kaggle数据调查

(一)数据领域朋友的自身情况
- 性别比例
- 调查问卷国家分布
- 年龄分布
- 收入情况
- 所学专业
- 从事领域
- 工作满意度
- 最常使用工具
- 常用算法
- 计算平台选择
- 面临挑战
(二)Python和R哪家强
- 使用人数
- 常用工具
- 不同工种偏好
- 各大领域使用趋势
- 薪资待遇
- 用了多少年
- 重要程度
(三)数据科学家都在用什么
- 国家分布
- 使用Python or R
- 工资与学历
- 如何证明自己呢
- 遇到的问题
- 对可视化的重要程度
- 求职的途径
- 前一份工作和现在的对比
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import base64
import io
from scipy.misc import imread
import codecs
from IPython.display import HTML
先来看看这些数据是啥个样子哦
response=pd.read_csv('multipleChoiceResponses.csv',encoding='ISO-8859-1')
response.head()
来看看这些数据,一共有多少个国家的兄弟们加入了调查,最多的是哪个国家?最小几岁?最大又是几岁呢?
print('调查对象总数',response.shape[0])
print('一共多少个国家参与了调查:',response['Country'].nunique())
print('参与人数最多的国家是',response['Country'].value_counts().index[0],'人数',response['Country'].value_counts().values[0])
print('最小的选手:',response['Age'].min(),' 最大的选手:',response['Age'].max())
调查对象总数 16716
一共多少个国家参与了调查: 52
参与人数最多的国家是 United States 人数 4197
最小的选手: 0.0 最大的选手: 100.0
ps:这是个啥?填写问卷的兄弟们很调皮啊。
看看性别的分布吧
我猜男的最多。
import matplotlib
matplotlib.rcParams.update({'font.size': 25})
plt.subplots(figsize=(22,12))
sns.countplot(y=response['GenderSelect'],order=response['GenderSelect'].value_counts().index)
plt.show()

不出所料,男的还是占了大多数,符合猜想
各国的收入情况啥样呀在调查问卷中
因为每个国家的货币不一样,所以加入换算比率
#有些收入的写法比较特别
response['CompensationAmount']=response['CompensationAmount'].str.replace(',','')
response['CompensationAmount']=response['CompensationAmount'].str.replace('-','')
rates=pd.read_csv('conversionRates.csv')
rates.head()

rates.drop('Unnamed: 0',axis=1,inplace=True)
salary=response[['CompensationAmount','CompensationCurrency','GenderSelect','Country','CurrentJobTitleSelect']].dropna()
salary.head()
salary=salary.merge(rates,left_on='CompensationCurrency',right_on='originCountry',how='left')
salary.head()
salary['Salary']=pd.to_numeric(salary['CompensationAmount'])*salary['exchangeRate']
print('Maximum Salary is USD $',salary['Salary'].dropna().astype(int).max())
print('Minimum Salary is USD $',salary['Salary'].dropna().astype(int).min())
print('Median Salary is USD $',salary['Salary'].dropna().astype(int).median())
Maximum Salary is USD $ 208999999
Minimum Salary is USD $ -2147483648
Median Salary is USD $ 53812.0
ps:看看平均数,真的是羡慕…
plt.subplots(figsize=(15,8))
salary=salary[salary['Salary']<1000000]
sns.distplot(salary['Salary'])
plt.title('Salary Distribution',size=15)
plt.show()
这里我筛选出100W以下的收入,别的就当做没有了。

f,ax=plt.subplots(1,2,figsize=(28,8))
sal_coun=salary.groupby('Country')['Salary'].median().sort_values(ascending=False)[:15].to_frame()
sns.barplot('Salary',sal_coun.index,data=sal_coun,palette='RdYlGn',ax=ax[0])
ax[0].axvline(salary['Salary'].median(),linestyle='dashed')
ax[0].set_title('Highest Salary Paying Countries')
ax[0].set_xlabel('')
max_coun=salary.groupby('Country')['Salary'].median().to_frame()
max_coun=max_coun[max_coun.index.isin(resp_coun.index)]
max_coun.sort_values(by='Salary',ascending=True).plot.barh(width=0.8,ax=ax[1],color=sns.color_palette('RdYlGn'))
ax[1].axvline(salary['Salary'].median(),linestyle='dashed')
ax[1].set_title('Compensation of Top 15 Respondent Countries')
ax[1].set_xlabel('')
ax[1].set_ylabel('')
plt.subplots_adjust(wspace=0.8)
plt.show()

