论文阅读:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
论文地址:https://arxiv.org/abs/1703.03400
代码:https://github.com/cbfinn/maml
发表:ICML 2017

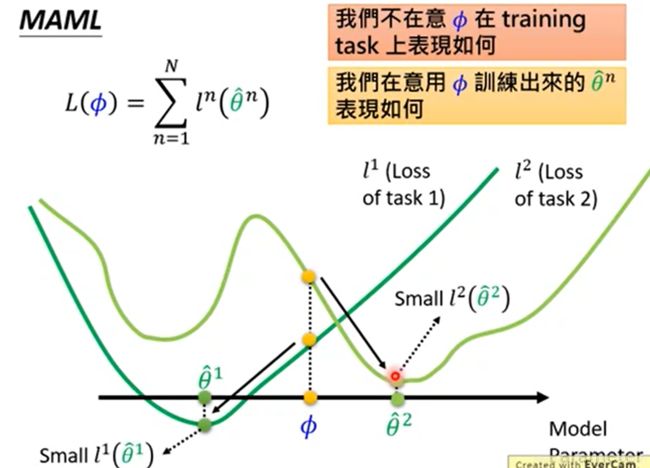
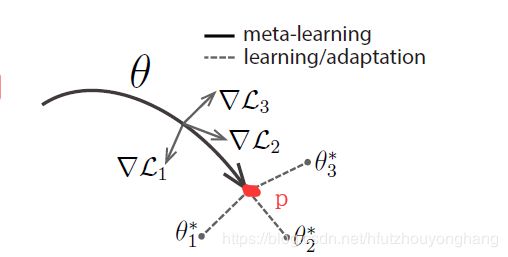
假设图里面,Task_1, Task_2, Task_3这3个点,是三个Task对应的最佳参数的位置。而我们的优化从A点(灰色点)开始。如果针对Task 1, 2, 3单独作fine-tune(或者adaption), 那参数优化的方向分别为Adaption_1, Adaption_2和 Adaption3.
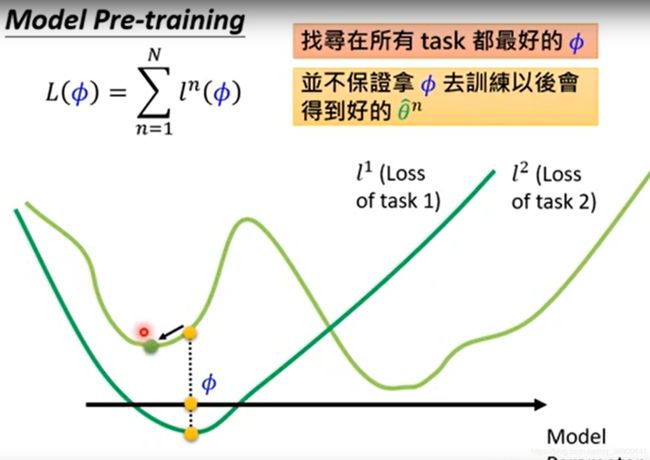
在普通的Pretraining的过程中(下面这张图), Adaption是完全不考虑的,它只会找到离Task1,2,3都距离最短的那个点。但这个点不能保障再做完Adaption_1~Adaption_3之后,他们各自能离最佳点最近
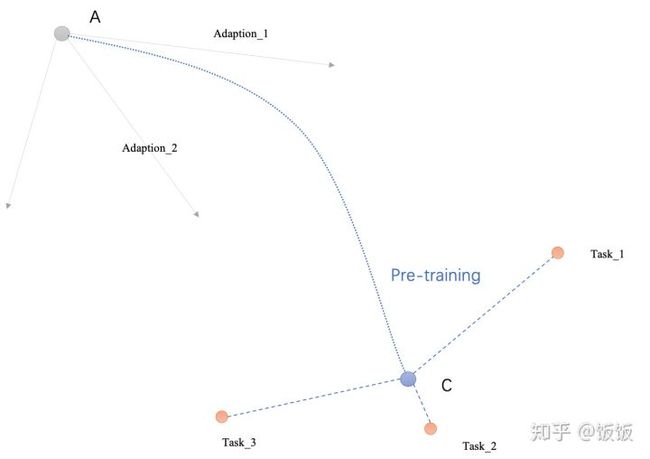
在Meta Learning(MAML)的过程中(下面这张图),优化器带着原点以及Adaption_1 ~ Adaption_3三条线一起移动,他的目标是找到一个位置,使得Adaption_1 ~ Adaption_3三条线的末端刚好离Task_1 ~ Task_3最近

https://www.zhihu.com/question/357515885
摘要:
这篇文章提出了一种与模型无关(model-agnostic)的元学习算法,即它可以与任何经过梯度下降训练的模型兼容,并适用于各种不同的学习,包括分类、回归和强化学习。而元学习的目的是在各种学习任务上训练一个模型,使得在少量训练样本的情况下解决新的学习任务,同样也是解决小样本学习的方法。MAML的关键思想在于训练模型的初始参数,使得模型的参数经过几步梯度下降就可以适应新任务,并表现出良好的泛化性能。实际上,这种方法比微调容易,并在两种小样本数据集上表现出sota性能, 并加速了用神经网络策略对梯度增强学习的微调。
1 介绍
本文提出了一种通用的MAML算法,它可以直接应用于任何学习问题和经过梯度下降训练的模型。作者重点在深度神经网络模型,但也说明了这种方法能轻松地处理不同的体系结构和不同的问题,包括分类、回归和梯度强化学习。 在元学习中,训练后的模型的目标是从少量的新数据中快速学习一个新的任务,并且该模型由元学习者(meta-learner)训练,以便能够学习不同的任务。 作者方法的关键思想是训练模型的初始参数,使得模型的参数经过几步梯度下降就可以适应新任务,并表现出良好的泛化性能。与之前的元学习方法不同,我们的算法不扩展学习参数的数量,也不对模型体系结构施加约束。
这项工作的主要贡献是一个简单的模型和任务无关的元学习算法,它训练一个模型的参数,使得少量的梯度更新将导致对新任务的快速学习。
而为什么总是看到few-shot在用meta-learning的setting呢?因为确实巧妇难为无米之炊,新任务如果真的只有一两个样本可以训练,这个问题几乎无解。而meta-learning则提供了合理的假设: 虽然我没有目标任务上的大量训练样本,但是我有大量相似任务的少量训练样本作为代偿。
2 MAML
