Vulkan教程 - 18 阶段性总结
Vulkan学习几周了,稍微整理下。由于一开始的博客就是从环境搭建开始的,所以并没有对Vulkan的特性和教程的目标及步骤进行记录。这里主要就是做这个工作,所以这个总结并不是对Vulkan高屋建瓴的总结心得,暂时还没这么厉害。
Vulkan简介
简介
一句话来说,Vulkan是一个跨平台2D和3D图形接口,由Khronos Group(中文名为柯罗诺斯,是古希腊神话中的原始神)集团在2015年发布。
这里要稍微介绍下Khronos Group,它成立于2000年,致力于发展开发开放标准的应用程序接口,免费授权的移动设备API,实现多样化平台及设备上的高质量多媒体创作。该组织最为广泛接纳的标准有OpenGL及OpenGL ES等,为桌面及移动设备图形开发提供了有力支持。
特性
回到Vulkan上来,它的主要特性有:
1)跨平台支持,包括Windows、Linux及安卓等,对比下微软的DirectX只能运行在Windows平台,苹果的Metal也是仅限iOS和OS X;
2)充分发挥多核与多线程CPU性能;
3)驱动更加简单,从而降低CPU开销。对比下如OpenGL/OpenGL ES的驱动很复杂,总是开启错误检查,会带来额外的CPU开销,这个可以看下图:
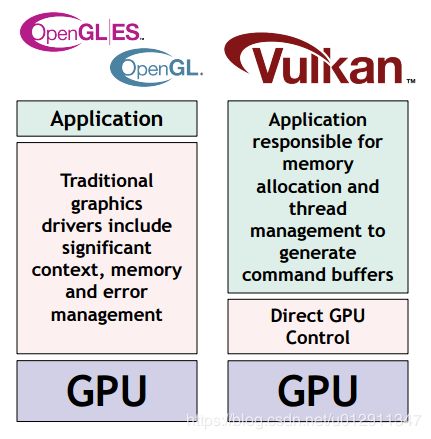
4)提供分层架构,使得驱动执行时的正确性验证和调试信息可以按需加载。在良好验证的应用情况下,我们可以节省掉错误检测和调试代码执行的开销;
5)Vulkan运行时不需要处理整个shader代码,而是处理SPIR-V中间代码,从而节省shader编译链接时间;
6)Vulkan不负责内存管理,多线程管理和并发访问,这些工作转移给应用程序负责,而Vulkan只专注于提供GPU功能给应用。
7)统一的接口。Vulkan支持不同平台和不同GPU产品,应用链接的是一样的图形库,以用的是一样的头文件。无论应用运行在哪里,只需要编写同一份代码,不再像OpenGL一样需要定义Windows/Android/Linux等相关的预处理宏来处理操作系统相关的代码。另外,Vulkan仍然保留了OpenGL时代就存在的Extension扩展功能。这是因为GPU厂商的架构确实没法完全统一,特殊功能的实现仍然需要扩展接口来支持。
8)高效的接口。图形程序的性能低下有很大比例是因为CPU的瓶颈,而其原因一般有两个,一是OpenGL ES驱动本身CPU开销过大,这包括驱动内部的GPU/CPU的同步等待,另一个是过多的draw call调用。
本章主要参考:
http://imgtec.eetrend.com/d6-imgtec/news/2016-01/7067.html
使用场景
一般来说,可以通过以下三种方式使用Vulkan:
1)应用程序直接调用Vulkan接口来访问GPU实现图形渲染和通用计算,在这种场景下面应用可以获得最大的灵活性和对GPU的控制权,但是其难度也是最高的。
2)第二种应用场景是应用程序通过工具库来调用Vulkan,而不是直接使用Vulkan接口。工具库对Vulkan接口做一个包装,使得应用程序更易于使用。这种工具库的一种实现方式就是直接把Vulkan包装成OpenGL或者OpenGL ES接口。例如Imagination就计划提供这样的工具库,使得利用OpenGL ES的老应用程序也能顺利得在Vulkan接口上面运行,而不需要更改任何代码。