竖条是整体的中位数,左边的图中工资排名前15的国家都超过中位数了,右边的图是参与人数最多的15个国家的情况,中国的薪资还是有点低啊。
来玩数据的人都是啥专业的呀?现在又干啥呢?
f,ax=plt.subplots(1,2,figsize=(30,15))
sns.countplot(y=response['MajorSelect'],ax=ax[0],order=response['MajorSelect'].value_counts().index)
ax[0].set_title('Major')
ax[0].set_ylabel('')
sns.countplot(y=response['CurrentJobTitleSelect'],ax=ax[1],order=response['CurrentJobTitleSelect'].value_counts().index)
ax[1].set_title('Current Job')
ax[1].set_ylabel('')
plt.subplots_adjust(wspace=0.8)
plt.show()
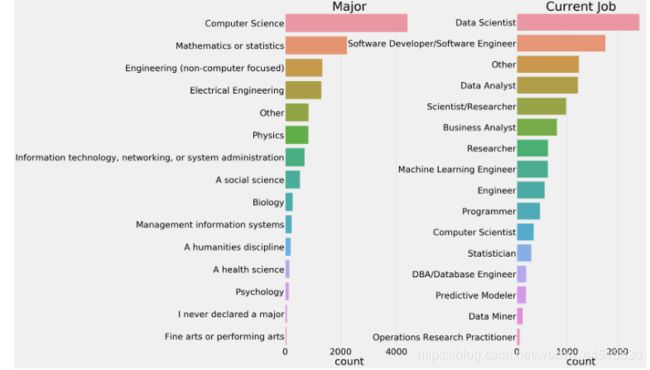
几乎所有行业都使用数据科学和机器学习。从左图中可以看出这一点,因为来自不同领域的人们,如物理、生物学等,正都在从事数据方面的研究。
右边的图表显示了被调查者当前的工作情况。最多的人是数据科学家。(距离小时候的做个科学家的梦想进了一步了,哈哈)
这些个不同工种的工资啥样呢?
sal_job=salary.groupby('CurrentJobTitleSelect')['Salary'].median().to_frame().sort_values(by='Salary',ascending=False)
ax=sns.barplot(sal_job.Salary,sal_job.index,palette=sns.color_palette('inferno',20))
plt.title('Compensation By Job Title',size=15)
for i, v in enumerate(sal_job.Salary):
ax.text(.5, i, v,fontsize=10,color='white',weight='bold')
fig=plt.gcf()
fig.set_size_inches(8,8)
plt.show()

运筹学从业者的平均工资中位数最高,其次是预测建模师和数据科学家。计算机科学家和程序员的报酬最低。原来不是所有写程序的都称为程序员的啊。。。
f,ax=plt.subplots(1,2,figsize=(35,12))
skills=response['MLSkillsSelect'].str.split(',')
skills_set=[]
for i in skills.dropna():
skills_set.extend(i)
plt1=pd.Series(skills_set).value_counts().sort_values(ascending=False).to_frame()
sns.barplot(plt1[0],plt1.index,ax=ax[0],palette=sns.color_palette('inferno_r',15))
ax[0].set_title('ML Skills')
tech=response['MLTechniquesSelect'].str.split(',')
techniques=[]
for i in tech.dropna():
techniques.extend(i)
plt1=pd.Series(techniques).value_counts().sort_values(ascending=False).to_frame()
sns.barplot(plt1[0],plt1.index,ax=ax[1],palette=sns.color_palette('inferno_r',15))
ax[1].set_title('ML Techniques used')
plt.subplots_adjust(wspace=0.8)
plt.show()
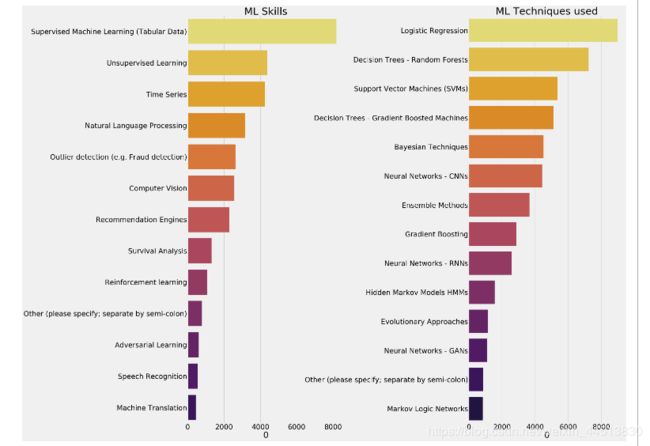
显然,大多数受调查者都从事有监督的学习,而逻辑回归是其中最受欢迎的,但是算法没有高下之分!
f,ax=plt.subplots(1,2,figsize=(30,15))
ml_nxt=response['MLMethodNextYearSelect'].str.split(',')
nxt_year=[]
for i in ml_nxt.dropna():
nxt_year.extend(i)
pd.Series(nxt_year).value_counts()[:15].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('winter_r',15),ax=ax[0])
tool=response['MLToolNextYearSelect'].str.split(',')
tool_nxt=[]
for i in tool.dropna():
tool_nxt.extend(i)
pd.Series(tool_nxt).value_counts()[:15].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('winter_r',15),ax=ax[1])
plt.subplots_adjust(wspace=0.8)
ax[0].set_title('ML Method Next Year')
ax[1].set_title('ML Tool Next Year')
plt.show()
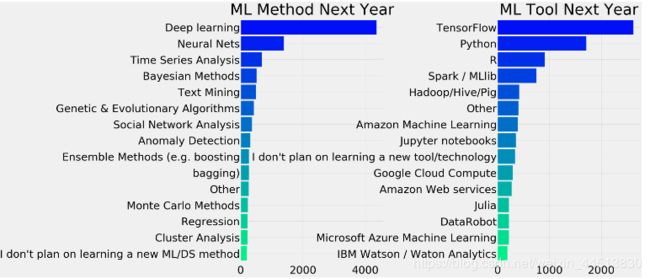
很明显,下一年将会有更多的深度学习者。深入学习和神经网络或短期AI是明年最受欢迎的热门话题。此外,在工具方面,Python比R更受欢迎。
数据科学面临的挑战
plt.subplots(figsize=(15,18))
challenge=response['WorkChallengesSelect'].str.split(',')
challenges=[]
for i in challenge.dropna():
challenges.extend(i)
plt1=pd.Series(challenges).value_counts().sort_values(ascending=False).to_frame()
sns.barplot(plt1[0],plt1.index,palette=sns.color_palette('inferno',25))
plt.title('Challenges in Data Science')
plt.show()

