基本概念
https://chenrudan.github.io/blog/2014/06/26/dl1baseconcept.html
deep在移动端的应用
收集行业案例
http://weixin.sogou.com/weixin?type=2&query=%E7%A7%BB%E5%8A%A8%E7%AB%AF+%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&ie=utf8&s_from=input&sug=n&sug_type=
支付宝
含代码 | 支付宝如何优化移动端深度学习引擎?
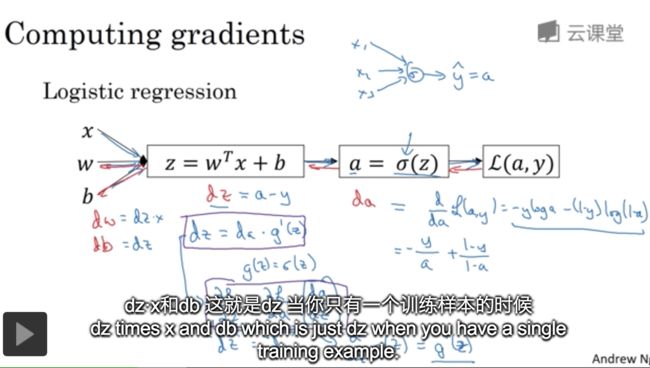
logistic回归的参数
线性回归是个啥?
逻辑回归是个啥? https://tech.meituan.com/intro_to_logistic_regression.html
https://www.sohu.com/a/205786533_314987
https://blog.csdn.net/sxf1061926959/article/details/66976356?locationNum=9&fps=1
想让损失函数小一些是什么含义? 损失函数
成本函数
全局成本函数是对1到m的损失函数和的平均
梯度下降法 学习率阿尔法
函数的斜率
偏导函数
logistic 回归的梯度下降法
算反向传播是为了梯度下降,求出来导出
多个特征情况下 如何运用梯度下降?
每个神经单元需要
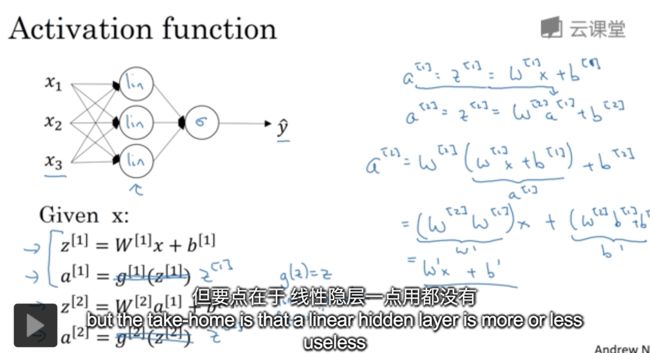
激活函数
和他们的导数有啥关系呢?计算梯度下降的时候会用到??
西格玛函数,二元分类的输出层
ReLU函数 的好处是,在斜率将近为0时,存在减慢学习速度的效应。
Tanh函数
非线性的激活函数,什么是线性的呢?什么不是线性的?
线性隐层一点用都没有,除非是未了做缩放
梯度下降
对损失函数的各个w求导,在不断更新w,就是求解的过程,
线性的 拟合过程不行吗?
关于梯度下降求导,知道了损失函数的导数,如何知道 成本函数的导数呢?成本函数是 多样本的均值,如何求导数呢?
话说真的要费一些心思呢 https://blog.csdn.net/jasonzzj/article/details/52017438
梯度下降算法的实现过程,因为存在前后依赖
浅层网络
向量化

单隐层神经网络中的前向和后向传播,logistic回归,向量化
为什么随机初始化比较重要,
深层神经网络

多少层的时候,不算输入层剩下的,隐层个数+输出层之和
深层网络中前向传播
会影响第一层激活单元的参数,求激活函数
那梯度下降是干啥的呀,为了更快的训练出 单元参数?
梯度下降的计算过程
求多样本的同一项dw之和的平均值,N个样本就对应N个dz,N个特征列就对应N个dw或者w
定义各层神经元功能
如何定制化各个神经单元的功能,比如第一层的识别边缘,第二层的识别五官,第三层的识别人脸?
概率论
机器学习
多隐层时不需要考虑前后的联动性么?