3)第三种应用场景就是应用程序直接调用游戏引擎。因为应用程序不需要考虑如何用Vulkan实现,所以应用程序的实现比较简单。而专业的游戏引擎厂商负责优化对Vulkan的调用,使得应用可以获得Vulkan带来的性能提升。
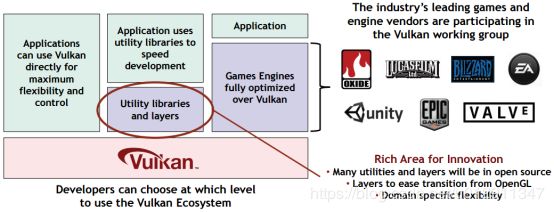
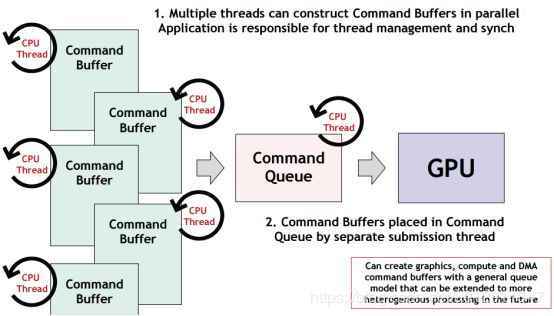
多线程支持
Vulkan作为一个直接提供GPU硬件功能的接口而不负责多线程渲染的调度以及线程并发访问的安全保护等工作,意味着Vulkan接口内部不再像OpenGL ES一样有过度的线程同步,CPU/GPU同步等操作。这些操作会为接口的运行效率带来不可预测的影响。每个独立的线程都可以并行地生成渲染的command buffer,这些command buffer最后会被提交给一个统一的command queue,GPU会按照command buffer提交的顺序来执行。任何需要跨线程访问的资源,都需要应用自己保证访问的一致性。
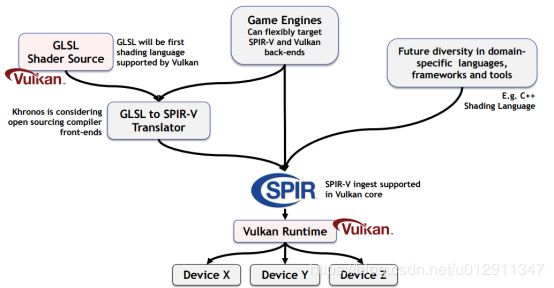
Vulkan的shading language环境
Vulkan不再使用GLSL作为输入,而是使用一个统一的中间代码SPIR(Standard, Portable Intermediate Representation)。GLSL会被解释器翻译成SPIR表示,这样Vulkan驱动就可以专注于shader后端优化,而不是前端语法解析和语义分析等。
Vulkan工具架构
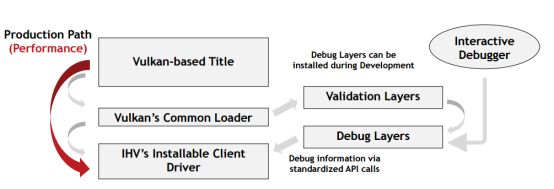
Vulkan提供灵活的架构可以使应用按照需求来启用驱动的错误检测和调试信息。如果应用是一个验证良好的程序,那么应用就直接使用Vulkan接口来访问GPU,不做任何的错误检测和调试,这可以节约大量的CPU开销,提升应用的性能。反之,应用可以通过Vulkan提供的Debug Layer和Validation Layer来实现错误检测和调试信息的输出。这使得应用在开发调试时可以获得大量的有用信息。一旦应用发布又可以去除掉这些CPU开销,使得性能提升。
Vulkan和传统图形API编程的区别
传统图形 API 和全新低级别API(Vulkan)之间有何区别?OpenGL等高级别API使用起来非常简单。开发人员只需声明操作内容和操作方式,剩下的都由驱动程序来完成。驱动程序检查开发人员是否正确使用API调用、是否传递了正确的参数,以及是否充分准备了状态。如果出现问题,将提供反馈。为实现其易用性,许多任务必须由驱动程序在“后台”执行。
在低级别API中,开发人员需要负责完成大部分任务。他们需要符合严格的编程和使用规则,还必须编写大量代码。但这种做法是合理的,开发人员知道他们的操作内容和希望实现的目的,但驱动程序不知道。因此使用传统API时,驱动程序必须完成更多工作,以便程序正常运行。采用Vulkan等API可避免这些额外的工作。 因此DirectX 12、Metal或Vulkan 也被称为精简驱动程序/精简API。大部分时候它们仅将用户请求传输至硬件,仅提供硬件的精简抽象层。为显著提升性能,驱动程序几乎不执行任何操作。
