VulkanAPI架构
Vulkan API架构及详述
一、API架构
下图是Vulkan中主要的组件以及它们之间的关系:

1.1 Device
Device很好理解,一个Device就代表着一个你系统中的物理GPU。它的功能除了让你可以选择用来渲染(或者计算)的GPU以外,主要功能就是为你提供其他GPU上的资源,例如所有要用到显存的资源,以及接下来会提到的Queue和Synchronization等组件。

1.2 Pipeline
第二个主要的组件,比Device复杂很多,就是Pipeline。一个Pipeline包含了传统API中大部分的状态和设定。只不过Pipeline是需要事先创建好的,这样所有的状态组合的验证和编译都可以在初始化的时候完成,运行时不会再因为这些操作有任何性能上的浪费。但正是因为这一点,如果你不同的Pass需要不同的状态,你需要预先创造多个不同的Pipeline。然而我们不能把所有渲染需要的信息全都prebake进pipeline中,一个Pipeline应该是可以通过绑定不同的资源而复用的。接下来介绍的几个组件就可以被动态的绑定给任何Pipeline。

1.3 Buffer
接下来是Buffer。Buffer是所有我们所熟悉的Vertex Buffer, Index Buffer, Uniform Buffer等等的统称。而且一个Buffer的用途非常多样。在Vulkan中需要特别注意Buffer是从什么类型的内存中分配的,有的类型CPU可以访问,有的则不行。有的类型会在CPU上被缓存。现在这些内存的类型是重要的功能属性,不再只是对驱动的一个提示了。

1.4 Image
Image在Vulkan中代表所有具有像素结构的数组,可以用于表示纹理,Render Target等等。和其他组件一样,Image也需要在创建的时候指定使用它的模式,例如Vulkan里有参数指定Image的内存Layout,可以是Linear,也可以是Tiled Linear便于纹理Filter。如果把一个Linear layout的Image当做纹理使用,在某些平台上可能导致严重的性能损失。类似传统的API,纹理本身并不直接绑定给Pipeline。需要读取和使用Image则要依赖于ImageView。

1.5 Binding Resources
讲了几种不同类型的内存, 但是内存是从什么地方分配的呢?在Vulkan中,所有内存都分配与一个指定的Heap。一个Device也许支持几种不同类型的Heap,有些也许可以分配Mappable的内存,有些不行。具体的类型取决于程序运行的平台。值得注意的是,Vulkan Heap分配的内存和最终的Vulkan组件例如Buffer和Image直接可以不,也不应该是一对一的映射。一段内存可以分配成数段,并且分配给不同的资源使用。某种程度上这样的资源复用也是Vulkan基本的设计哲学之一。
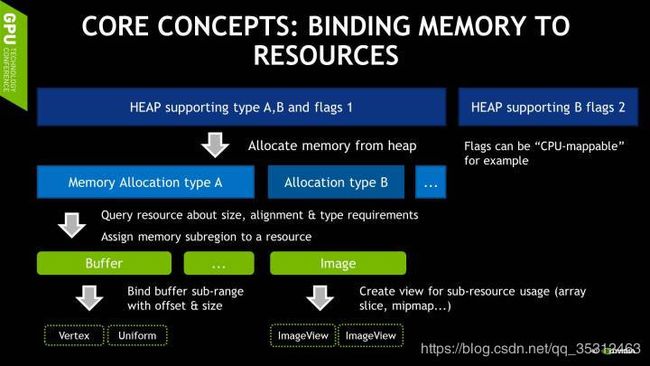
上面提到,Buffer和Image可以动态的绑定给任意Pipeline。而具体绑定的规则就是由Descriptor指定。和其他组件一样,Descriptor Set也需要在被创建的时候,就由App指定它的固定的Layout,以减少渲染时候的计算量。Descriptor Set Layout可以指定绑定在指定Descriptor Set上的所有资源的种类和数量,以及在Shader中访问它们的索引。App可以定义多个不同的Descriptor Set Layout,所以如何为你的程序或者引擎设计Descriptor Set的Layout将是优化的重要一环。当然,程序也可以拥有多个指定Layout的Descriptor Set。因为Descriptor Set是预先创建并且无法更改的,所以改变一个绑定的资源需要重新创建整个Descriptor Set,但改变一个资源的Offset可以非常快速的在绑定Descriptor Set的时候完成。一会我会讨论如何利用这一点来实现高效的资源更新。