Meta-Learning的目标在于从多个不同的学习任务(这些任务只包含少量训练样本)中,学习到一个模型,这个模型能够快速学习如何解决一个只含有少量训练样本的新任务。更通俗的来说,Meta-Learning的关键在于让机器学习如何去“学习”。我们的目标是训练能够实现快速适应的模型,这个问题通常被形式化为few-shot learning。
2.1 元学习问题设置(模型任务设定)
小样本元学习的目标是训练一个模型,它可以只使用几个数据点和训练迭代来快速适应一个新的任务。 为了实现这一点,模型或学习者在一组任务的元学习阶段被训练,这样训练的模型就可以只使用少量的例子快速适应新的任务。 实际上,元学习问题将整个任务视为训练的例子。
我们考虑一个模型,表示f,它将观测值x映射到输出a。 在元学习过程中,模型被训练成能够适应大量或无限数量的任务。任务可以形式化的定义为T={L(x1,a1,...,xH,aH),q(x1),q(xt+1|xt,at),H},由损失函数L、初始观测值的分布q(x1)、迁移分布q(xt+1|xt,at)和任务长度H组成。该模型可以通过在每个时间t处选择输出来生成长度为H的样本。 损失L(x1,a1,...,xH,aH)→R提供特定于任务的反馈,
大致训练过程:在元学习场景中,考虑任务p(T)上的分布。 在K样本学习设置中,对模型进行训练,从p(T)中学习一个新的任务Ti,再从qi中提取K个样本,并由Ti生成反馈LTi。 在元训练过程中,从p(T)中采样任务Ti,用K个样本训练模型,反馈来自Ti中相应的损失LTi,然后在Ti的新样本上进行测试。 然后通过考虑来自qi的新数据上的测试误差相对于参数的变化来改进模型f。 实际上,抽样任务Ti上的测试误差是元学习过程的训练误差。 在元训练结束时,从p(T)中采样新任务,并通过从K个样本学习后的模型性能来测量元性能。 通常,用于元测试的任务是在元训练期间执行的。
2.2 MAML算法
本文提出了一种方法,可以通过元学习来学习任何标准模型的参数,以便为快速适应模型做好准备。 这种方法背后的直觉是,一些内部表示比其他表示更容易转移。例如,神经网络可以学习广泛适用于p(T)中所有任务的内部特征,而不是单个任务。我们如何才能鼓励出现这样的通用表示?我们对这个问题采取了一种明确的方法:在新任务上使用基于梯度下降的fine-tune的方式去训练模型,因此我们将以这样的方式学习一个模型:这种基于梯度的学习规则可以在从p(T)提取的新任务上快速进行,而不会过度拟合。实际上,我们的目标是找到对任务变化敏感的模型参数,当沿着损失梯度的方向改变时,使得参数的微小变化将对从p(T)中提取的任何任务的损失函数产生很大的改善(见图1)。我们对模型的形式没有任何假设,只是假设它是由某个参数向量θ参数化的,并且θ中的损失函数足够光滑,我们可以使用基于梯度的学习技术。
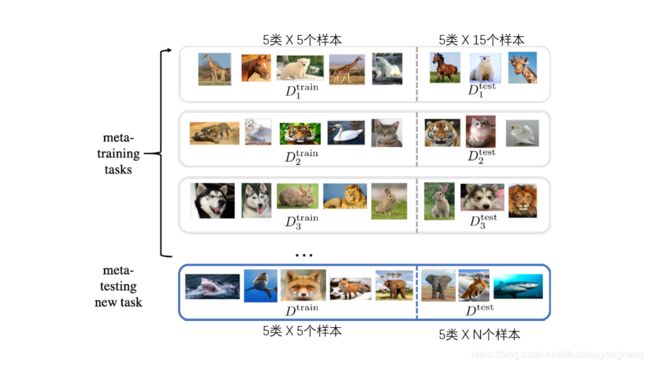
在一个task中,使用左边的训练集做5次SGD的过程,再使用右边的测试集计算test error,在meta-learning过程中,把一个batch的4个task的test error平均一下作为loss再去进行优化。这个过程结束后,神经网络的权重到达了下图中的P点
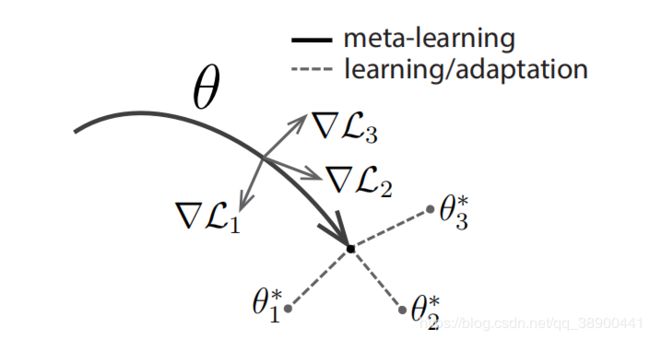
图一: 模型无关元学习算法(MAML)的图,它优化了一个能够快速适应新任务的表示θ。
形式上,我们考虑一个参数化函数fθ表示的模型。当适应新任务Ti时,模型的参数θ变为θ‘。在我们的方法中,使用任务Ti上的一个或多个梯度下降更新来计算更新的参数向量θ’。例如,当使用一个梯度更新时,步长α可以固定为超参数
