Jaeger 提供了一整套的分布式链路追踪方案,也是最早实现Opentracing协议的框架之一。今天我们来简单分析一下java客户端的Span异步发送机制
1.异步发送需求简述
我们知道,在Java应用程序中,如果有一些数据不是特别重要,但是又产生得比较多的时候,我们在为了保证程序性能的情况下就会选择采用异步的方式来保存和发送数据。比如日志,Trace数据就是属于这一类的数据。所以这一类的数据最适合暂时保存在内存中然后异步存储。
那么要实现这类异步的需求有什么具体的要求呢?
我觉得至少应该实现以下几点
- 占用的资源不能太多。这其中包括线程资源,内存资源等。
- 可以定时将内存中的数据保存起来。
- 可以批量保存数据,提升性能。
- 参数可配置化
- 最重要的一点,无论如何不能影响主业务。
2.Jaeger 实现原理分析
少废话,先上原理图,所谓一图胜千言。
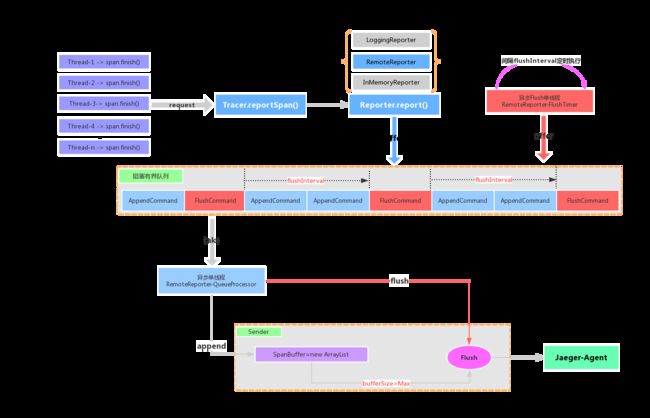
下面我们来简单分析流程
1.在每一个线程中都会产生很多Span数据,当Span结束的时候会调用Tracer对象的reportSpans方法,然后Tracer就会委托给Reporter对象来发送Span数据。
public class JaegerSpan implements Span{
@Override
public void finish() {
if (computeDurationViaNanoTicks) {
long nanoDuration = tracer.clock().currentNanoTicks() - startTimeNanoTicks;
finishWithDuration(nanoDuration / 1000);
} else {
finish(tracer.clock().currentTimeMicros());
}
}
@Override
public void finish(long finishMicros) {
finishWithDuration(finishMicros - startTimeMicroseconds);
}
private void finishWithDuration(long durationMicros) {
synchronized (this) {
if (finished) {
log.warn("Span has already been finished; will not be reported again.");
return;
}
finished = true;
this.durationMicroseconds = durationMicros;
}
// 只有需要采样的时候才发送Span
if (context.isSampled()) {
// 委托给Tracer发送
tracer.reportSpan(this);
}
}
// other functions
// ....
}
public class JaegerTracer implements Tracer, Closeable{
void reportSpan(JaegerSpan span) {
// 委托给Reporter发送
reporter.report(span);
metrics.spansFinished.inc(1);
}
// other functions
// ....
}
2.然后呢,Reporter对象比较会骗人,它实际上呢,并没有真正的发送给出去,而是将Span数据包裹一下,以Command的形式加到了线程安全的阻塞队列中。然后Reporter对象又开启了两个异步线程:
jaeger.RemoteReporter-QueueProcessor 负责不断地消费阻塞对象的Command对象,然后丢给Sender的缓冲区 。
jaeger.RemoteReporter-FlushTimer 定时地发送FlushCommand,然后让Sender Flush自己的缓存区
所以,我们看到队列中有多种Command,如果队列画成图的话,就类似于下面这个样子。

其实还有另外一种Command(CloseCommand),后面我们再讲
public class RemoteReporter implements Reporter {
private RemoteReporter(Sender sender, int flushInterval, int maxQueueSize, int closeEnqueueTimeout,
Metrics metrics) {
this.sender = sender;
this.metrics = metrics;
this.closeEnqueueTimeout = closeEnqueueTimeout;
commandQueue = new ArrayBlockingQueue(maxQueueSize);
// start a thread to append spans
queueProcessor = new QueueProcessor();
queueProcessorThread = new Thread(queueProcessor, "jaeger.RemoteReporter-QueueProcessor");
queueProcessorThread.setDaemon(true);
queueProcessorThread.start();
flushTimer = new Timer("jaeger.RemoteReporter-FlushTimer", true /* isDaemon */);
flushTimer.schedule(
new TimerTask() {
@Override
public void run() {
flush();
}
},
flushInterval,
flushInterval);
}
@Override
public void report(JaegerSpan span) {
// Its better to drop spans, than to block here
// 注意这里用的是offer方法。如果超过了队列大小,那么就会丢弃后来的span数据。
// 而且这里不是简单地把span加入到队列中,而是用Command包装了一下。这就是实现定时flush数据的秘诀。我们下面来分析
boolean added = commandQueue.offer(new AppendCommand(span));
if (!added) {
metrics.reporterDropped.inc(1);
}
}
public interface Command {
void execute() throws SenderException;
}
class AppendCommand implements Command {
private final JaegerSpan span;
public AppendCommand(JaegerSpan span) {
this.span = span;
}
@Override
public void execute() throws SenderException {
// 单纯地委托给send的append方法
sender.append(span);
}
}
/**
* 刷新命令
**/
class FlushCommand implements Command {
@Override
public void execute() throws SenderException {
int n = sender.flush();
metrics.reporterSuccess.inc(n);
}
}
/**
* 阻塞队列消费者,不断地从队列中获取命令,然后执行Command
**/
class QueueProcessor implements Runnable {
private boolean open = true;
@Override
public void run() {
while (open) {
try {
RemoteReporter.Command command = commandQueue.take();
try {
command.execute();
} catch (SenderException e) {
metrics.reporterFailure.inc(e.getDroppedSpanCount());
}
} catch (InterruptedException e) {
log.error("QueueProcessor error:", e);
// Do nothing, and try again on next span.
}
}
}
public void close() {
open = false;
}
}
}
我们可以看到,两种不同的Command实际上就是调用Sender的不同方法
- AppendCommand调用Sender的append方法
- FlushCommand调用Sender的flush方法
- 下面我们来看一下Sender的两个重要方法append和fush
public abstract class ThriftSender extends ThriftSenderBase implements Sender {
@Override
public int append(JaegerSpan span) throws SenderException {
if (process == null) {
process = new Process(span.getTracer().getServiceName());
process.setTags(JaegerThriftSpanConverter.buildTags(span.getTracer().tags()));
processBytesSize = calculateProcessSize(process);
byteBufferSize += processBytesSize;
}
io.jaegertracing.thriftjava.Span thriftSpan = JaegerThriftSpanConverter.convertSpan(span);
int spanSize = calculateSpanSize(thriftSpan);
// 单个Span过大就报错,并且丢弃这个Span
if (spanSize > getMaxSpanBytes()) {
throw new SenderException(String.format("ThriftSender received a span that was too large, size = %d, max = %d",
spanSize, getMaxSpanBytes()), null, 1);
}
byteBufferSize += spanSize;
// 如果当前的byteBufferSize 小于等于maxSpanBytes小,则直接加入缓冲区,然后更新一下byteBufferSize
// 如果当前的byteBufferSize 大于maxSpanBytes,则批量发送数据
if (byteBufferSize <= getMaxSpanBytes()) {
spanBuffer.add(thriftSpan);
if (byteBufferSize < getMaxSpanBytes()) {
return 0;
}
return flush();
}
int n;
try {
n = flush();
} catch (SenderException e) {
// +1 for the span not submitted in the buffer above
throw new SenderException(e.getMessage(), e.getCause(), e.getDroppedSpanCount() + 1);
}
spanBuffer.add(thriftSpan);
byteBufferSize = processBytesSize + spanSize;
return n;
}
@Override
public int flush() throws SenderException {
if (spanBuffer.isEmpty()) {
return 0;
}
int n = spanBuffer.size();
try {
// 抽象方法,由具体的协议发送者实现(如udp,Http)
send(process, spanBuffer);
} catch (SenderException e) {
throw new SenderException("Failed to flush spans.", e, n);
} finally {
// 发送完之后清空缓存区和重置缓冲区大小
spanBuffer.clear();
byteBufferSize = processBytesSize;
}
return n;
}
}
从Sender的框架实现看,如果在发送的过程报错了,也不会重试的。
从Jaeger的实现来看,到处都对Span充斥着冷酷无情啊,能丢就丢,毫不犹豫。其实Span也不能怪别人,因为从它出生就被挂上了可丢的标签了。估计也只有日志这个哥们跟它是难兄难弟了,都是可丢弃的。
3."安全"关闭
前面我们讲到阻塞队列中的Command其实有三种。第三种其实是为平滑停机准备的。第三种Command代码如下
class CloseCommand implements Command {
@Override
public void execute() throws SenderException {
queueProcessor.close();
}
}
class QueueProcessor implements Runnable {
private boolean open = true;
@Override
public void run() {
while (open) {
try {
// 执行命令
}
}
public void close() {
open = false;
}
}
其实很简单,就是一旦要关闭,就直接不从队列中拿数据了。那队列中的数据怎们办?怎们办,丢啊。
4.总结
从源代码的分析过程中,大家应该感觉到了,各个Tracer组件对Span是多么的无情啊。我们再回过头来,看一下需求
- 占用的资源不能太多。这其中包括线程资源,内存资源等。
主要占用两个线程资源,以及一个固定大小的队列内存资源 - 可以定时将内存中的数据保存起来。
后台启动Timer定时刷新 - 可以批量保存数据,提升性能。
Sender中缓冲区,可以批量发送数据 - 参数可配置化
队列大小以及刷新间隔可以配置 - 最重要的一点,无论如何不能影响主业务。
采用异步队列,异步线程的方式来保证性能以及不影响业务。甚至可以使用UDPSender来保证即使服务端宕机了也不会影响客户端