is 和 ==什么区别?
在Python中 is 是用来判断两个对象的内存地址是否一样,而 == 号是判断两个对象(a he b)中的内容是否一样。也就是说is是用来比较房间的门牌号,而==是用来比较房间中的内容
先看下面的内存示意图和一些代码运行的图


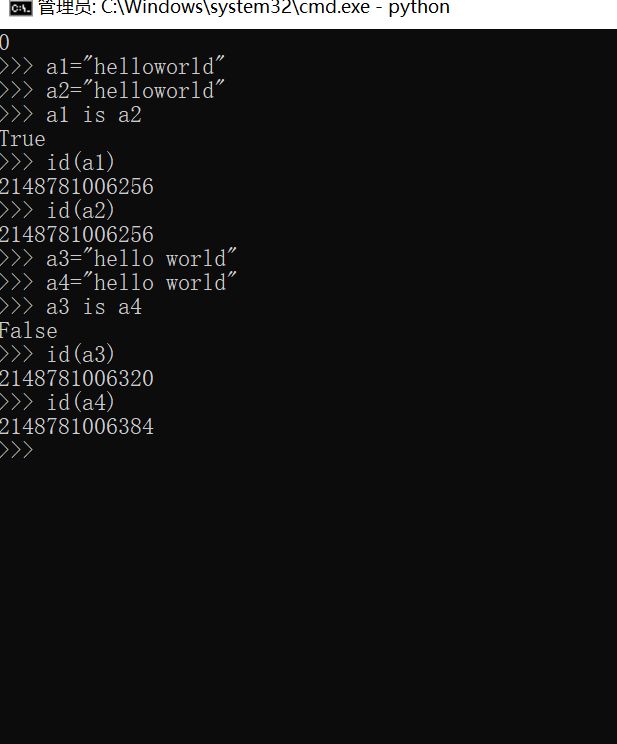
总结
• 小整数[-5,257)共用对象,常驻内存
• 单个字符共用对象,常驻内存
• 单个单词,不可修改,默认开启intern机制,共用对象,引用计数为0,则销毁
• 字符串(含有空格),不可修改,没开启intern机制,不共用对象,引用计数为0,销毁
• 大整数不共用内存,引用计数为0,销毁
数值类型和字符串类型在 Python 中都是不可变的,这意味着你无法修改这个对象的值,每次对变量的修改,实际上是创建一个新的对象
copy模块
import copy
a1=[1,2,3,4]
a2=copy.copy(a1)
a1= a2
True
a1 is a2
False
这个是浅拷贝会拷贝对象最上面的一层这里可以看到 a1和a2的门牌号是不一样的,浅拷贝是有弊端的,也就是只会拷贝顶层而对象中的深层是无法拷贝的,比如 列表对象里套了一个或者多个列表对象
import copy
a1=[1,2,3,4]
a2=[1,3,5,a1]
a3=copy.copy(a2)
a2[3][0]=12
a2
[1,3,5,[12,2,3,4]]
a3
[1,3,5,[12,2,3,4]]
从上面的例子可以看出浅拷贝是藕断丝连的并不能解决深层对象的拷贝问题,这里就要用到深拷贝(deepcopy)
import copy
a1=[1,2,3,4]
a2=[1,3,5,a1]
a3=copy.deepcopy(a2)
a2[3][0]=12
a2
[1,3,5,[12,2,3,4]]
a3
[1,3,5,[1,2,3,4]]
问题完美解决,当然有人问既然有了深拷贝为什么还要有浅拷贝,有钱(浅)嘛大家都喜欢,所以就追加了一个浅拷贝的方法,当然这是开玩笑的,因为深拷贝是递归拷贝在忽略对象套对象的情况下,对大量数据拷贝时速度很慢,效率低递归的通病。
python 的垃圾回收(gc)机制(Garbage collection)(选修,纯理论)
python采用了和C#、Java一样的手段,专业的垃圾回收机制,而不是c和c++ 用户自己管理内存的方式,关于自由管理大家可以百度一下。
python采用的垃圾回收机制是引用计数为主,标记-清除和分代收集为辅。
Python中的所有都是,他们的核心是一个结构体:PyObject
也就是每一个对象都有PyObject这个结构体
//我的python版本是cpython
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
其中PyObject就是每个对象的引用计数。
在创建一个对象的时候PyObject就会生成一个非零的自然数
Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> def test():
... pass
...
>>> d= test
>>> del test
>>> d
>>> test()
Traceback (most recent call last):
File "", line 1, in
NameError: name 'test' is not defined
>>>
从上面的代码可以看出d =test 创建了一个新的对象,在原有的对象的PyObject加一 ,
在删除这个对象的时候 PyObject减一
而且这两个对象共用一个 PyObject
>>> a= 110
>>> sys.getrefcount(a)
3
>>> b = a
>>> sys.getrefcount(a)
4
>>> sys.getrefcount(b)
4
>>> del b
>>> sys.getrefcount(a)
3
>>> b =a
>>> sys.getrefcount(a)
4
>>> sys.getrefcount(b)
4
>>> del a
>>> sys.getrefcount(b)
3
>>> b
110
>>> a = 300
>>> sys.getrefcount(a)
2
>>> b =a
>>> sys.getrefcount(b)
3
>>> sys.getrefcount(a)
3
>>> del a
>>> sys.getrefcount(b)
2
>>> sys.getrefcount(a)
Traceback (most recent call last):
File "", line 1, in
NameError: name 'a' is not defined
>>>
大整数池和小整数池我都做了测试。
当del 的时候 就会PyObject置零,此时gc就会回收这块内存。
引用的计数的优点就是:
• 简单
• 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时 机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用的计数的缺点就是:
• 维护引用计数耗费资源
• 循环引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
如果对于第一个还能忍受,那么循环引用就是致命的。循环引用导致内存泄露,注定python还将引入新的回收机制。(标记清除和分代收集)
文章的就写到这里......关于标记清除,分代我的理解也不是太深,也不在这里误人子弟。
晚安!