最大的挑战看起来是获得最干净的数据,但是基本所有的对我来说都是挑战。。。
Python vs R or (Batman vs Superman)
Python和R是用于数据科学和机器学习的最广泛使用的开源语言。对于一个初露头角的数据科学家或分析师,最大和最棘手的疑问是:我的语言开始?虽然两种语言都有各自的优点和缺点,但在选择自己的语言时,这取决于个人的目的。这两种语言都能满足各种不同工作的需要。Python是一种通用的语言,因此,Web和应用集成更容易,而R是为了纯粹的统计和分析的目的。
(PHP是世界上最好的语言。。。)
resp=response.dropna(subset=['WorkToolsSelect'])
resp=resp.merge(rates,left_on='CompensationCurrency',right_on='originCountry',how='left')
python=resp[(resp['WorkToolsSelect'].str.contains('Python'))&(~resp['WorkToolsSelect'].str.contains('R'))]
R=resp[(~resp['WorkToolsSelect'].str.contains('Python'))&(resp['WorkToolsSelect'].str.contains('R'))]
both=resp[(resp['WorkToolsSelect'].str.contains('Python'))&(resp['WorkToolsSelect'].str.contains('R'))]
response['LanguageRecommendationSelect'].value_counts()[:2].plot.bar()
plt.show()
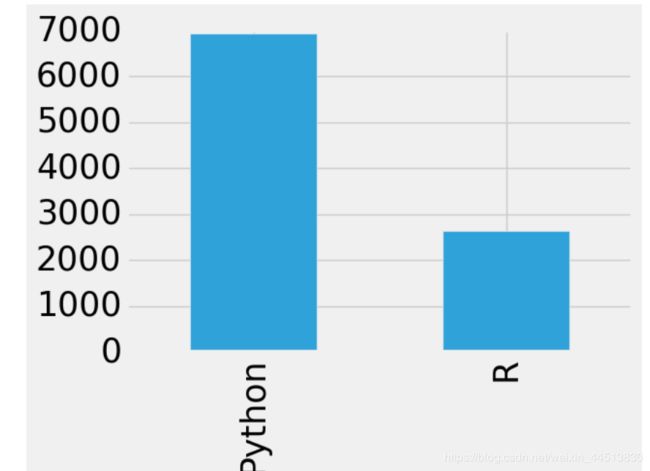
人生苦短,我用…
from matplotlib_venn import venn2
# pip install matplotlib_venn 画交集用的
f,ax=plt.subplots(1,2,figsize=(18,8))
pd.Series([python.shape[0],R.shape[0],both.shape[0]],index=['Python','R','Both']).plot.bar(ax=ax[0])
ax[0].set_title('Number of Users')
venn2(subsets = (python.shape[0],R.shape[0],both.shape[0]), set_labels = ('Python Users', 'R Users'))
plt.title('Venn Diagram for Users')
plt.show()
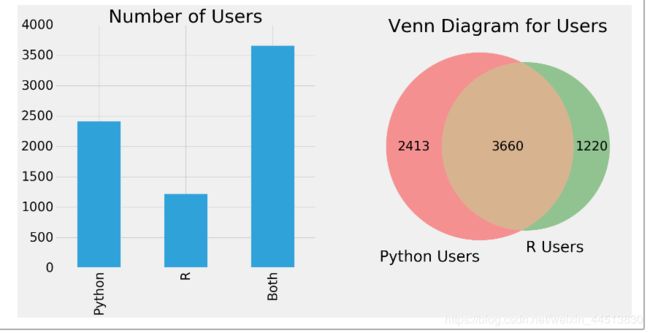
通杀才是王道。。。
不同工作的偏好
py1=python.copy()
r=R.copy()
py1['WorkToolsSelect']='Python'
r['WorkToolsSelect']='R'
r_vs_py=pd.concat([py1,r])
r_vs_py=r_vs_py.groupby(['CurrentJobTitleSelect','WorkToolsSelect'])['Age'].count().to_frame().reset_index()
r_vs_py.pivot('CurrentJobTitleSelect','WorkToolsSelect','Age').plot.barh(width=0.8)
fig=plt.gcf()
fig.set_size_inches(10,15)
plt.title('Job Title vs Language Used',size=15)
plt.show()
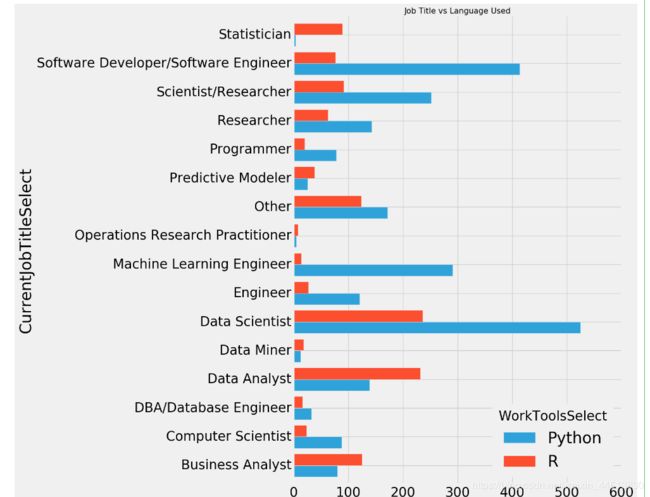
R在视觉上胜过Python。因此,拥有诸如数据分析师、业务分析师等职位头衔的人在图形和视觉上扮演着非常重要的角色,他们喜欢R而不是Python。同样,几乎90%的统计人员使用R,正如前面所述,Python在机器学习方面更好,因此机器学习工程师、数据科学家和DBA或程序员等其他人更喜欢Python。
