【YOLO学习笔记——数据集】之一YOLO数据集制作1(含LabelImg工具讲解)
前言
如果你有什么问题,希望跟我能够一起交流,除了通过博客交流外,欢迎你加入我的QQ群,一起交流有关于机器学习、深度学习、计算机视觉有关内容。目前我并未确定具体的研究方向,所以现在 处于广泛涉猎阶段,希望我们能够一起沟通。下图是我的群二维码:

一、综述
YOLO有自己训练好的数据集,在YOLO v2 中,数据集可检测的类别达9000种以上,但是9000毕竟不是全部,它能涵盖大部分的物体识别,但是可能对于某些用户来说是不够的,所以我们需要学习它的数据集制作方法。
我把数据集分为以下几个部分:
1.数据集的搜集,这一部分主要是在网上搜集整理相关数据集的图片,比如我要做某种猫的数据集,我需要上网上查找这种猫的图片;我需要做自己做的手工艺品的数据集,那我需要自己拍摄等等。
2.数据集的标注,计算机去认识一个物体,需要人去告诉他,哪个物体,是什么。就像我们在小时候,我们的父母会一点一点耐心教我们,什么是桌子,什么是椅子,什么是筷子,什么是树,什么是花……数据集的标注就是一个“教授”的过程。
3.数据集的训练,不是别人一教,你就能学会的,你需要不断地练习,比如说话,小时候父母不厌其烦的教我们;比如写汉字,中国人最应该骄傲的就是我们学会了世界上最难的一门语言,并且能够熟练应用。这就是因为我们从上学开始,老师就教我们写字,一写就是好几十遍……计算机也是如此,想让计算机明白什么是花,什么是自行车,就要让他“训练”,让他学会。
4.数据集的应用,我们学会说话,学会认识物体,目的就是为了应用,学会说话,我们可以交流,认识自行车,是我们能够方便交通……数据集也一样,训练好的数据集的目的就是为了应用,或者说,我们训练数据集是因为我们需要应用这个数据集,例如,我们需要检测人流量,首先我们需要识别人,当然现在就有很多人体识别的算法,如果我们要采用数据集来识别,我们需要先制作一个数据集,然后在应用数据集完成我们需要的功能。在我写的第一篇YOLO博客:《【YOLO学习笔记】之YOLO初体验》中就是对数据集的一个简单应用。
在这篇博客中,主要讲述前两个方面:数据集搜集 与 数据集标注。
首先先声明几个问题,希望大家注意:
1.我的所有操作都是在Windows系统上,不是Linux,不会Linux系统的同学无需担心。
2.在图片搜集过程中,我用到了OpenCV和C++语言,用的是VS2015编辑器。相关安装教程请看:《【opencv学习笔记】001之opencv配置(win10+VS2015+OpenCV3.1.0)》,关于OpenCV版本,希望大家暂时使用3.4.0以内,3.0.0以上,防止出现因为版本问题引发的错误。我处理的是OpenCV获取的摄像头的视频,如果大家是自己下载的视频,对代码做一些简单修改就好。
3.在图片标注过程中,我用到的软件是LabelImg,下载地址。有需要的同学自行下载。这个软件的好处是大家可以直接打开使用,无需要其他操作,以前有一种方法是用Python去操作,会有各种报错,比较麻烦,咱们用LabelImg的目的是为了做数据集,而不是为了去排错。
二、数据集搜集
爬虫是个好东西,你要学着用,如果你会爬虫,会数据清洗,数据集搜集对你来说就是小kiss,当然这个难度是比较大的,我支持大家在学习人工智能的同时懂一点大数据,懂一点爬虫。但是我更希望大家如果真的想进军人工智能,那就专注人工智能,因为人工智能也是一个很庞大的体系,其他领域要广涉猎,但是不要学太深,专注最重要。剩下的靠团队协作,木桶原理依然很重要,但是内容要变一变:一个团队是一个木桶,这个木桶能盛多少水,一方面要看每一块木板是不是完好无损,这块木板有多长,另一方面要看每一块木板之间的契合度如何。
我以后可能会讲爬虫,简单的爬虫我们是需要会的,因为我们既要有专长,也要有广泛涉猎。但是在这篇博客中我不会讲,我希望能把这篇博客的重心放在数据集上,而不是爬虫,更不是数据清洗。
我们在实际应用中,目的是为了识别物体,很少是为了去做一个完善的数据集,很多情况下,我们是在识别固定的几个物体,经常应用于视频实时监测跟踪。所以我讲的这种方法是针对这类情况的,因为这种情况应用在目前来说更为广泛。
所以我们需要的是在视频中将包含所要截取的图片弄出来,为了做测试,我只好用自己的“丑照”,还可能有各种各样稀奇古怪的表情,还希望大家能够谅解。
在学习之初,大家可以下载一段电影(录屏也可以),或者自己拍摄一段视频,这段视频中要有你的目标,现在,我假设你已经有一个后缀名为mp4的视频文件,并且,视频文件中已经有你的目标。
接下来,我们需要对视频做处理,每隔几秒,或者几毫秒(大家根据自己的电脑性能做调整)截取一张包含目标的图像。(在OpenCV中,用帧来计数,所以用帧来控制截取速度)
这段代码比较简单,我就直接在下面写出来,重要位置会加上注释。。
#include"stdafx.h"
#include
#include
using namespace std;
using namespace cv;
int main()
{
Mat frame;
int num = 0;
int n = 1;
string filename;
string Imagespath = "E:/img/"; // 保存图片的文件夹路径一定要有,因为OpenCV不会自动创建文件夹
VideoCapture capture(0);//读取视频,存放视频的绝对路径
while (true)
{
capture >> frame;//将视频读入mat对象
if (frame.empty())
{
printf("read video error");
system("pause");
}
/**************************定位验证**********************************/
rectangle(frame, Point(100,0), Point(580,480), Scalar(0, 0, 255), 1, 8, 0);
imshow("video", frame);
/*********************保存图片*************************************/
//int_to_string
string string_temp;
stringstream stream;
stream << n;
string_temp = stream.str();
filename = Imagespath + string_temp + ".jpg";
num++;
if (num >= 3)//确定多少帧截取一张图片,10就是10帧截取一张
{
//截取指定位置
Rect rect(100, 0, 480, 480);//左上顶点坐标,宽高
Mat image_roi = frame(rect);
//可以在这加入仿射变换
cout << "now is writing:" << string_temp << ".jpg" << endl;
imwrite(filename, image_roi);
num = 0;
n++;
}
waitKey(30);
}//while()
return 0;
}
得到的图片如下