1.6 Command Buffer
介绍了那么多组件,都是渲染需要的数据。那么Command Buffer就是渲染本身所需要的行为。在Vulkan里,没有任何API允许你直接的,立即的像GPU发出任何命令。所有的命令,包括渲染的Draw Call,计算的调用,甚至内存的操作例如资源的拷贝,都需要通过App自己创建的Command Buffer。Vulkan对于Command Buffer有特有的Flag,让程序制定这些Command只会被调用一次(例如某些资源的初始化),亦或者应该被缓存从而重复调用多次(例如渲染循环中的某个Pass)。另一个值得注意的是,为了让驱动能更加简易的优化这些Command的调用,没有任何渲染状态会在Command Buffer之间继承下来。每一个Command Buffer都需要显式的绑定它所需要的所有渲染状态,Shader,和Descriptor Set等等。这和传统API中,只要你不改某个状态,某个状态就一直不会变,这一点很不一样。

1.7 Command Buffer Pool
Command Buffer Pool是一个需要注意的多线程相关的组件。它是Command Buffer的父亲组件,负责分配Command Buffer。Command Buffer相关的操作会对其对应的Command Buffer Pool里造成一定的工作,例如内存分配和释放等等。因为多个线程会并行的进行Command Buffer相关的操作,这个时候如果所有的Command Buffer都来自同一个Command Buffer Pool的话,这时Command Buffer Pool内的操作一定要在线程间被同步。所以这里建议每个线程都有自己的Command Buffer Pool,这样每个线程才可以任意的做任何Command Buffer相关的操作。

Command Buffer Pool的另一个性质就是支持非常高效的重置。一旦重置,所有由当前Pool分配的Command Buffer都会被清零,并且不会有任何内存管理上的碎片。所以程序只要为每一个帧和线程的组合分配一个Command Buffer Pool,就可以利用这一点,在更新Round Robin中的Command Buffer时非常快速的将需要的Buffer清零。

1.8 Descriptor Pool
另一个类似Command Buffer Pool的组件,就是Descriptor Pool。所有Descriptor Set都由Descriptor Pool分配,Descriptor Set操作会导致对应的Descriptor Pool工作而且需要线程间同步,并且Descriptor Pool也支持非常高效的将所有由当前Pool分配的Descriptor Set一次性清零。所以程序应该为每个线程分配一个Descriptor Pool,可以根据Descriptor Set的更新频率,创建不同的Descriptor Pool,例如每帧、每场景等等。
1.9 Queue
最后一个关键组件, Queue,是Vulkan中唯一给GPU递交任务的渠道。Vulkan将Queue设计成了完全透明的对象,所以在驱动里没有任何其他的隐藏Queue,也不会有任何的Synchronization发生。在Vulkan中,给GPU递交任务不再依赖于任何所谓的绑定在单一线程上的Context,Queue的API极其简单,你向它递交任务(Command Buffer),然后如果有需要的话,你可以等待当前Queue中的任务完成。这些Synchronization操作是由Vulkan提供的各种同步组件完成的。例如Samaphore可以让你同步Queue内部的任务,程序无法干预。Fence和Event则可以让程序知道某个Queue中指定的任务已经完成。所有这些组件组合起来,使得基于Command Buffer和Queue递交任务的Vulkan非常易于编写多线程程序。后文会简单讨论一些常见的多线程模式。最后,和前面提到的一样,Queue不光接收图形渲染的调用,也接受计算调用和内存操作。

