibSp1['Survived'].value_counts().plot.pie(labels=['no_Survived', 'Survived'], autopct='%0.1f%%')
plt.xlabel('SibSp')
plt.title('have Sibsp?')
plt.show()

概率图,可以更加直观的 看出有兄弟姐妹的获救概率更加大一些。
(4) 有无父母与小孩
完全类似兄弟姐妹。
a. 看有无父母孩子对获救人数的对比
Sur_0 = data_train.Parch[data_train.Survived == 0].value_counts()
Sur_1 = data_train.Parch[data_train.Survived == 1].value_counts()
df_SibSp1 = DataFrame({'Survived': Sur_1, 'no_Survived': Sur_0})
df_SibSp1.plot(kind='bar')
plt.title('have Parch?')
plt.xlabel('Parch')
plt.ylabel('number of people')
plt.show()
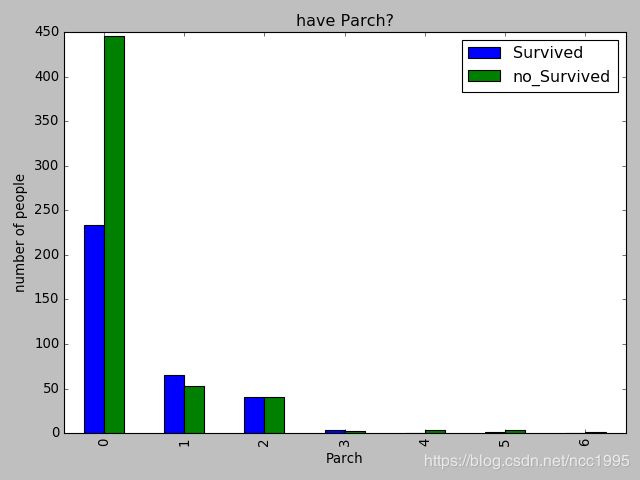
从这里面看的话,稍微能看出来一些信息,但是并不直观,下面直接从有没有孩子这个角度来区分。
def sta(series):
no_zero = 0
for i in series.index:
if i != 0:
no_zero = series[i] +no_zero
else:
zero = series[i]
s1 = Series([zero, no_zero], index=[0, 1])
return s1
Sur_0 = data_train.Parch[data_train.Survived == 0].value_counts()
Sur_1 = data_train.Parch[data_train.Survived == 1].value_counts()
s_0 = sta(Sur_0)
s_1 = sta(Sur_1)
df_SibSp1 = DataFrame({'Survived': s_1, 'no_Survived': s_0})
df_SibSp1.plot(kind='bar')
plt.title('have Parch?')
plt.xlabel('Parch')
plt.ylabel('number of people')
plt.show()
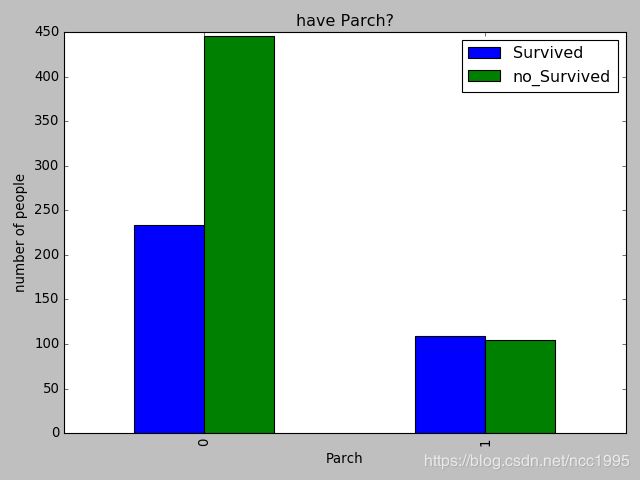
1代表有孩子,0代表没有孩子,差别还是蛮大的。
b.有无父母孩子的获救概率
plt.figure(figsize=(10, 5))
sibSp0 = data_train[data_train['Parch'] == 0]
sibSp1 = data_train[data_train['Parch'] != 0]
plt.subplot(121)
sibSp0['Survived'].value_counts().plot.pie(labels=['no_Survived', 'Survived'], autopct='%0.1f%%')
plt.xlabel('no_Parch')
plt.subplot(122)
sibSp1['Survived'].value_counts().plot.pie(labels=['no_Survived', 'Survived'], autopct='%0.1f%%')
plt.xlabel('Parch')
plt.title('have Parch?')
plt.show()

可以看出影响还是蛮大的。
(5) 登船港口对获救的影响
a.不同港口获救人数对比
sur_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
sur_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
print(sur_0)
df = DataFrame({'survived:': sur_1, 'no_survived':sur_0})
print(df)
df.plot(kind='bar')
plt.xlabel('different embark')
plt.ylabel('number of people')
plt.show()

