Flink实战(四) - DataSet API编程
0 相关源码
1 你将学到
◆ DataSet API开发概述
◆ 计数器
◆ DataSource
◆ 分布式缓存
◆ Transformation
◆ Sink
2 Data Set API 简介
Flink中的DataSet程序是实现数据集转换(例如,过滤,映射,连接,分组)的常规程序.
最初从某些Source源创建数据集(例如,通过读取文件或从本地集合创建)
结果通过sink返回,接收器可以例如将数据写入(分布式)文件或标准输出(例如命令行终端)
 Flink程序可以在各种环境中运行,单机运行或嵌入其他程序中
Flink程序可以在各种环境中运行,单机运行或嵌入其他程序中
执行可以在本地JVM中执行,也可以在集群机器上执行.
- 有关Flink API基本概念的介绍,请参阅本系列的上一篇
Flink实战(三) - 编程模型及核心概念
为了创建自己的Flink DataSet程序,鼓励从Flink程序的解剖开始,逐步添加自己的转换!
3 测试环境
4 Data Sources简介
数据源创建初始数据集,例如来自文件或Java集合。创建数据集的一般机制是在InputFormat后面抽象的
Flink附带了几种内置格式,可以从通用文件格式创建数据集。其中许多都在ExecutionEnvironment上有快捷方法。
4.1 基于文件
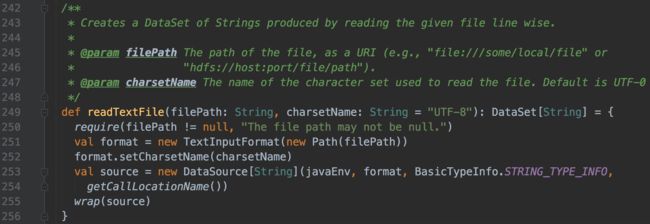
- readTextFile(path)/ TextInputFormat
按行读取文件并将它们作为字符串返回 - readTextFileWithValue(path)/ TextValueInputFormat
按行读取文件并将它们作为StringValues返回。 StringValues是可变字符串 - readCsvFile(path)/ CsvInputFormat
解析逗号(或其他字符)分隔字段的文件。返回元组,案例类对象或POJO的DataSet。支持基本的java类型及其Value对应的字段类型 - readFileOfPrimitives(path,delimiter)/ PrimitiveInputFormat