二、相关API简述
2.1 设备初始化
2.1.1 Instance --> GPU --> Device
Instance表示具体的Vulkan应用。在一个应用程序中可以创建多个实例,这些实例之间相互独立,互不干扰。
当调用API创建Vulkan实例的时候,Vulkan SDK内部会经由驱动装载器(loader)查找可用的GPU设备。
创建Vulkan实例需要两个输入信息:
- 应用程序的信息
- 内存分配回调函数
Vulkan通过用户输入的内存分配器来分配内存。
创建好Instance,就可以用Instance枚举所有可用的Vulkan GPU设备。
有了GPU设备,就可以获取具体GPU的信息。如果系统中安装了多个GPU设备,就可用GPU信息比较GPU设备之间的兼容性等。
找到了合适的GPU后,就可以通过GPU创建设备示例。
2.2、绘制
2.2.1 Queues
有了设备,就可以创建命令队列。命令队列是与设备绑定的,不能跨设备使用。
队列封装了图形、计算、直接内存访问功能,独立调度、异步等调度操作。
2.2.2 Command Buffer
有了设备,就可以创建命令缓冲。命令缓冲是绘制命令的批次集合。
用户可创建任意多的命令缓冲,支持在多线程中创建。
Command占用的内存是通过Command Buffer内存池动态分配,不需要指定内存池的大小。
2.2.3 Command
在命令缓冲区中可以创建多个命令。多个命令完成批次即命令缓冲后,可以重复利用。
这里有点像OpenGL里面的NameList。
Command Buffer的操作使用pipeline barrier区分。barrier可以等待和触发事件。
注:
- 这里可以看出Command被包装在Command Buffer中,当把Command
Buffer提交给Queue中后,Queue中执行的是Command Buffer中的Command。 - Command Buffer和Queue的类别需要匹配,否则不能正确执行,但一个Command
Buffer并不会跟任何Queue有联系。也就意味着,一个Command Buffer可以被提交给多个Queue,只要他们的类别匹配。
2.2.4 Shaders
使用设备创建Shader。
同样支持多线程。
2.2.5 Pipeline
渲染管线同样需要设备创建。
渲染管线状态包括:Shaders,混合、深度、剔除、模版状态等。
另外Vulkan提供了API保存和加载渲染管线的状态。
2.2.6 Descriptors
Vulkan资源都用descriptor表示, descriptor分成descriptor set,descriptor set从descriptor pool分配。
每个descriptor set都有个layout布局,布局是在pipeline创建的时候确定的。layout在descriptor set 和pipeline之间共享,并且必须匹配。
pipeline可以切换使用相同layout的descriptor set。
多个不同layout的set可以组成链在一个pipeline中使用。
2.2.7 Render Pass
Render Pass表示一帧的某个阶段,包含了绘制过程中的很多信息,包括:
- Layout和framebuffer attachment的类型
-Render Pass在开始和结束的时候该做什么
-Render Pass影响framebuffer的区域-分块渲染和延迟渲染需要的信息
2.2.8 Drawing
Draws位于Render Pass内,在Command Buffer的上下文中执行。支持多种绘制类型:基于索引的和非索引的,直接的和间接的等
3.1、多线程支持
3.1.1 同步
使用事件同步任务,可以设置、重置、查询和等待事件。
Command Buffer执行完成后可以触发事件
3.1.2 任务队列
任务在设备所属的队列中执行,准备好的Command buffer送到队列中执行。
队列保留内存,驱动不负责管理内存,同样由程序管理。
队列可以触发事件,等待信号量。
4.1、呈现
4.1.1 Presentation
展现就是如何在屏幕上显示图片。
可显示的资源使用与framebuffer绑定的“图片”展现,由与平台相关的模块创建,即所谓的窗口系统接口WSI。
WSI用了列举系统的显示设备和视频模式,全屏,控制显示垂直同步等。
Presenta跟命令缓冲一起进入队列。
5.1、资源创建和释放
资源包括CPU资源和GPU资源。
CPU资源通过vkCreate创建,GPU资源由vkAllocMemory创建,由vkBindObjectMemory与CPU对象绑定。
应用程序负责Vulkan对象的析构,需要保证顺序。Vuilkan资源没有引用计数机制,都需要显式释放。