词袋模型基本原理——DBoW3
1.什么是词袋模型?
(转载于https://blog.csdn.net/chapmancp/article/details/80179765)
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
现在Computer Vision中的Bag of words来表示图像的特征描述也是很流行的。大体思想是这样的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像SIFT基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用Sift表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
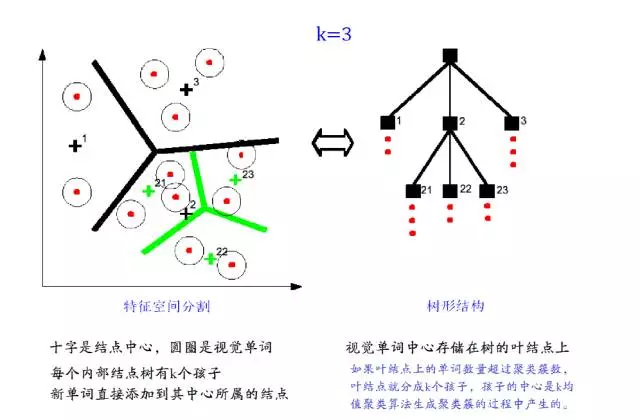
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为100,即有100个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=100,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这100个质心(维数128)就是词典里德100 个词了,词典构建完毕。
词典构建完了怎么用呢?是这样的,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有很多patch么?我们就再次计算这些patch和和每一个质心的距离,看看每一个patch离哪一个质心最近,那么直方图h中相对应的bin就加1,然后计算完这幅图像所有的 patches之后,就得到了一个bin=100的直方图,然后进行归一化,用这个100维的向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
2.词袋模型在slam中的应用?
DBoW3库介绍
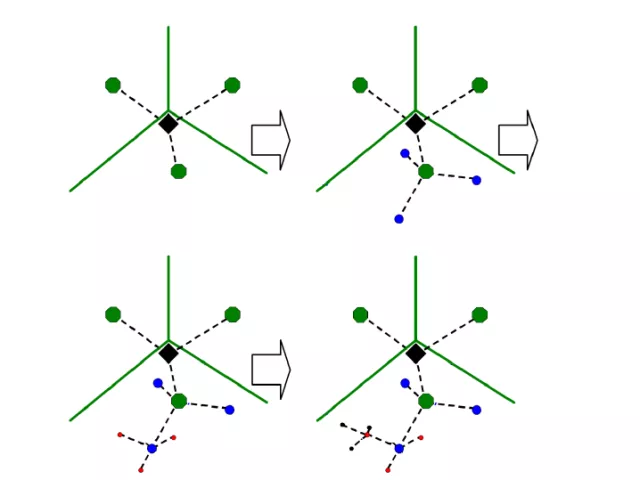
DBoW3是DBoW2的增强版,这是一个开源的C++库,用于给图像特征排序,并将图像转化成视觉词袋表示。它采用层级树状结构将相近的图像特征在物理存储上聚集在一起,创建一个视觉词典。DBoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的检索和对比非常快。
DBoW3与DBoW2的主要差别:
1、DBoW3依赖项只有OpenCV,DBoW2依赖项DLIB被移除;
2、DBoW3可以直接使用二值和浮点特征描述子,不需要再为这些特征描述子重写新类;
3、DBoW3可以在Linux和Windows下编译;
4、为了优化执行速度,重写了部分代码(特征的操作都写入类DescManip);DBoW3的接口也被简化了;
5、可以使用二进制视觉词典文件;二进制文件在加载和保存上比.yml文件快4-5倍;而且,二进制文件还能被压缩;
6、仍然和DBoW2yml文件兼容。
DBoW3有两个主要的类:Vocabulary和Database。视觉词典将图像转化成视觉词袋向量,图像数据库对图像进行索引。