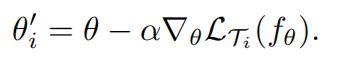
通过优化fθ‘相对于p(T)抽样任务θ的性能来训练模型参数。具体来说,元目标如下
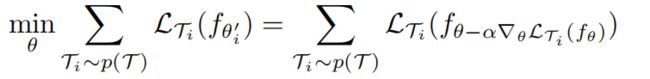
注意,元优化是对模型参数θ执行的,而目标是使用更新的模型参数θ‘计算的。实际上,我们提出的方法旨在优化模型参数,使得在一个新任务上的一个或少量梯度步骤将在该任务上产生最大有效的行为。
通过随机梯度下降(SGD)进行跨任务的元优化,使得模型参数θ更新如下:其中β是元学习率。

算法1概述了完整的算法:

该算法实质上是MAML预训练阶段的算法,目的是得到模型Mmeta。
首先来看两个Require
第一个Require指的是在元训练集中task的分布。结合我们在上一小节举的例子,这里即反复随机抽取task ,形成一个由若干个(e.g., 1000个) T组成的task池,作为MAML的训练集,也叫task的分布。有的小伙伴可能要纳闷了,训练样本就这么多,要组合形成那么多的task,岂不是不同task之间会存在样本的重复?或者某些task的query set会成为其他task的support set?没错!就是这样!我们要记住,MAML的目的,在于fast adaptation,即通过对大量task的学习,获得足够强的泛化能力,从而面对新的、从未见过的task时,通过fine-tune就可以快速拟合。task之间,只要存在一定的差异即可。再强调一下,MAML的训练是基于task的,而这里的每个task就相当于普通深度学习模型训练过程中的一条训练数据。一个task由support-set+query-set组成。
第二个Require就很好理解啦。step size其实就是学习率,读过MAML论文的小伙伴一定会对gradient by gradient这个词有印象。MAML是基于二重梯度的,每次迭代包括两次参数更新的过程,所以有两个学习率可以调整。
接下来,就是算法流程:
步骤1,随机初始化模型的参数,没什么好说的,任何模型训练前都有这一步。
步骤2,是一个循环,可以理解为一轮迭代过程或一个epoch,当然啦预训练的过程是可以有多个epoch的。
步骤3,相当于pytorch中的DataLoader,即随机对若干个(e.g., 4个)task进行采样,形成一个batch。
步骤4~步骤7,是第一次梯度更新的过程。注意这里我们可以理解为copy了一个原模型,计算出新的参数,用在第二轮梯度的计算过程中。我们说过,MAML是gradient by gradient的,有两次梯度更新的过程。步骤4~7中,利用batch中的每一个task,我们分别对模型的参数进行更新(4个task即更新4次)。注意这一个过程在算法中是可以反复执行多次的,伪代码没有体现这一层循环,但是作者再分析的部分明确提到" using multiple gradient updates is a straightforward extension"。
步骤5,即对利用batch中的某一个task中的support set,计算每个参数的梯度。在N-way K-shot的设置下,这里的support set应该有NK个。作者在算法中写with respect to K examples,默认对每一个class下的K个样本做计算。实际上参与计算的总计有NK个样本。这里的loss计算方法,在回归问题中,就是MSE;在分类问题中,就是cross-entropy。
步骤6,即第一次梯度的更新。
