ubuntu16.04 ananconda tensorflow
ABSTRACT
descripe :
date : 2018.06.06
platform : NVIDIA GeForce 1080Ti
version : ubuntu - 16.04 LTS(自带的是python3.5,所以在安装tensorflow时,需要注意版本)
NVIDIA-driver - 384.13
CUDA - 9.0
cuDNN - 7.1.2
tensorflow - 1.8
==========================
首先在search your computer中输入upd,进入software&updates,更改下载源(推荐清华或阿里作为下载源。)
首先sudo apt update,然后sudo apt upgrade
下载synaptic (新立得 ——————1款好用的软件包管理器)
==========================
STEP 1 : install nvidia driver
reference : https://blog.csdn.net/u012759136/article/details/53355781
修改驱动文件权限
sudo chmod 777 NVIDIA-Linux-x86_64-410.78.run
1. sudo apt-get remove –purge nvidia*
2. sudo vim /etc/modprobe.d/blacklist.conf (sudo apt-get install vim-gtk)
3. add "blacklist nouveau" at the end of file
4. sudo update-initramfs -u
5. sudo reboot
6. Ctrl+Alt+F1
7. lsmod | grep nouveau
8. sudo /etc/init.d/lightdm stop
9. cd ${nvidia_driver_path}
10. sudo sh NVIDIA-Linux-x86_64-384.130.run –no-x-check –no-nouveau-check –no-opengl-files
安装(注意 参数)
sudo ./NVIDIA-Linux-x86_64-384.13.run –no-opengl-files
–no-opengl-files 只安装驱动文件,不安装OpenGL文件。这个参数最重要
–no-x-check 安装驱动时不检查X服务
–no-nouveau-check 安装驱动时不检查nouveau
后面两个参数可不加。
在安装驱动的时候,有一步问你”Would you like to run the nvidia-xconfig utility to automatically update your X configuration file…”什么的,选择 No
11. sudo reboot
Please run the commands, if the desktop can not login after reboot.
1. cd /usr/share/X11/xorg.conf.d/
2. sudo mv nvidia-drm-outputclass.conf nvidia-drm-outputclass.conf.bak
3. sudo reboot
==========================
STEP 2: install CUDA
1. Download CUDA 9.0 at https://developer.nvidia.com/cuda-90-download-archive
select Linux, x86_64, Ubuntu, 16.04, runfile(local) and download base installer,(the download file name is "cuda_9.0.176_384.81_linux.run")
2. cd ${cuda_9.0_path}
3. sudo sh cuda_9.0.176_384.81_linux.run
sudo sh cuda_9.0.176.1_linux.run --override
~~~~~~~~~~~~~~~
Error: unsupported compiler: 7.3.0. Use --override to override this check.
Missing recommended library: libGLU.so
Missing recommended library: libX11.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Missing recommended library: libGL.so
Error: cannot find Toolkit in /usr/local/cuda-9.0
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installation Failed. Using unsupported Compiler.
Samples: Cannot find Toolkit in /usr/local/cuda-9.0
4. enter n, y, '\n', y, y, '\n' step by step, like this. ('\n' means enter)
有一个关键是会让你选择是否安装Graphics Driver for Linux-x86_64:XXXX版本,这个地方必须选择no!否则会覆盖之前的驱动。
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.0 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-9.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 9.0 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /home/ai_group ]:
Installing the CUDA Toolkit in /usr/local/cuda-9.0 ...
Missing recommended library: libGLU.so
Missing recommended library: libX11.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Missing recommended library: libGL.so
Installing the CUDA Samples in /home/ai_group ...
Copying samples to /home/ai_group/NVIDIA_CUDA-9.0_Samples now...
Finished copying samples.
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-9.0
Samples: Installed in /home/ai_group, but missing recommended libraries
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 9.0 functionality to work.