可以看出不同港口获救情况还是很不一样的。
b.不同港口获救概率对比
t = data_train.groupby(['Embarked', 'Survived'])['Embarked'].value_counts()
print(t)
r = data_train[['Embarked', 'Survived']].groupby(['Embarked']).mean()
print(r)
r.plot(kind='bar')
plt.show()
从概率图来看,差别还算大吧。
(6) 票价对获救的影响
将票价进行分区间处理,不同区间人数大致相同。
data_train['difFare'] = pd.qcut(data_train.Fare, 4)
print(data_train['difFare'].value_counts())
res = data_train[['difFare', 'Survived']].groupby(['difFare']).mean()
print(res)
res.plot(kind='bar')
plt.show()得到的分区间结果为
(7.91, 14.454] 224
(-0.001, 7.91] 223
(31.0, 512.329] 222
(14.454, 31.0] 222
Name: difFare, dtype: int64
人数,大致相同,而四个区间的获救概率分别为
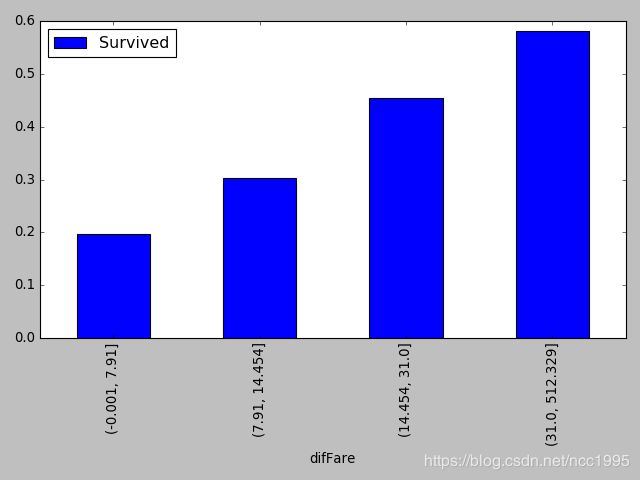
可以看出两个信息吧,买超低票价的人普遍多,但是获救概率很低。所以票价对获救与否影响还是比较大的。
(7) 年龄对获救的影响
最后再考虑的就是信息不全的两个特征了,Age和Cabin。首先考虑年龄,年龄的话未知的信息较少,所以可以把已知信息当成训练样本,未知信息当成测试样本来处理,特征采用其他的数值特征。有很多处理缺失值的办法,我觉得这是比较靠谱的一个办法了。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
def SetMissingAges(data):
data_num = data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
#print(data_num)
known_Age = data_num[pd.notnull(data_num.Age)].as_matrix()
#print(' known ', known_Age)
notknown_Age = data_num[pd.isnull(data_num.Age)].as_matrix()
#print(notknown_Age)
train_X = known_Age[:, 1:]
train_y = known_Age[:, 0]
test_X = notknown_Age[:, 1:]
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(train_X, train_y)
pre_Ages = rfr.predict(test_X)
data.loc[(data.Age.isnull()), 'Age'] = pre_Ages
return data
if __name__ == '__main__':
data = pd.read_csv("/home/futao/Downloads/all/train.csv")
data = SetMissingAges(data)
print(data[data.Age.isnull()])处理好年龄后进行分析。由于年龄的值多,范围也大,我同样采用分区间处理。
listbins = [0, 18, 30, 55, 80]
data = SetMissingAges(data_train)
data['difAge'] = pd.cut(data.Age, bins=listbins)
print(data['difAge'].value_counts())
per = data[['difAge', 'Survived']].groupby(data.difAge).mean()
print(per)
per.plot(kind='bar')
plt.show()(18, 30] 349
(30, 55] 345
(0, 18] 155
(55, 80] 42
Name: difAge, dtype: int64
采用的是这几个区间,这几个区间基本代表了少年,青年,中年与老年四个阶段吧,当然我有稍微改变中年阶段的取值,发现变化并不大,所以说明这阶段的获救概率还是蛮高的。

可以看出少年获救概率最高,其次是中年。
(8) Cabin对获救的影响
Cabin的缺失值非常多,所以 可以把是否具有这一特征作为一个条件来判断。
def SetCabinType(data):
data.loc[data.Cabin.notnull(), 'Cabin'] = 'yes'
data.loc[data.Cabin.isnull(), 'Cabin'] = 'no'
return datadata = SetCabinType(data_train)
per = data[['Cabin', 'Survived']].groupby(['Cabin']).mean()
print(per)
per.plot(kind='bar')
plt.show()
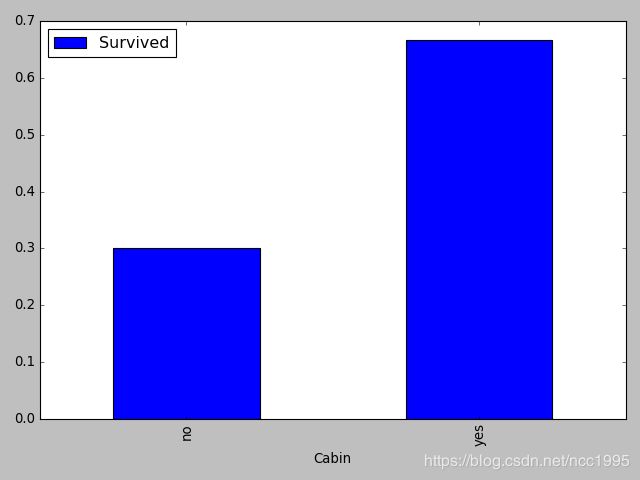
可见,有无Cabin对获救影响还是蛮大的。
最后,还值得分析的就是姓名一项,里面包含了很多称呼信息,不过我们先采用现有的数据特征预测一下。
2.数据处理
- 数值型特征进行归一化处理,使训练模型更加稳定。
- 非数值型特征要转化为数值型特征。
(未完,参考链接后面会附上)