步骤4~步骤7,结束后,MAML完成了第一次梯度更新。接下来我们要做的,是根据第一次梯度更新得到的参数,通过gradient by gradient,计算第二次梯度更新。第二次梯度更新时计算出的梯度,直接通过SGD作用于原模型上,也就是我们的模型真正用于更新其参数的梯度。
步骤8即对应第二次梯度更新的过程。这里的loss计算方法,大致与步骤5相同,但是不同点有两处。一处是我们不再是分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降SGD。另一处是这里参与计算的样本,是task中的query set,在我们的例子中,即5-way*15=75个样本,目的是增强模型在task上的泛化能力,避免过拟合support set。步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
以上就是MAML预训练得到 M meta的全部过程,是不是很简单呢?事实上,MAML正是因为其简单的思想与惊人的表现,在元学习领域迅速流行了起来。接下来,应该是面对新的task,在 Mmeta的基础上,精调得到M fin-tune 的方法。原文中没有介绍fine-tune的过程,这里我向小伙伴们简单介绍一下。
fine-tune的过程与预训练的过程大致相同,不同的地方主要在于以下几点:
- 步骤1中,fine-tune不用再随机初始化参数,而是利用训练好的 Mmeta初始化参数。
- 步骤3中,fine-tune只需要抽取一个task进行学习,自然也不用形成batch。fine-tune利用这个task的support set训练模型,利用query set测试模型。实际操作中,我们会在元测试集上随机抽取许多个task(e.g., 500个),分别微调模型Mmeta ,并对最后的测试结果进行平均,从而避免极端情况。
- fine-tune没有步骤8,因为task的query set是用来测试模型的,标签对模型是未知的。因此fine-tune过程没有第二次梯度更新,而是直接利用第一次梯度计算的结果更新参数。
3 MAML种类
在这一节中,将讨论元学习算法在监督学习和强化学习中的具体实例。这两个领域在损失函数的形式和任务如何生成数据并呈现给模型方面有所不同,但在这两种情况下都可以应用相同的基本适应机制。
3.1 监督回归与分类
在有监督任务领域,少样本学习得到很好的研究,其目标是仅从该任务的几个输入/输出对中学习一个新函数,使用来自类似任务的先验数据进行元学习。在少样本回归中,目标是在对具有类似统计特性的多个函数进行训练后,仅从从该函数采样的少数数据点预测连续值函数的输出。
为了在第2.1节中的元学习定义的上下文中形式化有监督回归和分类问题,我们可以定义水平线 H=1并在xt上删除时间步长下标,因为模型接受单个输入并产生单个输出,而不是一系列输入和输出。任务Ti从qi生成K i.i.d。观测值x来自qi,任务损失由模型的x输出与该观测和任务的相应目标值y之间的误差表示。
用于监督分类和回归的两个常用损失函数是交叉熵和均方误差(MSE),我们将在下面描述;不过,也可以使用其他监督损失函数。对于使用均方误差的回归任务,损失的形式为:
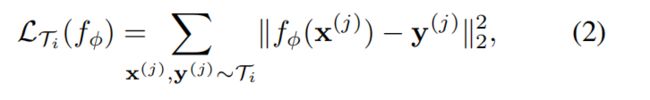
其中x(j),y(j)是从任务Ti采样的输入/输出对。在K-shot回归任务中,为每个任务提供K个输入/输出对用于学习。
同样,对于具有交叉熵损失的离散分类任务,损失的形式为:

根据传统的术语,K-shot分类任务使用每个类的K个输入/输出对,对总共NK个数据点进行N向分类。给定任务p(Ti)上的分布,这些损失函数可以直接插入到第2.2节中的方程中以执行元学习,如算法2所述。