Python与R分别最常使用的工具是什么呢?
f,ax=plt.subplots(1,2,figsize=(20,15))
py_comp=python['WorkToolsSelect'].str.split(',')
py_comp1=[]
for i in py_comp:
py_comp1.extend(i)
plt1=pd.Series(py_comp1).value_counts()[1:15].sort_values(ascending=False).to_frame()
sns.barplot(plt1[0],plt1.index,ax=ax[0],palette=sns.color_palette('inferno_r',15))
R_comp=R['WorkToolsSelect'].str.split(',')
R_comp1=[]
for i in R_comp:
R_comp1.extend(i)
plt1=pd.Series(R_comp1).value_counts()[1:15].sort_values(ascending=False).to_frame()
sns.barplot(plt1[0],plt1.index,ax=ax[1],palette=sns.color_palette('inferno_r',15))
ax[0].set_title('Commonly Used Tools with Python')
ax[1].set_title('Commonly Used Tools with R')
plt.subplots_adjust(wspace=0.8)
plt.show()
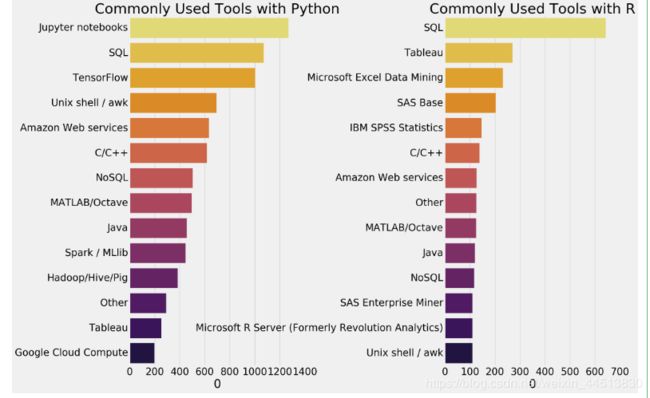
SQL是语言最常见的补充工具。SQL是查询大型数据库的主要语言,因此了解它是一个很大的好处。
教育背景以及工作情况
f,ax=plt.subplots(1,2,figsize=(25,10))
sns.countplot(y=scientist['EmploymentStatus'],ax=ax[0])
ax[0].set_title('Employment Status')
ax[0].set_ylabel('')
sns.countplot(y=scientist['FormalEducation'],order=scientist['FormalEducation'].value_counts().index,ax=ax[1],palette=sns.color_palette('viridis_r',15))
ax[1].set_title('Formal Eduaction')
ax[1].set_ylabel('')
plt.subplots_adjust(wspace=0.8)
plt.show()
大约67%的数据科学家都是全职,而大约11-12%都失业而找工作。在教育方面显然对76 %的数据科学家持有硕士学位,而约23-24%他们有学士学位或博士学位。因此,教育似乎是成为数据科学家的一个重要因素。
看看他们的时间都去哪了。
import itertools
plt.subplots(figsize=(22,10))
time_spent=['TimeFindingInsights','TimeVisualizing','TimeGatheringData','TimeModelBuilding']
length=len(time_spent)
for i,j in itertools.zip_longest(time_spent,range(length)):
plt.subplot((length/2),2,j+1)
plt.subplots_adjust(wspace=0.2,hspace=0.5)
scientist[i].hist(bins=10,edgecolor='black')
plt.axvline(scientist[i].mean(),linestyle='dashed',color='r')
plt.title(i,size=20)
plt.xlabel('% Time')
plt.show()