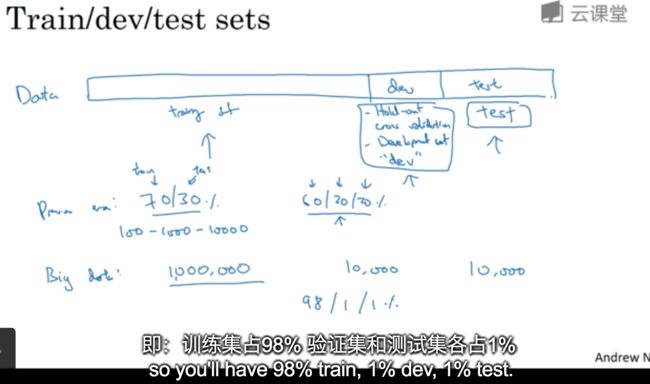
训练开发测试集
验证集或简单交叉验证集的作用是:验证不同算法更有效
初始化w\b参数

用于 得到比较好的 模型参数
偏差 和 方差
分别是什么含义?

偏差 代表着 准确度
方差 代表着 稳定度
过拟合,是低偏差、高方差,导致适用范围宅,对未见过的数据的预测能力弱,泛化的不好。新增验证集,验证集中包含多样的数据
欠拟合,是高偏差、低方差,导致准确率低
http://baijiahao.baidu.com/s?id=1591715304965529269&wfr=spider&for=pc
正则化
什么是正则化? 有什么用途呢? 用于 解决 过拟合
https://blog.csdn.net/haima1998/article/details/79425831
从例子中看正则化的求导过程,结合了加法函数求导、导数的链式法则、偏导的求解。特别是偏导数的求解,记得相关的加法函数。比如
dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m * W3
dW2 = 1./m * np.dot(dZ2, A1.T) + lambd/m * W2
dW1 = 1./m * np.dot(dZ1, X.T) + lambd/m * W1
Dropout
矩阵范数 和 虚数实数的理解
https://blog.csdn.net/u013534498/article/details/52674008
L2范数 https://blog.csdn.net/zouxy09/article/details/24971995
https://www.guokr.com/post/432219/
归一化或规则化
https://blog.csdn.net/leiting_imecas/article/details/54986045
用于 将椭圆修正为 正圆
梯度检测
在w\b超参初始值附近做双边求导的结果 和 通过正常的求导公式推算出来的对应超参的偏导公式的结果,做对比(对比公式如下),如果相差很小,则说明验证通过。
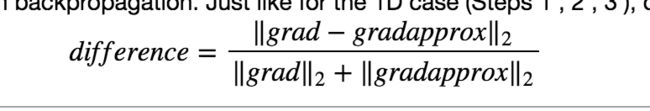
为啥要选上面的公式呢?是不是能够探寻到grad 和 gradapprox 之间微弱的差异,具有对差异超强的放大的能力????nonono
每个神经元的功能都是一样的么?
还是每次一层中每个神经元都有各自的功能,所有在编程的时候,是针对每个神经元编程的过程
指数加权平均数是什么东西?
从内存和效率方面对 360天 N天平均值计算的优化算法,N天越小越灵敏,N天越大,越滞后越平缓。
t(i)=β * t(i-1) + (1-β) * 历史当天温度(i)
β越小N就越小越灵敏,积分函数斜率越陡。但是如何从积分函数的面积中,如何获得标准差呢?如果是正交分布的话有置信区间的概念,2个方差对应的置信区间,对应的天数算是决定性的,也可以约等于N。这样的,到e分之1的时候停止。
1/e = 0.98(50) 。 50 = 1/(1-0.98)。就是这样一个规律。
指数加权的偏差修正
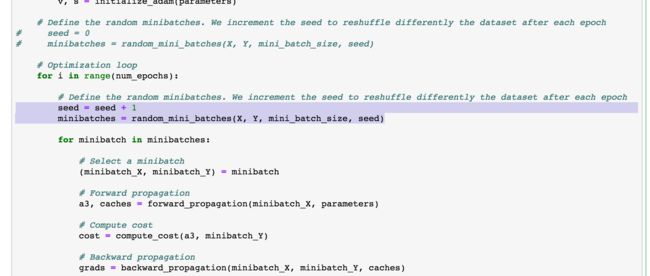
Mini-Batch
求解方法是,两次For循环,最外层是训练次数,最内层是样本集个数,对样本集个数遍历时dW是累计变更的。但是,难道就没有一种情况是,一直在水平摇摆,而不能下降?好奇怪
动量梯度下降法 Momentum
RMSProp ??为什么可以说Db 和 Dw 分别控制横轴 和 纵轴???控制摇摆?
??控制方式采用均方和么??