3.2 强化学习
在强化学习(RL)中,少样本元学习的目标是能够使用少量的测试设置经验快速获取新测试任务的策略。一项新的任务可能涉及到实现一个新的目标或在一个新的环境中成功地完成一个先前训练过的目标。例如,一个agent可能学会快速找出如何导航迷宫,这样,当面对新迷宫时,它可以仅用少量样本可靠地到达出口。
每个RL任务Ti包含一个初始状态分布qi(x1)和一个转移分布qi(xt+1jxt;at),并且损失LTi对应于(负)奖励函数R。 因此,整个任务是一个具有水平H的马尔可夫决策过程(MDP), 其中,学习者被允许查询有限数量的样本轨迹,以便进行少样本学习。MDP的任何方面都可能在p(T)中跨任务发生变化。正在学习的模型fθ是一种策略,它在每个时间步长t 属于{1;::;H}时从状态xt映射到操作上的分布。任务Ti和模型fφ的损失形式如下

在K-shot强化学习中,fθ和任务Ti(x1;a1;::xH)的K卷展和相应的奖励R(xt;at)可用于适应新的任务Ti。
由于动态未知,期望奖励一般是不可微的,因此我们使用策略梯度方法来估计模型梯度更新和元优化的梯度。由于策略梯度是一种on-policy算法,因此在fθ的自适应过程中,每个额外的梯度步骤都需要从当前策略fθi’中获取新的样本。我们在算法3中详细说明了算法。该算法与算法2的结构相同,主要区别在于步骤5和步骤8需要从与任务Ti相对应的环境中采样轨迹。该方法的实际实现还可以使用最近为策略梯度算法提出的各种改进,包括状态或动作相关基线和信任区域(Schulman等人,2015)。

4 相关工作
本文提出的方法解决了元学习的一般问题,其中包括少样本学习。元学习的一种流行方法是训练元学习者,学习如何更新学习者模型的参数。该方法已应用于学习优化深层网络,以及学习动态变化的递归网络。最近的一种方法学习了权重初始化和优化器,用于少样本图像识别。与这些方法不同,MAML学习者的权重是使用梯度而不是学习更新来更新的;我们的方法不引入额外的元学习参数,也不需要特定的学习者架构。
少样本分类的一个成功方法是学习使用孪生网络或重复注意机制(recurrence with attention mechanisms)。这些方法产生了一些最成功的结果,但很难直接推广到其他问题,如强化学习。相反,我们的方法对模型的形式和特定的学习任务是不可知的。
元学习的另一种方法是在许多任务上训练记忆模型,在这些任务中,反复学习者被训练以适应新任务的展开。此类网络已应用于少数镜头图像识别和学习“快速”强化学习代理。实验表明,该方法在few-shot分类上优于递归方法。此外,与这些方法不同,我们的方法只是提供了一个很好的权重初始化,并对学习者和元更新使用相同的梯度下降更新。因此,很容易对学习者进行微调以获得额外的梯度步骤。
我们的方法也与深度网络的初始化方法有关。在计算机视觉中,经过大规模图像分类预训练的模型已经被证明能够学习一系列问题的有效特征。相比之下,我们的方法显式地优化了模型以实现快速的适应性,只需几个例子就可以让它适应新的任务。我们的方法也可以被视为显式最大化新任务损失对模型参数的敏感性。许多先前的研究已经探索了深度网络的敏感性,相比之下,我们的方法明确地训练了给定任务分布的敏感度参数,允许在一个或几个梯度步骤中对诸如K-shot学习和快速强化学习等问题进行非常有效的适应。
5 实验评价
我们的实验评估的目标是回答以下问题:
- (1)MAML能快速学习新任务吗?
- (2)MAML可以用于多个不同领域的元学习,包括监督回归、分类和强化学习吗?
- (3)使用MAML学习的模型能否通过附加的梯度更新和/或示例继续改进?
