对于要有扎实的java基础,集合是必须掌握的,而且精读这部分的源码很有用,也很有必要。而LinkedList是在java.util包下,和java.io,java.lang都是比较常用,而且比较简单。看看它们的源码有助于锻炼我们看源码的感觉,也了解一下大神们写代码的风格。看这些源码的目的,更多是为了增加阅读代码能力。
这里只写LinkedList的初始化和add()方法的源码分析,先放一张Collection集合的分类简图: 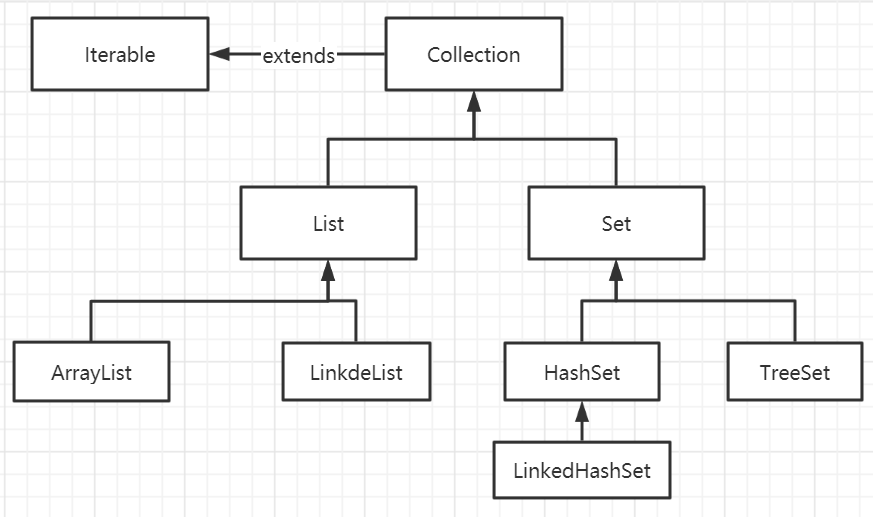
LinkedList采用双向链表存储方式
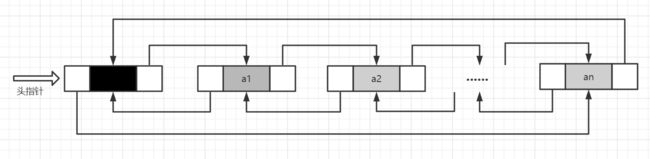
缺点:遍历和随机访问元素效率低下。
优点:插入,删除元素效率比较高(但是前提也是必须先低效率查询才可,如果插入删除发生在头尾可以减少查询次数)。
那开始吧!
1 public class TestLinkedList { 2 3 public static void main(String[] args) { 4 LinkedListlist = new LinkedList (); 5 list.add(1); 6 list.add(2); 7 list.add(3); 8 } 9 }
点进LinkedList发现只是一个构造函数,有3个变量(这里只放部分代码)
1 public class LinkedList2 extends AbstractSequentialList 3 implements List , Deque , Cloneable, java.io.Serializable 4 { 5 transient int size = 0; //默认长度0 6 transient Node first; //上一个元素 7 transient Node last; //下一个元素 8 9 public LinkedList() { 10 } 11 12 private static class Node { 13 E item; 14 Node next; 15 Node prev; 16 17 Node(Node prev, E element, Node next) { 18 this.item = element; 19 this.next = next; 20 this.prev = prev; 21 } 22 } 23 24 25 }
Node是LinkedList的一个内部类,Node指的是双向链表的结点(包括3部分,中间数据item,左右两边的指针,指向前prev后next的结点)