使用给定的分隔符解析新行(或其他char序列)分隔的原始数据类型(如String或Integer)的文件 - readSequenceFile(Key,Value,path)/ SequenceFileInputFormat
创建JobConf并从类型为SequenceFileInputFormat,Key class和Value类的指定路径中读取文件,并将它们作为Tuple2返回。
4.2 基于集合
- fromCollection(Iterable) - 从Iterable创建数据集。 Iterable返回的所有元素必须属于同一类型
- fromCollection(Iterator) - 从迭代器创建数据集。该类指定迭代器返回的元素的数据类型
- fromElements(elements:_ *) - 根据给定的对象序列创建数据集。所有对象必须属于同一类型
- fromParallelCollection(SplittableIterator) - 并行地从迭代器创建数据集。该类指定迭代器返回的元素的数据类型
- generateSequence(from,to) - 并行生成给定时间间隔内的数字序列。
4.3 通用
- readFile(inputFormat,path)/ FileInputFormat
接受文件输入格式 - createInput(inputFormat)/ InputFormat
接受通用输入格式
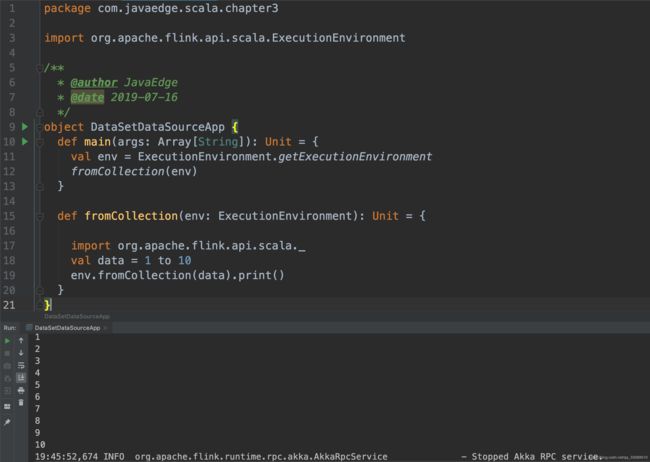
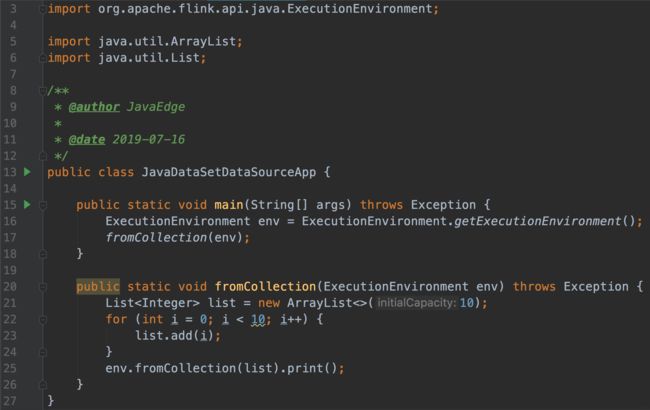
5 从集合创建DataSet
5.1 Scala实现
5.2 Java实现
6 从文件/文件夹创建DataSet
6.1 Scala实现
文件
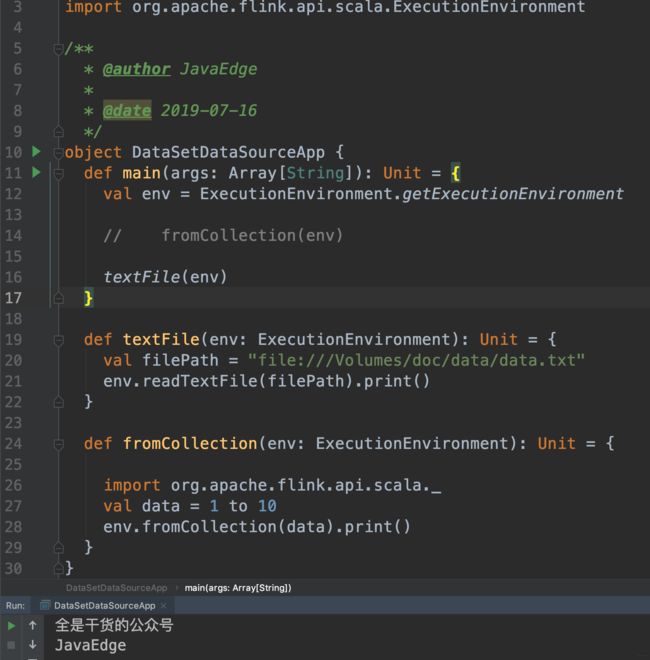
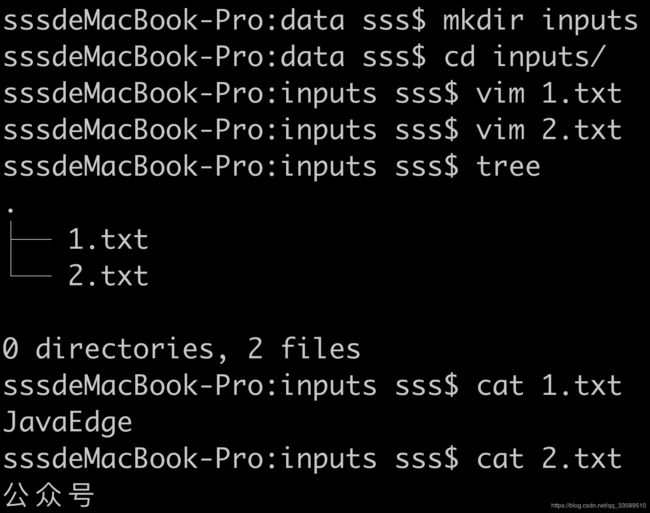
文件夹

Java实现
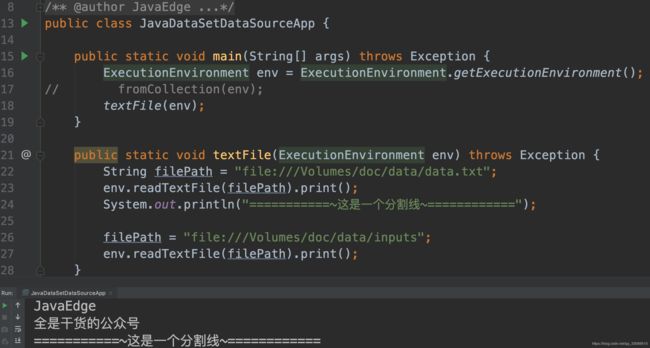

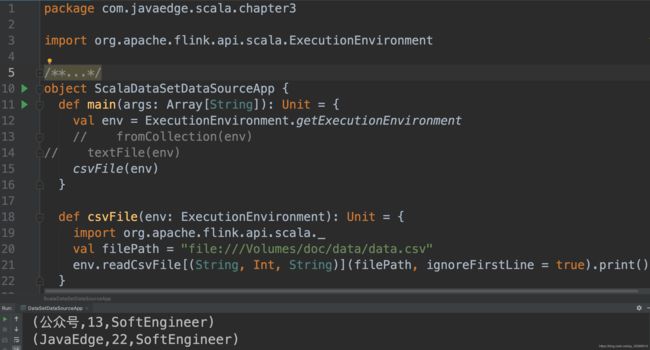