To install the driver using this installer, run the following command, replacing
sudo
Logfile is /tmp/cuda_install_3795.log
liuliu@liuliu:~/Downloads/install required package$ sudo sh cuda_9.0.176_384.81_linux.run -silent -driver
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~``
5.1 gedit ./.bashrc
install CUDA 的 5. gedit ./.bashrc,请注意bashrc文件在home路径下,所以需要进入home路径,打开bashrc文件进行编辑。
5.2 source ~/.bashrc
5.3 关闭终端,然后再重启一个新的终端,这一步很重要
6. add environment path at the end
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:/usr/local/cuda/extras/CPUTI/lib64
export CUDA_HOME=/usr/local/cuda-9.0/bin
export PATH=$PATH:$LD_LIBRARY_PATH:$CUDA_HOME
==========================
STEP 3: install cuDNN
1. Download cuDNN for CUDA 9.0 at https://developer.nvidia.com/rdp/cudnn-archive
下载解压文件那一项 :cuDNN v7.1.4 Library for Linux
cudnn-9.0-linux-x64-v7.5.0.56.tgz
2. Extract the cuDNN
3. cd ${cuDNN_extract_folder_path}
4. sudo cp ./include/cudnn.h /usr/local/cuda/include
5. sudo cp ./lib64/libcudnn* /usr/local/cuda/lib64
6. sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
==========================
STEP 4: install Anaconda (我安装的对应于python3.6,注意tensorflow对应python的版本)
1、先从官网https://www.anaconda.com/download/#linux或者https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/下载对应的anaconda版本
2、下载完成后进入下载目录执行以下语句
$ bash ./Anaconda3-5.2.0-Linux-x86_64.sh
#此处将文件名替换成你自己的文件名
3、接下来的安装提示按回车进入下一步,按q跳过License文档,最后输入yes确认
接下来让我们输入安装路径,没特殊情况直接回车默认路径就好
4、安装完成后程序提示我们是否把Anaconda3的binary路径加入到.bashrc,建议添加,这样以后python和ipython命令就会自动使用anaconda Python3.6环境了(全程Yes,默认安装在当前用户的home目录下,注意,最后一步,是问你要不要添加环境变量,默认是NO,最好选择YES.)
5、可以在终端输入$ conda list查看是否安装成功
=========================
sudo apt install python3-pip
sudo pip3 install tensorflow-gpu==1.11.0
=========================
STEP 5: 使用anaconda安装tensorflow
1、建立conda计算环境
conda create -n tensorflow python=3.6
过程中输入y继续进行
2、激活环境,使用 conda 安装 TensorFlow
source activate tensorflow
3、安装tensorflow
pip install --ignore-installed --upgrade https://mirrors.tuna.tsinghua.edu.cn/tensorflow/linux/gpu/tensorflow_gpu-1.5.0rc1-cp36-cp36m-linux_x86_64.whl
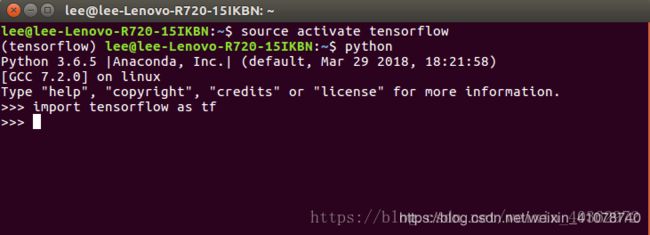
4、测试tensorflow
按照图中命令输入
=========================
STEP 6: pycharm安装
1、pycharm下载
https://www.jetbrains.com/pycharm/download/#section=linux
社区版对于我们这些学生大体够用,当然你也可以下载社区版,然后用学校邮箱进行注册,可免费使用
2、解压下载文件
进入下载目录,运行以下解压命令
tar -xzvf pycharm-professional-2018.1.tar.gz
解压后,会生成一个文件
这里写图片描述
3、进入文件bin目录,进行安装
cd pycharm-2018.1/bin
sh ./pycharm.sh
5、pycharm导入tensorflow
File->Settings->Project: 项目名->Project Interpreter
点击右上角齿轮图形
选择Conda Enviroment,再选择Existing enviroment
选择你的tensorflow下的python3.6,例如我的:/home/lee/anaconda3/envs/tensorflow/bin/python3.6
——————————————————————————————————
测试是否安装成功
import tensorflow as tf
hello=tf.constant('Hello, Tensorflow')
sess = tf.Session()
print(sess.run(hello))
--------------------------------------------------------------------------------------------
import tensorflow
