【pandas】[5] 数据行列转置,数据透视(stack,unstack,pviot,pviot_table)
作者:lianghc
在逛CSDN论坛时遇到这样一个问题:
下列代码中srcdf和desdf都是Pandas的DataFrame对象,需要将srcdf转换为desdf,也就是根据列中的值拓展新的列,关系数据库报表中常见的需求,请问用DataFrame要如何实现?
print(srcdf)
姓名 性别 科目 分数
编号
0 刘玄德 男 语文 98
1 刘玄德 男 数学 60
2 刘玄德 男 体育 50
3 关云长 男 语文 60
4 关云长 男 数学 60
5 关云长 男 体育 100
[6 rows x 4 columns]
print(desdf)
姓名 性别 语文 数学 体育 平均分
编号
0 刘玄德 男 98 60 50 66.666667
1 关云长 男 60 60 100 73.333333
[2 rows x 6 columns]
经过分析,发现实际是将那么分组,将科目展开,即《利用pandas进行数据分析》第七章 数据转换下的将‘长格式’转换为‘宽格式’ 问题。论坛里已经有一种解决办法了:
In [148]: from pandas import Series,DataFrame
...: a=[['刘玄德','男','语文',98.],['刘玄德','男','体育',60.],['关云长','男','数学',60.],['关云长','男','语文',100.]]
...: af=DataFrame(a,columns=['name','sex','course','score'])
In [149]: af
Out[149]:
name sex course score
0 刘玄德 男 语文 98
1 刘玄德 男 体育 60
2 关云长 男 数学 60
3 关云长 男 语文 100
In [150]: af.set_index(['name','sex','course'],inplace='TRUE')
In [151]: af
Out[151]:
score
name sex course
刘玄德 男 语文 98
体育 60
关云长 男 数学 60
语文 100
In [152]: t1=af.unstack(level=2)
In [153]: t1
Out[153]:
score
course 体育 数学 语文
name sex
关云长 男 NaN 60 100
刘玄德 男 60 NaN 98
In [154]: t2=t1.mean(axis=1,skipna=True)
In [155]: t2
Out[155]:
name sex
关云长 男 80
刘玄德 男 79
dtype: float64
In [156]: t1['平均分']=t2
In [157]: t1
Out[157]:
score 平均分
course 体育 数学 语文
name sex
关云长 男 NaN 60 100 80
刘玄德 男 60 NaN 98 79
In [158]: t1.fillna(0)
Out[158]:
score 平均分
course 体育 数学 语文
name sex
关云长 男 0 60 100 80
刘玄德 男 60 0 98 79首先使用set_index 重建索引,这个函数很厉害,实际上是做了分组(groupby)和重建索引的工作。然后用unstack将行转换成列,最后算平均数,然后组合到一起。这里关键用到set_index(),unstack()。默认情况下,unstack的操作就是最内层的(这里就是level=2),除了传统分级编号,也可以用名称对其unstack。如果数据在分组中找不到的话会引入NaN。
下面我尝试用pivot和pivot_table解这个问题:
#解法2:
In [126]: a=[['刘玄德','男','语文',98.],['刘玄德','男','体育',60.],['关云长','男','数学',60.],['关云长','男','语文',100.]]
...: af=DataFrame(a,columns=['name','sex','course','score'])
In [127]: af2=af.pivot('name','course','score') #使用pviot
In [128]: af2['avg']=af2.mean(axis=1)
In [129]: af2.fillna(0)
Out[129]:
course 体育 数学 语文 avg
name
关云长 0 60 100 80
刘玄德 60 0 98 79
In [130]: af2
Out[130]:
course 体育 数学 语文 avg
name
关云长 NaN 60 100 80
刘玄德 60 NaN 98 79
In [131]: af2[af2.isnull()]=0
In [132]: af2
Out[132]:
course 体育 数学 语文 avg
name
关云长 0 60 100 80
刘玄德 60 0 98 79pivot的前两个参数值分别作用于行和列索引,最后一个参数值则是用于填充DaraFrame的数据列的列名。在《利用pandas进行数据分析》第七章 数据转换下的将‘长格式’转换为‘宽格式’ 中作者一语道破了pivot和上面做法的区别:

接下来我尝试用更简单的方法去得到上面的结果,在《利用pandas进行数据分析》书中,第九章 讲了透视表和交叉表。
pivot_table 就是数据透视表,用过EXCEL数据透视表的对此肯定很熟悉。不过目前函数的参数有所更新,原来的rows变成了index,cols变成了columns。
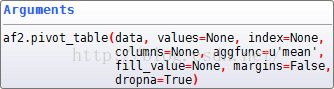
#解法3:
af.pivot_table('score',index='name',columns='course',aggfunc='mean',margins=True,fill_value=0)
Out[141]:
course 体育 数学 语文 All
name
关云长 0 60 100 80.0
刘玄德 60 0 98 79.0
All 60 60 99 79.5