执行到LinkedList
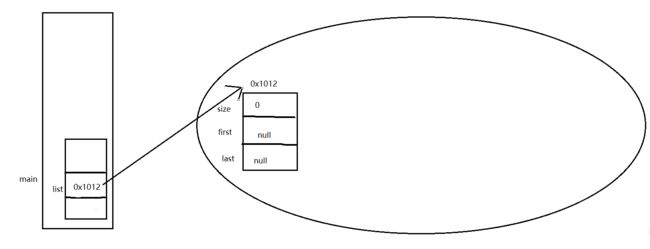
我们再看看add()方法
1 public boolean add(E e) { 2 linkLast(e); 3 return true; 4 } 5 6 /** 7 * Links e as last element.//将e链接为最后一个元素 8 */ 9 void linkLast(E e) { 10 final Nodel = last; 11 final Node newNode = new Node<>(l, e, null); 12 last = newNode; 13 if (l == null) 14 first = newNode; 15 else 16 l.next = newNode; 17 size++; 18 modCount++; 19 }
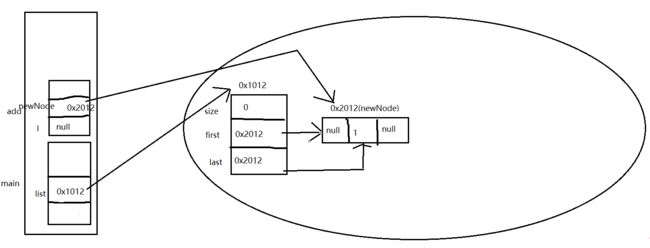
执行add(1)方法后,将开始last=null赋给了一个变量l,这时候new Node<>(l, e, null);就是new Node<>(null, 1, null),在栈里创建了对象(Node结点)。

到了12行last = newNode;last就不是null了,是0x2012,也就指向了下一个结点
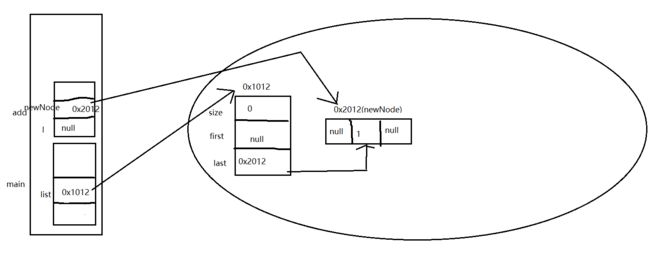
在往后面看if判断,这是l是等于null的,就把first = newNode;first就不是null了,是0x2012(newCode),也就指向了上一个结点。因为只有一个结点,前后都是它自己。
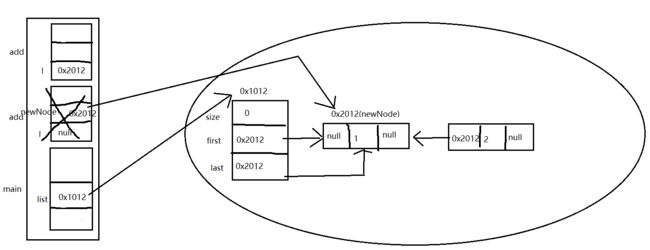
继续add,l=0x2012,所以new Node<>(l, e, null);就是new Node<>(0x2012, 2, null),所以新增的结点就指向了上一个0x2012。
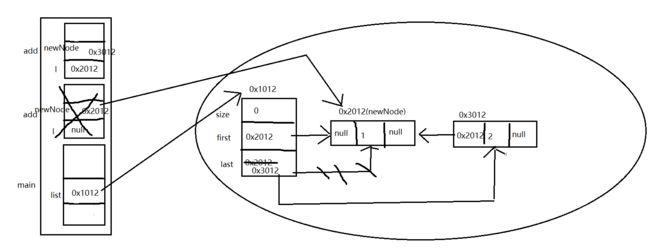
然后再last=newNode,就是0x3012。它就不执行0x2012了。
这个时候if判断,l已经不等空了,执行l.next=newNode。newNode是0x3012,l是0x2012,l.next就是0x2012这个结点的next属性,也是个Node。

内存图是这样的:
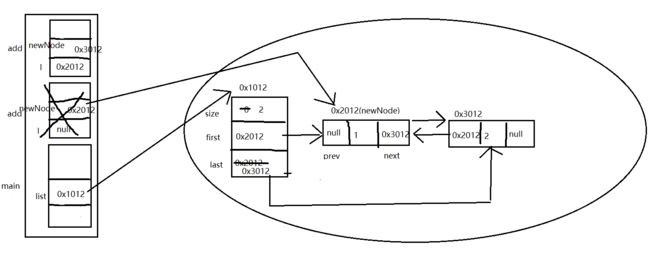
最后再add