我们认为所有的元学习问题都需要在测试时对新任务进行一定程度的适应。如果可能,我们将结果与oracle进行比较,oracle接收任务的标识(这是一个问题相关的表示)作为附加输入,作为模型性能的上限。所有的实验都是使用TensorFlow(Abadi等人,2016)进行的,它允许在元学习过程中通过梯度更新进行自动区分。
5.1.回归
我们从一个简单的回归问题开始,它说明了MAML的基本原理。每项任务都涉及从正弦波的输入到输出的回归,在正弦波的振幅和相位在任务之间是不同的。因此,p(T)是连续的,其中振幅在[0.1;5.0]范围内变化,相位在[0;π]范围内变化,并且输入和输出的维数都为1。在训练和测试过程中,数据点x从–5.0;5.0均匀采样。损失是预测f(x)和真值之间的均方误差。回归器是一个神经网络模型,有2个隐藏层,大小为40,具有ReLU非线性。在使用MAML进行训练时,我们使用一个K=10的梯度更新示例(步长α=0:01),并使用Adam作为元优化器(Kingma&Ba,2015)。baseline同样是由Adam训练的。为了评估性能,我们在不同数量的K个例子上对一个元学习模型进行微调,并将性能与两个基线进行比较:(a)对所有任务进行预训练,这需要训练一个网络回归到随机正弦函数,然后在测试时对K个提供的点进行梯度下降微调,使用自动调整的步长,和(b)接收真实振幅和相位作为输入的甲骨文。
我们通过微调MAML学习的模型和K={5;10;20}数据点上的预训练模型来评估性能。在微调过程中,使用相同的K个数据点计算每个梯度步长。定性结果,如图2所示,并在附录B中进一步扩展,表明所学习的模型能够快速适应只有5个数据点,如紫色三角形所示,然而,在所有任务上使用标准监督学习进行预训练的模型,如果没有灾难性的过度拟合,就无法充分适应如此少的数据点。关键的是,当K个数据点都在输入范围的一半时,用MAML训练的模型仍然可以推断出另一半范围内的振幅和相位,这表明用MAML训练的模型f已经学会了模拟正弦波的周期性。此外,我们观察到在定性和定量结果(图3和Appendix B)中,用MAML学习的模型继续以附加的梯度步骤改进,尽管在一个梯度步骤之后被训练以获得最大性能。这一改进表明,MAML优化了参数,使其位于一个易于快速适应的区域,并且对p(T)的损失函数敏感(如第2.2节所述),而不是过度拟合仅在一步后改进的参数θ。
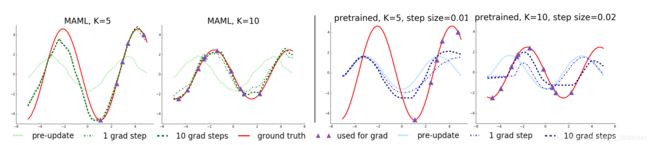
图2。对于简单的回归任务很少有镜头适应。左:注意,MAML能够估计曲线中没有数据点的部分,这表明模型已经了解了正弦波的周期结构。右图:对一个模型进行微调,在没有MAML的情况下,对相同的任务分布进行预训练,并调整步长。由于训练前任务的输出往往相互矛盾,该模型无法恢复合适的表示,也无法从少量的测试时间样本中进行外推。

图3。定量正弦回归结果显示了元测试时的学习曲线。注意,在元测试期间,在不过度拟合极小数据集的情况下,MAML继续通过额外的梯度步骤进行改进,从而实现比基线微调方法低得多的损失。
5.2分类
为了比较已有的元学习算法和少镜头学习算法,我们将我们的方法应用于Omniglot(Lake et al.,2011)和minimagenet数据集上的少镜头图像识别。Omniglot数据集由来自50个不同字母表的1623个字符的20个实例组成。每个实例都是由不同的人绘制的。MiniImagenet数据集由Ravi&Larochelle(2017)提出,涉及64个培训班、12个验证班和24个测试班。Omniglot和MiniImagenet图像识别任务是最近使用最普遍的少量镜头学习基准(Vinyals等人,2016;Santoro等人,2016;Ravi&Larochelle,2017)。我们遵循Vinyals等人提出的实验方案。(2016),包括快速学习N向分类,1或5个镜头。N-way分类的问题是:选择N个不可见的类,为模型提供N个类中每个类的K个不同实例,并评估模型在N个类中对新实例进行分类的能力。对于Omniglot,我们随机选择1200个字符进行训练,而不考虑字母表,并使用其余字符进行测试。根据Santoro等人的建议,Omniglot数据集的旋转度增加了90度的倍数。(2016年)。