ORB-SLAM2中的ORBVocabulary保存在文件orbvoc.dbow3中,二进制文件在Github上:https://github.com/raulmur/ORB_SLAM2/tree/master/Vocabulary
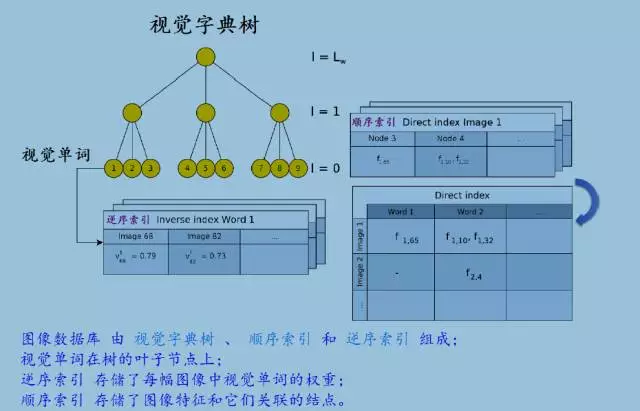
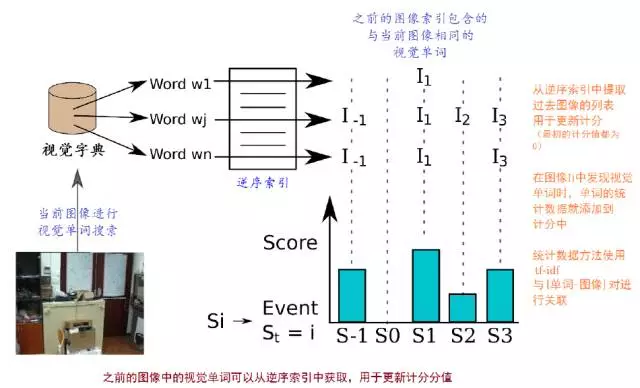
逆序指针指向一个数据对<图像It, 视觉词袋向量vti>,可以快速获取图像上的视觉单词的权重。当新的图像It加入到图像数据库中的时候,逆序指针就会更新,也方便在数据库中查找图像。逆序索引用于提取与给定图像相似的图像。这个结构用于存储视觉单词,视觉单词组成视觉字典,视觉字典形成图像。检索图像、做比较操作时,就不会对比图像中相同的视觉单词,这对检索图像数据库非常有用。顺序索引有效地获取图像间的云点匹配,加快图像确认中的几何特征检验。顺序指针可以方便地存储每幅图像的特征。视觉字典中的节点是分层存储的,假如树一共有L层,从叶子开始为0层,即L=0,到根结束,l=Lw。对于每幅图像It,将l层的节点存储在顺序指针中,而l层的这些节点是图像It的视觉单词的父节点,局部特征ftj列表与每个节点关联。用顺序指针和词袋模型树估算BRIEF向量描述子空间中的最邻近的节点。对于那些特征属于相同的单词或具有第l层相同父节点的单词,计算特征的对应关系时,这些顺序指针可以加快几何验证过程。当获取一个将要匹配的候选特征时,几何验证非常必要,新图像加进数据库,顺序指针就会更新。
权重计算Weighting
单词在视觉字典和词袋向量中都有权重。
视觉单词有4种权重计算方法:
1. 词频Term Frequency (tf):![]() 其中,
其中,![]() 是单词 在图像d中出现的次数;
是单词 在图像d中出现的次数;![]() 是图像d中单词的数量;
是图像d中单词的数量;
2. 逆向文件频率Inverse documentfrequency (idf):![]() N是图像数量;Ni是图像包含单词的数量;
N是图像数量;Ni是图像包含单词的数量;
3. 词频-逆向文件频率Term frequency -inverse document frequency (tf-idf):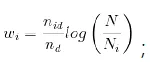
4. 二值: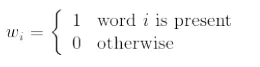
注意:视觉词典创建之后,DBoW根据图像的数量计算N 和 Ni 。他们的值不会随图像数据库中的图像特征入口数量的变化而变化。
相似度度量 Scoring
如果是要对观测到的样品数据进行判别分类的问题,可以应用统计学中判别分析方法进行处理。判别分析方法主要有距离判别、贝叶斯判别和典型判别等几种常用方法。通常我们所说的距离是欧式距离,即欧式空间中两点之间的距离。但在统计学多元分析中,有时欧式距离不太合适。比如,某个数据点在两个正态分布中的距离。这样就会用到马哈拉诺比斯Mahalanobis距离,即马氏距离。