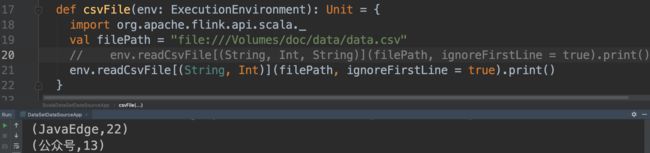
7 从csv文件创建Dataset

7.1 Scala实现
- 注意忽略第一行
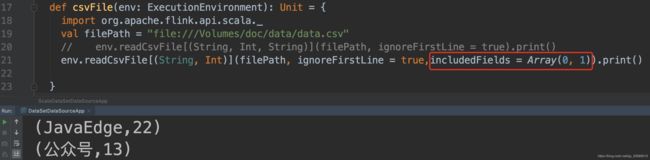
- includedFields参数使用
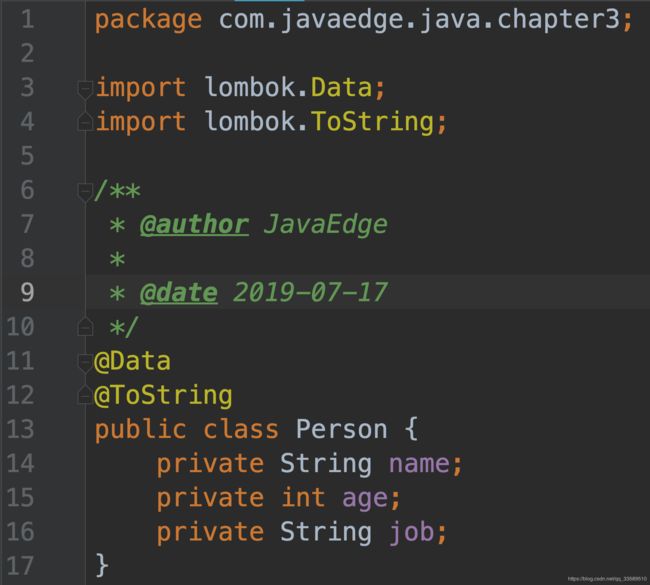
- 定义一个POJO

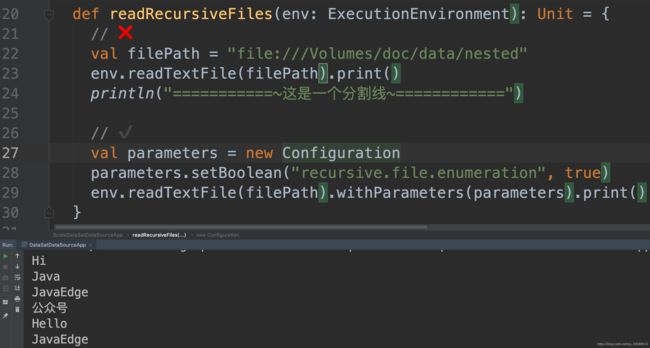
8 从递归文件夹的内容创建DataSet
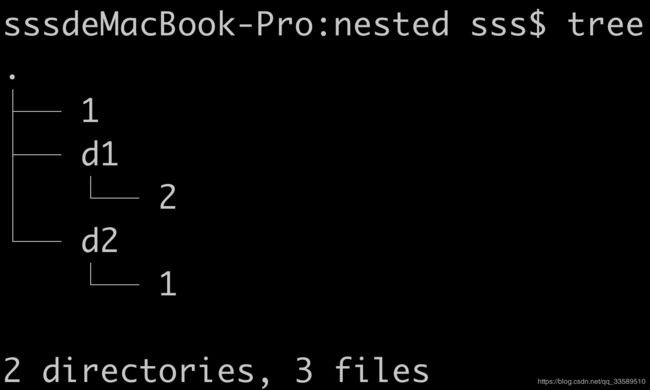
8.1 Scala实现
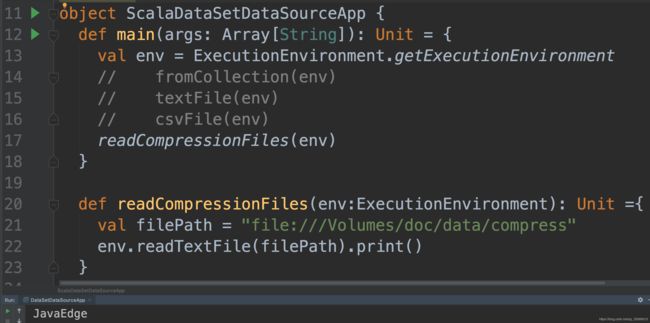
9从压缩文件中创建DataSet
Flink目前支持输入文件的透明解压缩,如果它们标有适当的文件扩展名。 特别是,这意味着不需要进一步配置输入格式,并且任何FileInputFormat都支持压缩,包括自定义输入格式。
压缩文件可能无法并行读取,从而影响作业可伸缩性。
下表列出了当前支持的压缩方法

9.1 Scala实现
10 Transformation
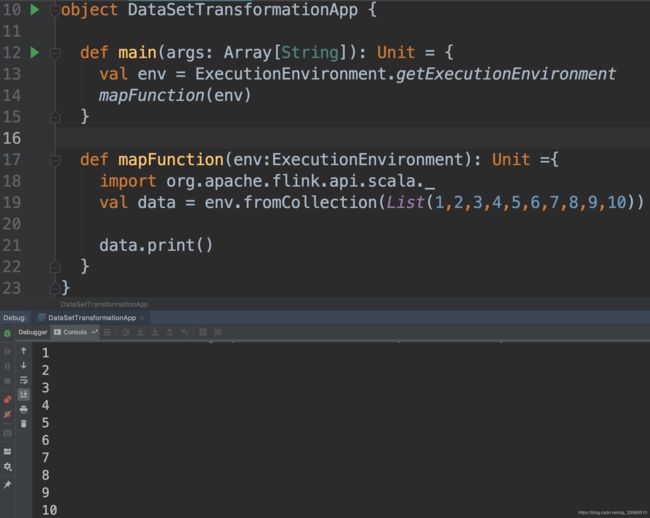
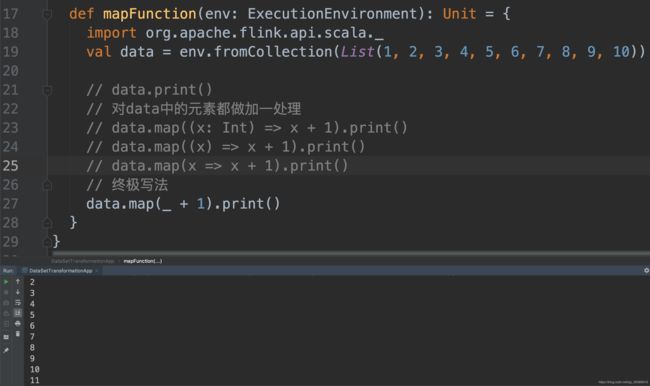
10.1 map
Map转换在DataSet的每个元素上应用用户定义的map函数。 它实现了一对一的映射,也就是说,函数必须返回一个元素。
以下代码将Integer对的DataSet转换为Integers的DataSet:
Scala实现
Java实现

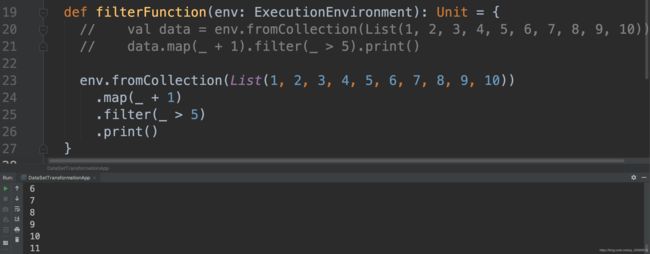
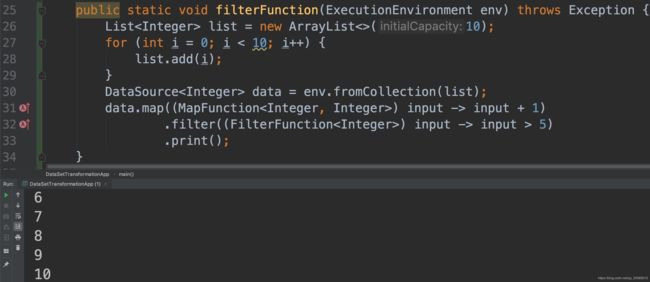
10.2 filter
Scala实现
Java实现
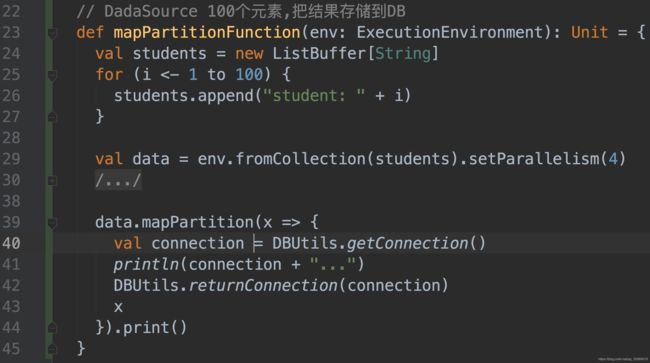
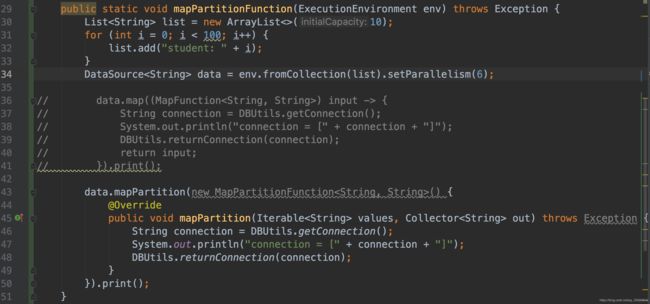
10.3 mapPartition