我们的模型遵循与Vinyals等人使用的嵌入函数相同的架构。(2016),它有4个模块,3×3卷积和64个滤波器,然后是批处理规范化(Ioffe&Szegedy,2015)、ReLU非线性和2×2 max池。Omniglot图像被降采样到28×28,因此最后一个隐藏层的维数为64。在Vinyals等人使用的基线分类器中。(2016),最后一层被送入softmax。对于Omniglot,我们使用跨步卷积而不是max池。对于MiniImagenet,我们每层使用32个过滤器以减少过度拟合,如所做的(Ravi&Larochelle,2017)。为了对记忆增强神经网络(桑托罗等人,2016)也提供公平的比较,并且为了测试MAML的灵活性,我们也为非卷积网络提供结果。为此,我们使用4个隐藏层的网络,每个隐藏层的大小分别为256、128、64、64,包括批处理规范化和ReLU非线性,然后是线性层和softmax。对于所有模型,损失函数是预测类与真类之间的交叉熵误差。附录A.1中包含了额外的超参数细节。
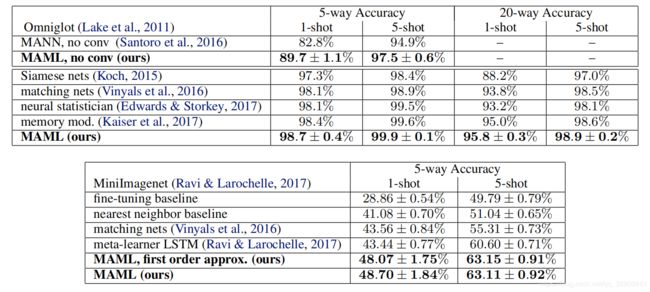
结果见表1。由MAML学习的卷积模型与这项任务的最新结果相比,有很好的性能,远远优于先前的方法。一些现有的方法,如匹配网络,暹罗网络,和记忆模型的设计与少镜头分类铭记,不容易适用于域,如强化学习。此外,与匹配网络和元学习者LSTM相比,使用MAML学习的模型使用更少的总体参数,因为该算法不引入任何超出分类器本身权重的额外参数。与这些先前的方法相比,记忆增强神经网络(Santoro等人,2016)特别是递归元学习模型,代表了一类更广泛适用的方法,如MAML,可用于其他任务,如强化学习(Duan等人,2016b;Wang等人,2016)。然而,如比较所示,在5路泛光分类和minimagenet分类上,MAML在1-shot和5-shot两种情况下都显著优于记忆增强网络和元学习者LSTM。
表1。在突出的Omniglot字符(顶部)和minimagenet测试集(底部)上很少有镜头分类。MAML所获得的结果与最新的卷积和递归模型相当或优于它们。暹罗网、匹配网和内存模块方法都是特定于分类的,不直接适用于回归或RL场景。在任务中,±表示95%的置信区间。请注意,Omniglot的结果可能不具有严格的可比性,因为先前工作中使用的列车/测试分段不可用。基线方法和匹配网络的MiniImagenet评估来自Ravi&Larochelle(2017)。
在MAML中,一个重要的计算开销来自于在通过元目标中的梯度算子反向传播元梯度时使用二阶导数(见方程(1))。在MIN IMANENET中,我们与MAML的一阶近似进行比较,其中省略了这些第二导数。注意,结果方法仍然计算更新后参数值θi0处的元梯度,这提供了有效的元学习。然而,令人惊讶的是,该方法的性能几乎与使用全二阶导数获得的结果相同,这表明MAML中的大多数改进来自于更新后参数值处目标的梯度,而不是通过梯度更新来区分的二阶更新。过去的工作已经观察到,Relu神经网络在局部几乎是线性的(GooFisher等人,2015),这表明,在大多数情况下,二阶导数可能接近于零,部分地解释了一阶近似的良好性能。这种近似消除了在额外的向后传递中计算Hessian向量积的需要,我们发现在网络计算中导致大约33%的加速。
5.3强化学习
为了评估增强学习问题上的MAML,我们基于rllab基准套件中的模拟连续控制环境构建了几组任务(Duan等人,2016a)。我们在下面讨论各个领域。在所有领域中,由MAML训练的模型都是一个具有两个100大小的隐藏层的具有ReLU非线性的神经网络策略。梯度更新使用vanilla policy gradient(REINFORCE)(Williams,1992)计算,我们使用信任区域策略优化(TRPO)作为元优化器(Schulman等人,2015)。为了避免计算三阶导数,我们使用有限差分来计算TRPO的Hessian向量积。对于学习和元学习更新,我们使用Duan等人提出的标准线性特征基线。(2016a),对于批次中的每个采样任务,在每次迭代时分别进行拟合。我们比较了三个基线模型:(a)对所有任务预先训练一个策略,然后进行微调;(b)从随机初始化的权重训练策略;(c)接收任务参数作为输入的oracle策略,对于下面的任务,该策略对应于代理的目标位置、目标方向或目标速度。(a)和(b)的基线模型通过手动调整步长的梯度下降进行微调。学习政策的视频可以在sites.google.com/view/maml上查看。