低级别API要求应用完成更多工作。但这种工作是不可避免的,必须要有人去完成。因此由开发人员去完成更加合理,因为他们知道如何将工作分成独立的线程,图像何时成为渲染对象(颜色附件)或用作纹理/采样器等等。开发人员知道管道处于何种状态,或哪些顶点属性变化更频繁。 这样有助于提高显卡硬件的使用效率。最重要的原因是它行之有效,我们能够观察到显著的性能提升。
但“能够”一词非常重要。它要求完成其他工作,但同时也是一种合适的方法。在有一些场景中,我们将观察到,OpenGL和Vulkan之间在性能方面没有任何差别。如果不需要多线程化,或应用不是CPU密集型(渲染的场景不太复杂),使用OpenGL即可,而且使用 Vulkan不会实现性能提升(但可能会降低功耗,这对移动设备至关重要)。 但如果我们想最大限度地发挥图形硬件的功能,Vulkan将是最佳选择。
该部分参考:
https://software.intel.com/zh-cn/articles/api-without-secrets-introduction-to-vulkan-preface
直观对比OpenGL ES和Vulkan:


另外是麒麟960芯片对Vulkan的测试:

Vulkan示例分析
环境搭建
主要是Windows上,下载Vulkan SDK,下载GLFW(Graphics Library Framework),下载GLM(OpenGL Mathematics),配置VS,验证Vulkan扩展。
目标及步骤
绘制三角形需要哪些步骤?
- 实例和物理设备选取;
- 逻辑设备和队列族;
- 窗口表面和交换链;
- 图像视图和帧缓冲;
- 渲染通道;
- 图形管线;
- 命令池和命令缓冲
- 主循环
步骤解析
第一步就是要建立Vulkan实例,这也是Vulkan应用程序的起始。通过描述你的应用程序和你将要使用什么API扩展来创建实例,之后查询Vulkan支持的硬件并选择一个或多个VkPhysicalDevice。
第二步就要传将逻辑设备VkDevice了,此时你要更详细描述你需要使用哪些VkPhysicalDevice特性,比如多视口渲染和64位浮点数等。还要指定使用哪些队列族。大多数的Vulkan操作,如绘制命令和内存操作,都是提交到VkQueue中异步执行的。队列是从队列族中分配出来的,每个队列族支持一组特定操作。例如,图形、计算和内存转移操作可能有着单独的队列族。队列族的可用性也可以用作物理设备选取的一个显著因素。可能一个支持Vulkan的设备却不提供图形功能,但是当前阶段的显卡支持Vulkan的都基本支持了我们所需的队列操作。
第三步就是创建窗口和呈现渲染好的图像了。这需要两个组件,一个窗口表面(VkSurfaceKHR)和一个交换链(VkSwapchainKHR)。KHR后缀表示这些对象是Vulkan扩展的一部分。Vulkan API本身是跨平台的,表面则是要渲染到的窗口的跨平台抽象,通常用一个原生窗口句柄引用来实例化,例如Windows平台上就是HWND。
交换链就是一批渲染目标,它的基本目的就是保证我们当前渲染的图像和已经在屏幕上的那个是不一样的。保证只显示完整图像时很重要的,每次我们想要绘制一帧的时候都要向交换链请求提供一个图像。当我我们完成一帧的绘制后就将图像返回给交换链以便它在某个时候呈现到屏幕上。渲染目标个数以及将完成的图像呈现到屏幕上所需的条件依赖于呈现模式。常见的呈现模式有双缓冲(垂直同步)和三缓冲。
第四步,为了绘制从交换链获取的图像,将它包装成VkImageView和VkFramebuffer。图像视图引用了要用的图像的某个特殊部分,帧缓冲引用了用于颜色、深度和模板目标的图像视图。因为交换链中可能有很多不同图像,我们预先为每个图像创建一个图像视图和一个帧缓冲,然后在绘制的时候选择正确的那个。