MapPartition在单个函数调用中转换并行分区。 map-partition函数将分区作为Iterable获取,并且可以生成任意数量的结果值。 每个分区中的元素数量取决于并行度和先前的操作。
Scala实现
Java实现
10.4 first
Scala实现
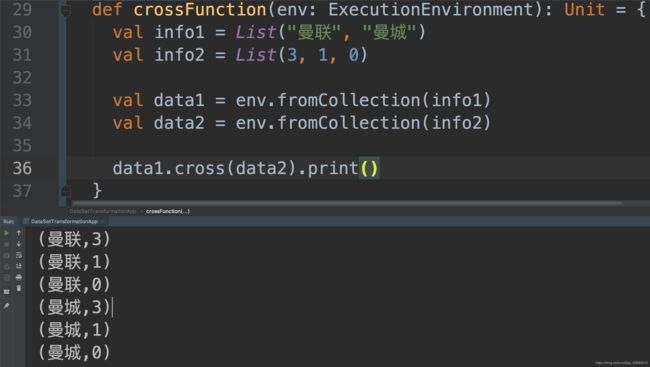
10.5 Cross
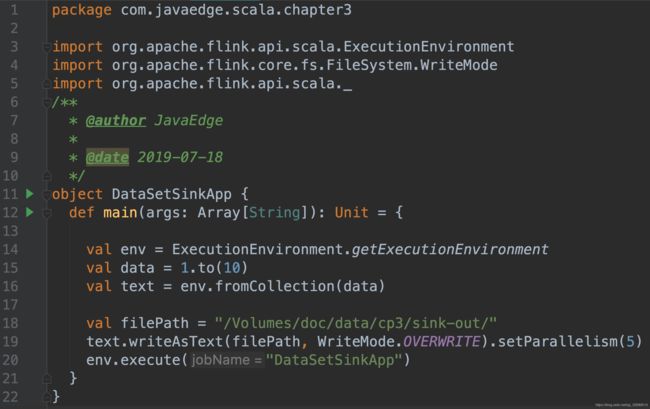
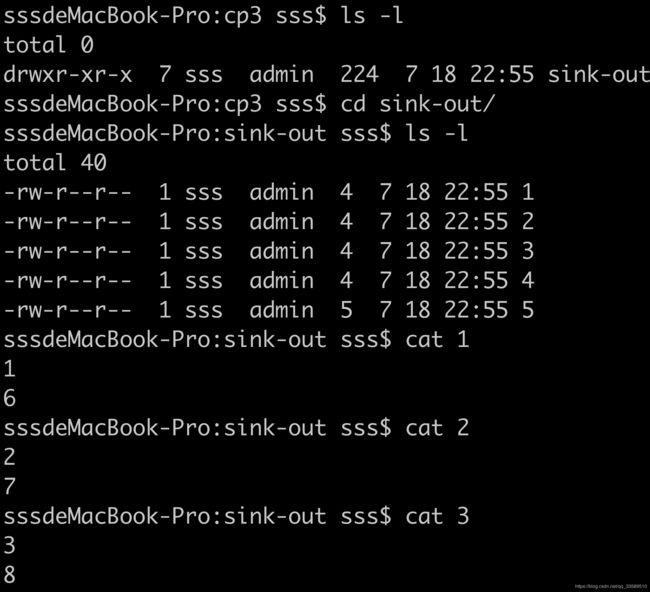
11 Data Sinks
11.1 Java描述
Data Sinks使用DataSet并用于存储或返回它们
使用OutputFormat描述数据接收器操作
Flink带有各种内置输出格式,这些格式封装在DataSet上的操作后面:
- writeAsText()/ TextOutputFormat
将元素按行顺序写入字符串。通过调用每个元素的toString()方法获得字符串。 - writeAsFormattedText()/ TextOutputFormat
按字符串顺序写入元素。通过为每个元素调用用户定义的format()方法来获取字符串。 - writeAsCsv(…)/ CsvOutputFormat
将元组写为逗号分隔值文件。行和字段分隔符是可配置的。每个字段的值来自对象的toString()方法。 - print()/ printToErr()/ print(String msg)/ printToErr(String msg)
打印标准输出/标准错误流上每个元素的toString()值。可选地,可以提供前缀(msg),其前缀为输出。这有助于区分不同的打印调用。如果并行度大于1,则输出也将以生成输出的任务的标识符为前缀。 - write()/ FileOutputFormat
自定义文件输出的方法和基类。支持自定义对象到字节的转换。 - output()/ OutputFormat
最通用的输出方法,用于非基于文件的数据接收器(例如将结果存储在数据库中)。
可以将DataSet输入到多个操作。程序可以编写或打印数据集,同时对它们执行其他转换。
例子
标准数据接收方法:
// text data