注意,名字要从1开始一直往后,如果大家自己找的图片,不是这样批量生成的,大家可以用看图软件批量修改名称,小编用的是2345看图王。然后将图片放在一组文件夹下面,具体如下:

在VOC 2018文件夹下有五个文件夹,搜集好的图片放在JPEGImages文件夹下;标注后数据保存在Annotations文件夹下;labels文件夹在数据集的训练时用到;在ImageSets文件夹下有下面三个文件夹,在Main文件夹中有一个train.txt文件,后面数据集训练会详细讲解。

三、数据集标注
接下来就是对20个图片做标注了,这一步,需要大家细心,一个图片都不能少,20个还好,如果是好几千甚至几万呢?
我们用到的软件是LabelImg。

大家直接点击打开使用即可。

它会自动运行一个黑窗体,然后打开软件,不需要大家自己编译运行,不用担心有代码错误的问题。我个人习惯最大化,大家根据自己习惯调节。

一般情况下,我们只需要做如下几个步骤。
1.打开图片所在文件夹。选择图片文件夹,就会在右下角显示文件夹下所有的图片。

2.修改输出文件夹,报错标注数据。
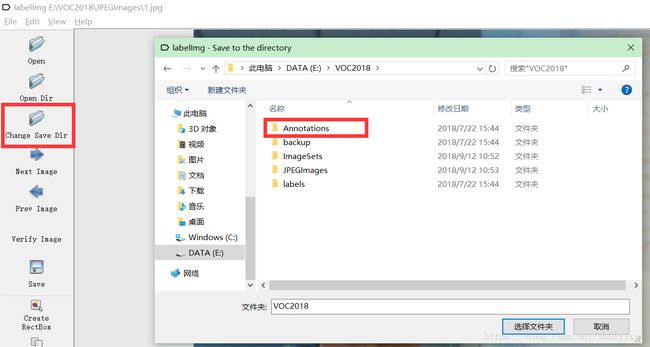
3.图片标注。
输入法切换为英文,然后按“W”,会出现下面的十字。
然后按住鼠标左键,拖动,直到将全部目标包括在内,注意,选择区域尽量小。

放开鼠标就是下面的样子,在文本框中输入目标名称,例如:head。

在右上角就会多一个类别:

然后依次点击-save保存-Next Image下一张

再次按W的时候,他会显示,默认为head,如果你有多个类别,那就从下面选择即可。

然后一直重复:W - 鼠标选择 - save - next image ;直到所有都标注完成。
标注完成后,就会在Annotations文件夹下产生如下的xml文件。

打开这个文件,就可以看到保存的就是我们标注好的信息。任意打开一个,文件内容如下:
