前言:最近正在拜读Toby Segaran先生写的集体智慧编程,首先感谢Toby Segaran先生将知识以书本的方式传播给大家,同时也感谢莫映和王开福先生对此书的翻译,谢谢各位的不辞辛苦。首先在写随笔之前,跟各位分享一下我的编程环境:win7系统,python版本是2.7.10,开发环境我选择的是pycharm程序。本书的第一章为集体智慧导言,主要介绍的何为集体智慧和机器学习的相关概念和其局限性,以及与机器学习相关的例子和应用场景。下面开始机器学习第二章--提供推荐的相关内容。
本章主要内容:如何根据群体偏好来为人们提供推荐。
1、协作性过滤
概述:协作型过滤算法通常的做法是对一大群人进行搜索,并从中找出与我们品味相近的一小群人。
思想:对这些人所偏爱的其他内容进行考察,并将他们组合起来构造出一个经过排名的推荐列表。
2、搜集偏好
构建数据集:在python中使用嵌套的字典来构建需要的数据集(新建名为recommendations.py的文件,新建chapter2_test.py用来运行命令):

将数据集写入到该文件中:
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
其中包括每位影评人对某一给定影片的喜爱程度
在chapter2_test.py中输入下列命令:
from recommendations import critics
print critics['Lisa Rose']['Lady in the Water']
critics['Toby']['Snakes on a Plane'] = 4.5
print critics['Toby']
来对数据集进行查看和修改,结果如下:
3、寻找相似的用户
本节用两种相似度评价方法对数据的相似对进行度量:欧几里得距离和皮尔逊相关度
3.1 欧几里得距离评价
欧几里得距离代码如下:
#返回一个有关person1与person2的基于距离的相似度评价
def sim_distance(prefs,person1,persion2):
#得到shared_items的列表
si = {}
for item in prefs[person1]:
if item in prefs[persion2]:
si[item] = 1
#如果两者没有共同之处,则返回0
if len(si) == 0: return 0
#计算所有差值的平方和
sum_of_squares = sum([pow(prefs[person1][item]-prefs[persion2][item],2) for item in prefs[person1] if item in prefs[persion2]])
#返回(距离+1)的倒数
return 1/(1+sqrt(sum_of_squares))
在chapter2_test.py中输入如下命令:
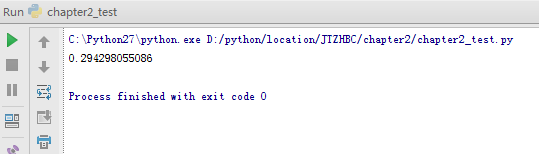
#计算critics数据集中Lisa Rose 和Gene Seymour两个用户的距离评价
print recommendations.sim_distance(critics,'Lisa Rose','Gene Seymour')
结果如下:
3.2 皮尔逊相关度评价
优点:修正了“夸大分值”的情况,如果某人总是倾向于给出比另一个人更高的分值,而两者的分之只差又始终保持一致,则他们依然可能会存在很好的相关性。
代码如下:
#返回p1和p2的皮尔逊相关系数
def sim_pearson(prefs,p1,p2):
#得到双方都曾评价过的物品列表
si = {}
for item in prefs[p1]:
if item in prefs[p2]:
si[item] = 1
#得到列表元素的个数
n = len(si)
#如果两者没有共同的物品,则返回1
if n ==0 :
return 1
#对所有偏好求和
sum1 = sum([prefs[p1][it] for it in si])
sum2 = sum([prefs[p2][it] for it in si])
#求平方和
sum1Sq = sum([pow(prefs[p1][it],2) for it in si])
sum2Sq = sum([pow(prefs[p2][it],2) for it in si])
#求乘积之和
pSum = sum([prefs[p1][it]*prefs[p2][it] for it in si])
#求皮尔逊评价值
num = pSum-(sum1*sum2)/n
den = sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
#如果分母为0则返回0
if den == 0 :
return 0
r = num/den
#返回皮尔逊相关系数
return r
在chapter2_test.py中输入如下命令:
print recommendations.sim_pearson(critics,'Lisa Rose','Gene Seymour')
计算出Lisa Rose和Gene Seymour相关系数如下:

4、为评论者打分
根据上述的对两个人进行比较的函数,下面根据指定人员对每个人进行打分,找出最接近的匹配结果。代码如下:
#从反应偏好的字典中返回最为匹配者
#返回结果的个数和相似度函数均为可选参数
def topMatches(prefs,person,n=5,similarity = sim_pearson):
scores = [(similarity(prefs,person,other),other) for other in prefs if other != person]
#对列表进行排序,评价值最高者排在最前面
scores.sort()
scores.reverse()
return scores[0:n]
调用改方法(chapter2_test),得到关于Toby及其相似度评价值的列表:
print recommendations.topMatches(critics,'Toby',n=3)
结果如下:
小结:
上述操作给出了数据集、两种相似度评价方法和利用相似度评价方法为评价者打分的相关代码和部分操作结果,下节将介绍推荐物品的相关代码和操作。如上述内容有错误和不足的地方请大家能够指出,谢谢!~