DataSet textData = // [...]
// write DataSet to a file on the local file system
textData.writeAsText("file:///my/result/on/localFS");
// write DataSet to a file on a HDFS with a namenode running at nnHost:nnPort
textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");
// write DataSet to a file and overwrite the file if it exists
textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);
// tuples as lines with pipe as the separator "a|b|c"
DataSet> values = // [...]
values.writeAsCsv("file:///path/to/the/result/file", "\n", "|");
// this writes tuples in the text formatting "(a, b, c)", rather than as CSV lines
values.writeAsText("file:///path/to/the/result/file");
// this writes values as strings using a user-defined TextFormatter object
values.writeAsFormattedText("file:///path/to/the/result/file",
new TextFormatter>() {
public String format (Tuple2 value) {
return value.f1 + " - " + value.f0;
}
});
使用自定义输出格式:
DataSet> myResult = [...]
// write Tuple DataSet to a relational database
myResult.output(
// build and configure OutputFormat
JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
本地排序输出
可以使用元组字段位置或字段表达式以指定顺序在指定字段上对数据接收器的输出进行本地排序。 这适用于每种输出格式。
以下示例显示如何使用此功能:
DataSet> tData = // [...]
DataSet> pData = // [...]
DataSet sData = // [...]
// sort output on String field in ascending order
tData.sortPartition(1, Order.ASCENDING).print();
// sort output on Double field in descending and Integer field in ascending order
tData.sortPartition(2, Order.DESCENDING).sortPartition(0, Order.ASCENDING).print();
// sort output on the "author" field of nested BookPojo in descending order
pData.sortPartition("f0.author", Order.DESCENDING).writeAsText(...);
// sort output on the full tuple in ascending order
tData.sortPartition("*", Order.ASCENDING).writeAsCsv(...);
// sort atomic type (String) output in descending order
sData.sortPartition("*", Order.DESCENDING).writeAsText(...);
参考
DataSet Transformations