如何评估模型好坏?方差和偏差,如何解决过拟合?
如何加速模型训练?Momentum 和 RMSProp 或者 Adam优化算法
Adam优化算法

???为啥每一代都需要Shuffle呢?
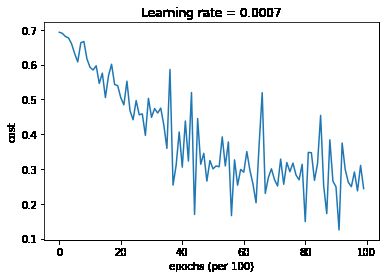
学习率衰减
加速学习有两个方向,1是减少横向摆动 2是增加纵向跨度。
通过RMSProp 和 Momentum 可以减少 横向摆动???
通过学习率可以提高纵向跨度???学习率要衰减的原因是可以 在鞍点附近左右跳动,而到不了马鞍点
局部最优的问题
超参的调试与实验
存在两种模式,熊猫模式 和 鱼子酱模式 ,熊猫模式数据量大但计算能力弱,鱼子酱模式是计算能力强的前提下可并行开工
因为超参的敏感度是指数级别的,非线性的的。比如指数加权中,1/(1-β) β越小影响越大呀!
归一化化网络的激活
归一化输入特征可加速学习过程
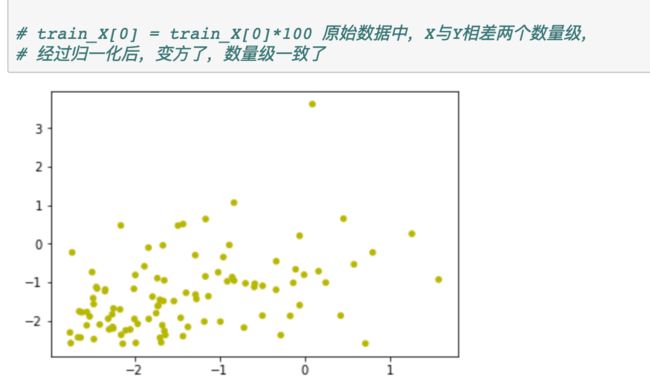
https://www.jianshu.com/p/540d56ef350f
???归一化在mini-batch中每个子集合每一代的计算流程没搞懂哎???
Softmax回归
SoftMax(映射为概率) 和 HardMax(映射为0或1)的区别
木有理解 最末端成本函数是如何计算的?方向传播中dz[L] 的导数公式是如何推到的?
。。。。。。。。。。。。
Tensorflow基础
不同角度的同一张照片,能被识别吗?
SoftMax的工作过程还是没有懂哎
正交化
业务Review(业务流程 架构设计 依赖关系)------ 组件化----插件化----- 端上DL
就是控制变量法,对每一层设定单独的旋钮用于调优该层结果。
单一数字评估指标
查全率 和 查准率 的含义,查全率的分母是全量样本猫的个数分子是真猫的个数,查准率的分母是模型识别为猫个个数分子是真猫的个数。
模型识别为猫但是不是真猫,查准率,假阳性
还有很多真猫模型没识别到,查全率
满足和优化指标
训练 开发 测试集
要求来自同一个数据分布
测试和真实数据在一个分布,保证了可使用
在同一分布中设计开发和测试集
什么时候改变开发集
先定义目标,也就是cost函数
改善模型表现
可避免偏差 理解人的表现
比较全面的给出了优化思路
http://mooc.study.163.com/learn/2001280004?tid=2001391037#/learn/content?type=detail&id=2001702135&cid=2001693043
误差分析
误差分析就是借助事件概率判断解决的优先级
不匹配数据划分
如何解决来自不同分布的数据集呢?目标原则上不能变的是,测试集和开发集都要用真实数据集。
针对来自不同分布的训练集和开发集,如何评估方差大 是因为不同分布造成的,还是方差本身就大?
Case:
- 存在可避免偏差:训练集误差 和 人类水平对贝叶斯误差 相差很大
- 方差问题:训练集 和 训练开发集 相差很大
- 数据集不匹配问题:训练开发集 和 开发集误差相差很大
关键词:人类水平对贝叶斯误差、偏差、方差、训练集(训练集误差,分布1)、训练开发集(分布1)、开发集(分布2)、测试集(分布2)。