在分类中的相似度度量有两种方法---距离和相似系数,距离用来度量样品之间的相似性,相似系数用来度量变量之间的相似性。样品之间的距离和相似系数的定义不同,而这些定义与变量的类型有非常密切的关系。变量按照测量尺度的不同可以分为三类:
1) 间隔尺度变量:变量是连续的量。如长度、速度、重量、温度等。
2) 有序尺度变量:不明确的数量表示变量,而是用等级表示。如某产品分为一等品、二等品、三等品等有序关系。
3) 名义尺度变量:变量用一些类表示,无等级或数量关系。如性别、职业等。
可以通过词典Vocabulary或查询图像数据库Database计算两个向量的相似度。有好几种方法可以计算相似度。相似度的值的含义在于我们使用什么样的度量方式。然而,有些度量方法可以标准化到区间[0..1]中,0表示没有匹配,1表示完美匹配。如果需要修改计算相似度的代码,也要注意词典Vocabulary和图像数据库Database的执行速度。
计算两个向量v 和w的相似度有几种度量方法(这里v* 和w* 表示经过L1范数标准化后的向量):
1、点积Dot product:![]()
2、L1范数L1-norm: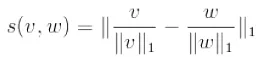
3、L2范数L2-norm: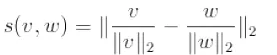
4、巴式系数Bhattacharyyacoefficient: 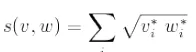 。巴式距离测量两个离散或连续概率分布的相似性。它与衡量两个统计样品或种群之间的重叠量的Bhattacharyya系数密切相关。
。巴式距离测量两个离散或连续概率分布的相似性。它与衡量两个统计样品或种群之间的重叠量的Bhattacharyya系数密切相关。
5、卡方距离 χ² distance: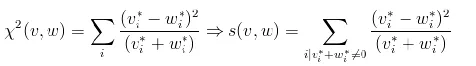
6、KL散度 / 相对熵KL-divergence: 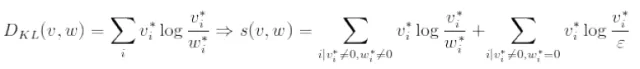
有些方法在使用前,要对向量进行标准化处理。向量通常都是稀疏的、包含了一些0值,卡方距离和KL散度并不能处理所有向量。因此,需要避免数值处理上的问题。在KL散度的计算中,ε 是计算机给出的epsilon 值(最小的浮点负数)。当计算计分的时候,可以使用一个标志位来指示这些值在线性范围[0..1]中, 其中1是最大值,0是最小之。用L1-范数,L2-范数和卡方距离时,激活这个标志位。巴式系数Bhattacharyyacoefficient 总是在[0..1]内,并不依赖于变换标志位。
注意:为了计算效率,计算卡方距离的时候假定权重从来都不会为负数(使用tf, idf, tf-idf 和 binary 向量的时候,总是这样)。创建字典的时候,缺省使用tf-idf 和L1-范式。
DBoW3代码解读
DBoW3库主要类:

DBoW3视觉字典构建过程:

转载说明:本文转载于泡泡机器人--致力于slam发展,谢谢以上各位作者。
【版权声明】泡泡机器人SLAM的所有文章全部由泡泡机器人的成员花费大量心血制作而成的原创内容,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