报错:ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
解决方案:sudo ldconfig /usr/local/cuda-9.0/lib64
---------------------
=========================
STEP 7: tensorflow环境下安装python包
1、打开终端,激活tensorflow
source activate tensorflow
2、继续安装numpy、pandas、matplotlib,安装方法很简单
conda install numpy
过程中选择yes
=============================================
STEP 8: 使用conda安装opencv时,一定注意使用下述命令:
liuliu@liuliu:~$ conda install -c menpo opencv3
否则,Ubuntu 在conda 环境下使用cv2.imshow(...)出错,参考:https://blog.csdn.net/lsg_lsg_lsg/article/details/79898962)
================================================================
STEP 9: https://blog.csdn.net/weixin_40362972/article/details/79838662
八、mnist测试
1、下载mnist数据集
进入http://yann.lecun.com/exdb/mnist/,下载如下图四个文件
这里写图片描述
注意不要去解压下载过来的文件,然后将文件复制到你的python的Project的目录下
在pycharm输入以下代码进行测试
# load MNIST data
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# start tensorflow interactiveSession
import tensorflow as tf
sess = tf.InteractiveSession()
# weight initialization
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# convolution
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# pooling
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# Create the model
# placeholder
x = tf.placeholder("float", [None, 784])
y_ = tf.placeholder("float", [None, 10])
# variables
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# first convolutinal layer
w_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1, 28, 28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# second convolutional layer
w_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# densely connected layer
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
# dropout
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout layer
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2)
# train and evaluate the model
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
# train_step = tf.train.AdagradOptimizer(1e-4).minimize(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(1e-3).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, train accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 显存不足错误
# print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
a = 10
b = 50
sum = 0
for i in range(a):
testSet = mnist.test.next_batch(b)
c = accuracy.eval(feed_dict={x: testSet[0], y_: testSet[1], keep_prob: 1.0})
sum += c * b
#print("test accuracy %g" % c)
print("test accuracy %g" % (sum / (b * a)))
=================================================
anaconda安装opencv-python
在Linux下,配置Anaconda的环境变量,请参考我的另一篇文章。
以上工作都完成之后,接下来开始输入命令了。
conda install --channel https://conda.anaconda.org/menpo opencv3
如果不行试试这个
conda install -c https://conda.anaconda.org/menpo opencv3
楼主亲测,第一种方法就行得通。
接着就是等待安装了。Linux下询问yes/no的时候,输入yes。
记忆两个比较实用的conda的命令,安装和更新包:
conda install numpy=1.9.3
conda update numpy=1.9.3
========================
conda install -c menpo opencv最后测试一下,没问题。
import cv2