如何解决数据分布不匹配的问题?
可以人工模拟合成,比如1w小时人声音 + 1小时车内噪音(1W次重放),但是要防止对噪音产生过拟合
迁移学习
通俗点就是 模块化开发,组合模式
多任务学习?????不懂???和SoftMax的区别
什么是端到端的深度学习
人脸身份识别,身份样本只有一个呀? DL是怎么训练的?
如何组装这些复杂的机器学习系统
池化层
卷积网络
线性激活
视觉规范
残差网络
用于训练深度网络,普通模型针对深度网络训练效率存在微笑曲线,而非越来越小
随着网络加深,训练结果错误率存在反弹。要通过残差网络搞定
训练开发集的作用
有各种模型,然后缺少的是参数调优师
卷积网路如何进行反向传播的梯度下降
!!!! 好奇的事,模型背后的依据是什么???
为什么是这样组合方式,而不是其他中,背后的数学依据是什么?
!!!对CONV卷积之前的理解是,指定过滤器功能,没想到居然要机器学习????他能学到啥么??
对过滤器的理解,需要自己手动指定过滤器并决定每层要放置那类的过滤器。
LeNet
?视觉识别对于训练集图片旋转后,还能被识别嘛??一张照片阔以被平移旋转移位得到万种新图片!!!
目标检测
目标识别、目标定位标记
YOLO 没有搞明白针对拆分为19*19网格后,是如何训练到识别局部?然后再拼装为一个整体并得到边界的?
YOLO 如何识别局部呢?
同一张图片的大小、明暗、平移旋转、局部 对结果是否有影响????
什么是目标检测?
目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是机器视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是机器视觉领域最具有挑战性的问题。
计算机视觉中关于图像识别有四大类任务:
分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
#### 序列模型
RNN recurrent neural networks

语言模型和序列生成
没有搞明白,语音文件作为输入方,他的入口在哪里?完全没有体现呀????
梯度下降
梯度下降是成本函数J 对 参数w、b的组成的函数求极小值的过程。
- 理解激活函数的作用,如何做到了线性可分。让线性归回转化为非线性,成为逻辑回归,为什么是凸函数呢?做二分类时,如何定义损失函数? https://www.zhihu.com/question/22334626
- 理解卷积的作用过滤器,测试边缘过滤器,真的有用么?或者垂直过滤器 https://jizhi.im/blog/post/intuitive_explanation_cnn 可视化http://scs.ryerson.ca/~aharley/vis/conv/flat.html
- 深入理解贝叶斯公式 https://jizhi.im/blog/post/bayes1
A1
从y = x^2介绍梯度下降的原理,引入无隐层的二元分类问题模型,z = w1x1+w2x2+b ,a = sigma(z),L= loss(a,y),J=1/m * (L的和)。我们需要求出来J(w,b)损失函数的极小值,J相当于Y,w和b相当于x,利用梯度下降求w和b。激活函数的作用?J一定是凸函数么?代价函数有哪些?正向反向传播的过程是怎么样的?
逻辑回归到DNN,以及各个环节的优化方案
CNN 和 RNN
A2
CNN过程可视化 https://zhuanlan.zhihu.com/p/42904109
https://nbviewer.jupyter.org/github/fchollet/deep-learning-with-python-notebooks/blob/master/5.4-visualizing-what-convnets-learn.ipynb#
https://blog.csdn.net/qq_15192373/article/details/78393520
https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650728746&idx=1&sn=61e9cb824501ec7c505eb464e8317915&scene=0#wechat_redirect

卷积层是如何做到对变形、移动后的图片有很好泛化能力?还有边缘检测是如何做到的?
过滤器真的有这么神奇?验证下呗
过滤器 + 激活函数+ 池化 + 最后的全连接层
损失函数:输出层具有类似分类交叉熵的损失函数
我们知道差量的化,可以去除参照物的干扰
RGB转黑白 Gray = R0.299 + G0.587 + B*0.114 ,基于单滤波器

神奇的过滤器


从开始到现在有很多颠覆想法的节点
- 多隐层网络,方向传播求梯度下降,逐层求偏导的过程,原来是真的在用链式法则呀,分清楚是求dA还是求dW
- 还有正则化的时候,对成本函数新增正则项,不能忘了对正则项求偏导
- Dropout的方式,哎妈呀还用到了掩码,在A之后用掩码再赋值给A,求导数时,也要用同样的掩码计算有效节点的导数,完成一次递归后,下次递归再更新掩码
numpy库:常用基本
contourf用于绘制等高线
https://www.cnblogs.com/lemonbit/p/7593898.html
https://morvanzhou.github.io/tutorials/data-manipulation/plt/3-3-contours/
为了画登高区域,也是拼了,居然用0.01密度的Grid,并预测每个Grid,再画到坐标中,因为密度高,所有就连接到了一起,形成了对模型二分类的分布图。
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)