二维导航:在我们的第一个meta-RL实验中,我们研究了一组任务,其中一个点代理必须在2D内移动到不同的目标位置,在一个单位平方内为每个任务随机选择。观测值是当前的二维位置,动作对应于速度命令,该命令被剪裁为在范围[-0:1;0:1]内。奖励是到目标的负平方距离,当代理在目标的0:01范围内或在H=100的地平线上时,事件终止。使用1个策略梯度更新使用20个轨迹,用MAML训练策略以最大化性能。附录A.2中提供了此问题和以下RL问题的附加超参数设置。在我们的评估中,我们比较了对一个新任务的适应,这个任务最多有4个梯度更新,每个更新有40个样本图4中的结果显示了使用MAML初始化的模型的适应性能、对同一组任务的常规预训练、随机初始化以及接收目标位置作为输入的oracle策略。结果表明,MAML可以学习一个模型,该模型在一次梯度更新中适应得更快,并且随着更新的增加而不断改进。
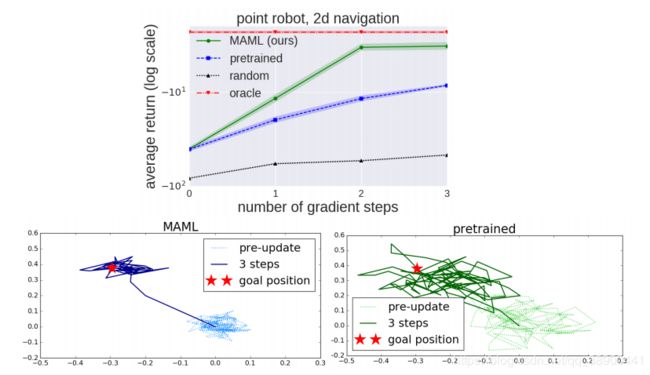
图4。 顶部:二维导航任务的定量结果,底部:用MAML学习的模型与预先训练的网络进行微调之间的定性比较。
定位:为了研究MAML如何适应更复杂的深层RL问题,我们还利用MuJoCo模拟器研究了高维运动任务的适应性(Todorov等人,2012)。这些任务需要两个模拟机器人——一个平面猎豹和一个三维四足动物(简称“蚂蚁”)朝特定方向或以特定速度奔跑。在目标速度实验中,奖励是当前代理速度和目标速度之间的负绝对值,猎豹在0:0到2:0之间,蚂蚁在0:0到3:0之间均匀随机选择。在目标方向实验中,奖励是在p(T)中为每项任务随机选择的前进或后退方向的速度大小。horizon是H=200,对于所有问题,每个渐变步骤有20个卷展栏,除了ant forward/backward任务,该任务每个步骤使用40个卷展栏。图5中的结果表明,MAML学习的模型可以快速调整其速度和方向,甚至只需一次梯度更新,并继续改进更多的梯度步骤。结果还表明,在这些具有挑战性的任务中,MAML初始化明显优于随机初始化和预训练。事实上,在某些情况下,预训练比随机初始化更糟,这是在先前的RL工作中观察到的事实(Parisotto等人,2016)。

图5。强化半猎豹和蚂蚁移动任务的学习效果,任务显示在最右侧。与有监督的学习任务不同,每个梯度步骤都需要来自环境的额外样本。结果表明,与传统的预训练和随机初始化相比,多目标学习算法能够更快地适应新的目标速度和方向,仅需两到三个梯度步就能获得良好的性能。我们排除了目标速度和随机基线曲线,因为回报率更差(猎豹低于-200,蚂蚁低于-25)。
6.讨论和今后的工作
提出了一种基于梯度下降学习模型参数的元学习方法。我们的方法有很多好处。它是简单的,不引入任何学习参数的金属学习。它可以与任何适合于梯度训练的模型表示和任何可微目标相结合,包括分类、回归和强化学习。最后,由于我们的方法只产生一个权值初始化,因此可以对任意数量的数据和任意数量的梯度步骤进行自适应,尽管我们仅用一个或五个示例来演示分类的最新结果。我们还表明,我们的方法可以使用策略梯度和非常有限的经验来适应RL代理。
重新使用过去任务中的知识可能是制作高容量可伸缩模型(如深度神经网络)的一个重要组成部分,该模型能够使用小数据集进行快速训练。我们相信这项工作是朝着一个简单通用的元学习技术迈出的一步,它可以应用于任何问题和任何模型。该领域的进一步研究可以使多任务初始化成为深度学习和强化学习的标准组成部分。
- MAML的执行过程与model pretraining & transfer learning的区别是什么?
- 为何在meta网络赋值给具体训练任务(如任务m)后,要先更训练任务的参数,再计算梯度,更新meta网络?
- 在更新训练任务的网络时,只走了一步,然后更新meta网络。为什么是一步,可以是多步吗?
https://zhuanlan.zhihu.com/p/136975128