img = cv2.imread(r'F:\Pictures\tiger.jpg')
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()=======================================================================
pycharm 不同的project interpreter
https://www.cnblogs.com/amanda-x/p/7739467.html
Anaconda 是一个包含数据科学常用包的 Python 发行版本。它基于 conda ——一个包和环境管理器——衍生而来。你将使用 conda 创建环境,以便分隔使用不同 Python 版本和不同程序包的项目。你还将使用它在环境中安装、卸载和更新包。通过使用 Anaconda,处理数据的过程将更加愉快。
管理环境
你可以使用 conda 创建环境以隔离项目。要创建环境,请在终端中使用 conda create -n env_name list of packages。在这里,-n env_name 设置环境的名称(-n 是指名称),而 list of packages 是要安装在环境中的包的列表。例如,要创建名为 my_env 的环境并在其中安装 numpy,请键入 conda create -n my_env numpy。
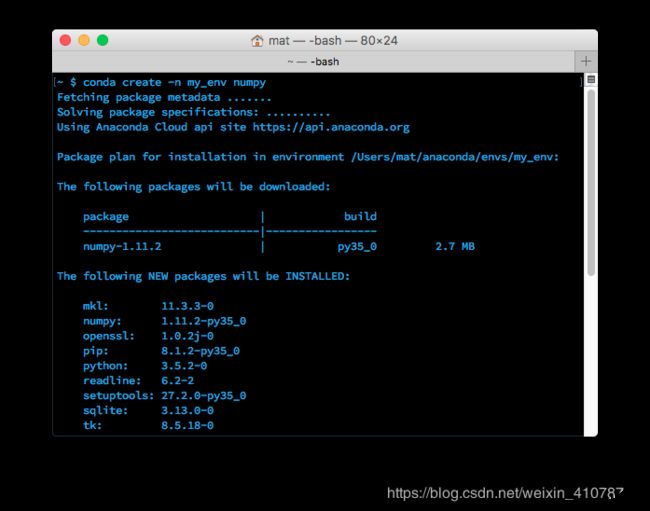
创建环境时,可以指定要安装在环境中的 Python 版本。这在你同时使用 Python 2.x 和 Python 3.x 中的代码时很有用。要创建具有特定 Python 版本的环境,请键入类似于 conda create -n py3 python=3 或 conda create -n py2 python=2 的命令。实际上,我在我的个人计算机上创建了这两个环境。我将它们用作与任何特定项目均无关的通用环境,以处理普通的工作(可轻松使用每个 Python 版本)。这些命令将分别安装 Python 3 和 Python 2 的最新版本。要安装特定版本(例如 Python 3.3),请使用 conda create -n py python=3.3。
进入环境
创建了环境后,在 OSX/Linux 上使用 source activate my_env 进入环境。在 Windows 上,请使用 activate my_env。
进入环境后,你会在终端提示符中看到环境名称,它类似于 (my_env) ~ $。环境中只安装了几个默认的包,以及你在创建它时安装的包。你可以使用 conda list 检查这一点。在环境中安装包的命令与前面一样:conda install package_name。不过,这次你安装的特定包仅在你进入环境后才可用。要离开环境,请键入 source deactivate(在 OSX/Linux 上)。在 Windows 上,请使用 deactivate。
保存和加载环境
共享环境这项功能确实很有用,它能让其他人安装你的代码中使用的所有包,并确保这些包的版本正确。你可以使用 conda env export > environment.yaml 将包保存为 YAML。命令的第一部分 conda env export 用于输出环境中的所有包的名称(包括 Python 版本)。
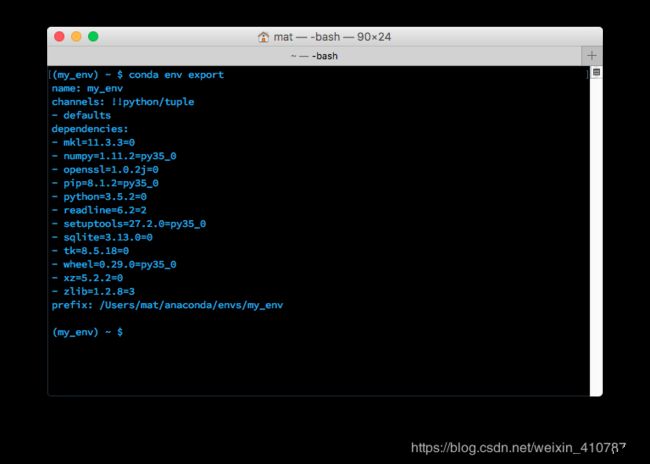
将导出的环境输出到终端中
上图中,你可以看到环境的名称和所有依赖项及其版本。导出命令的第二部分 > environment.yaml 将导出的文本写入到 YAML 文件 environment.yaml 中。现在可以共享此文件,而且其他人能够用于创建和你项目相同的环境。
要通过环境文件创建环境,请使用 conda env create -f environment.yaml。这会创建一个新环境,而且它具有同样的在 environment.yaml 中列出的库。
列出环境
如果忘记了环境的名称(我有时会这样),可以使用 conda env list 列出你创建的所有环境。你会看到环境的列表,而且你当前所在环境的旁边会有一个星号。默认的环境(即当你不在选定环境中时使用的环境)名为 root。
删除环境
如果你不再使用某些环境,可以使用 conda env remove -n env_name 删除指定的环境(在这里名为 env_name)。
使用环境
对我帮助很大的一点是,我的 Python 2 和 Python 3 具有独立的环境。我使用了 conda create -n py2 python=2 和 conda create -n py3 python=3 创建两个独立的环境,即 py2 和 py3。现在,我的每个 Python 版本都有一个通用环境。在所有这些环境中,我都安装了大多数标准的数据科学包(numpy、scipy、pandas 等)。
我还发现,为我从事的每个项目创建环境很有用。这对于与数据不相关的项目(例如使用 Flask 开发的 Web 应用)也很有用。例如,我为我的个人博客(使用 Pelican)创建了一个环境。
共享环境
在 GitHub 上共享代码时,最好同样创建环境文件并将其包括在代码库中。这能让其他人更轻松地安装你的代码的所有依赖项。对于不使用 conda 的用户,我通常还会使用 pip freeze(在此处了解详情)将一个 pip requirements.txt 文件导出并包括在其中。
========================================================================
Linux下利用Anaconda执行conda install出现PackageNotFoundError的解决方案
https://blog.csdn.net/ksws0292756/article/details/79192268
anaconda search -t conda 要找的包然后在找到自己需要的包和相应链接,安装即可
如果,上述链接没有自己需要的包,那么本地下载安装包,然后本地安装
使用source activate 环境名 命令进入虚拟环境,然后使用pip install 文件包所在的位置和文件名
例如:(tensorflow) liuliu@liuliu:~$ pip install /home/liuliu/Downloads/Keras-2.0.3.tar.gz
在conda环境中使用pip安装的包,在该conda环境下,使用conda list可以查看到,但是在pycharm的setting->project interpreter中是查看不到的,但是不影响使用。