第五步,Vulkan的渲染通道描述了渲染操作中用的图像的类型,以及如何使用它们,如何对待其内容。对于这个教程的三角形程序来说,我们就告诉Vulkan我们将使用单个图像作为颜色对象,且要在绘制操作之前被清空为一个纯色。然而渲染通道只描述了图像类型,VkFramebuffer实际上会向这些槽绑定特定的图像。
第六步,Vulkan的图形管线通过创建一个VkPipeline对象来建立,它描述了显卡的可配置状态,比如视口大小和深度缓冲操作以及使用VkShaderModule对象时的可编程状态。VkShaderModule对象是从着色器代码创建的,我们会通过引用渲染通道指定。
Vulkan和现有API相比最显著的特性是它的所有图形管线配置都要提前设置。这意味着如果你想要切换到一个不同的着色器,或者稍微改变顶点布局,你都要完全重建图形管线。这也意味着你要为所有你想要的渲染操作的不同组合提前建立许多VkPipeline对象。只有一些基础配置,如视口大小和颜色清除等可以动态改变。所有的状态都要明确描述,比如,连默认颜色混合状态都没有。
好消息是,因为你相当于在做提前编译而不是即时编译,驱动就会有更多的优化机会,运行时也更容易得到可预测的表现,因为像切换到不同图形管线这也的大型状态改变都是明确设定好的。
第七步,命令池和命令缓冲。就和之前提到的一样,Vulkan中许多的操作像绘制命令等都要提交到一个队列中。这些操作首先需要记录到VkCommandBuffer,然后才能提交。这些命令缓冲是从VkCommandPool分配的,VkCommandPool又和一个特定队列族相关联。为了绘制一个简单的三角形,我们要用如下操作来记录一个命令缓冲:
开始渲染通道;
绑定图形管线;
绘制三个顶点;
结束渲染通道。
因为帧缓冲中的图像依赖于交换链到底给我们哪一个图像,我们要为每个可能的图像记录命令缓冲并在绘制的时候选择正确的那个。
第八步就是主循环了。现在绘制命令已经包装成一个命令缓冲,主循环就比较直白了。首先用vkAcquireNextImageKHR从交换链获取图像,然后为该图像选择合适的命令缓冲,用vkQueueSubmit执行。最终,返回图像到交换链以便用vkQueuePresentKHR呈现到屏幕。
提交到队列的操作是异步执行的,因此我们必须用类似信号量的同步对象来确保正确的执行顺序。绘制命令缓冲的执行一定要等待图像获取完成,否则可能会在渲染的时候用了一个还在读取用于展示到屏幕上的图像。vkQueuePresentKHR调用需要等待渲染完成,要使用第二个信号量来标记渲染完成。
最后再总结一下,绘制一个三角形要做的工作如下:
创建一个VkInstance;
选择一个支持的显卡(VkPhysicalDevice);
创建一个VkDevice和一个VkQueue来绘制和呈现;
创建一个窗口,窗口表面和交换链;
将交换链图像包装到VkImageView;
创建一个渲染通道来指定渲染目标和用法;
为渲染通道创建帧缓冲;
建立图形管线;
用绘制命令为每个可能的交换链图像分配和记录命令缓冲;
通过获取图像来绘制帧,提交正确的绘制命令缓冲并返回图像到交换链。
代码演进
这里是做分享的时候讲述的,就是教程如何通过各个章节添加不同内容,如何将三角形的硬编码改进,引入顶点缓冲,绘制矩形及引入MVP等,所以这里就不再敲一遍了。