在Python和R中最常用什么库
import nltk
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english'))
stop_words.update(',',';','!','?','.','(',')','$','#','+',':','...')
free=pd.read_csv('freeformResponses.csv',encoding='ISO-8859-1')
library=free['WorkLibrariesFreeForm'].dropna().apply(nltk.word_tokenize)
lib=[]
for i in library:
lib.extend(i)
lib=pd.Series(lib)
lib=([i for i in lib.str.lower() if i not in stop_words])
lib=pd.Series(lib)
lib=lib.value_counts().reset_index()
lib.loc[lib['index'].str.contains('Pandas|pandas|panda'),'index']='Pandas'
lib.loc[lib['index'].str.contains('Tensorflow|tensorflow|tf|tensor'),'index']='Tensorflow'
lib.loc[lib['index'].str.contains('Scikit|scikit|sklearn'),'index']='Sklearn'
lib=lib.groupby('index')[0].sum().sort_values(ascending=False).to_frame()
R_packages=['dplyr','tidyr','ggplot2','caret','randomforest','shiny','R markdown','ggmap','leaflet','ggvis','stringr','tidyverse','plotly']
Py_packages=['Pandas','Tensorflow','Sklearn','matplotlib','numpy','scipy','seaborn','keras','xgboost','nltk','plotly']
f,ax=plt.subplots(1,2,figsize=(18,10))
lib[lib.index.isin(Py_packages)].sort_values(by=0,ascending=True).plot.barh(ax=ax[0],width=0.9,color=sns.color_palette('viridis',15))
ax[0].set_title('Most Frequently Used Py Libraries')
lib[lib.index.isin(R_packages)].sort_values(by=0,ascending=True).plot.barh(ax=ax[1],width=0.9,color=sns.color_palette('viridis',15))
ax[1].set_title('Most Frequently Used R Libraries')
ax[1].set_ylabel('')
plt.show()

结论:
1)调查对象不仅限于计算机科学专业,还包括统计学、健康科学等专业,数据科学是一门跨学科的领域。
2)学习Python、R和SQL,因为它们是数据科学家最常用的语言。Python和R将有助于分析和预测建模,而SQL最适合查询数据库。
3)学习机器学习技术,如逻辑回归,决策树,支持向量机等,因为它们是最常用的机器学习技术/算法。
4)深学习和神经网络将是未来最受欢迎的技术,因此,精通它们将是非常有益的。
5)掌握收集数据和清理数据的技能,因为它们是数据科学家工作流程中最耗时的过程。
6)数学和统计在数据科学中是非常重要的,所以我们应该对它有很好的理解,以便真正理解算法是如何工作的。
7)根据数据科学家们说,项目是学习数据科学的最佳途径,因此,研究项目将有助于更好地学习数据科学。